


缓存实现万级并发扣减
架构是面向业务功能、成本、实现难度、时间等因素的取舍,而不是绝对地追求高性能、高并发及高可用等非功能性指标。
纯数据库的方案虽然避免了超卖与少卖的情况,但因采用了事务的方式保证一致性和原子性,所以在 SKU 数量较多时性能下降较明显。
扣减只需要保证原子性即可,并不需要数据库提供的 ACID
在提升性能方面最简单、最快速的方案便是升级硬件。
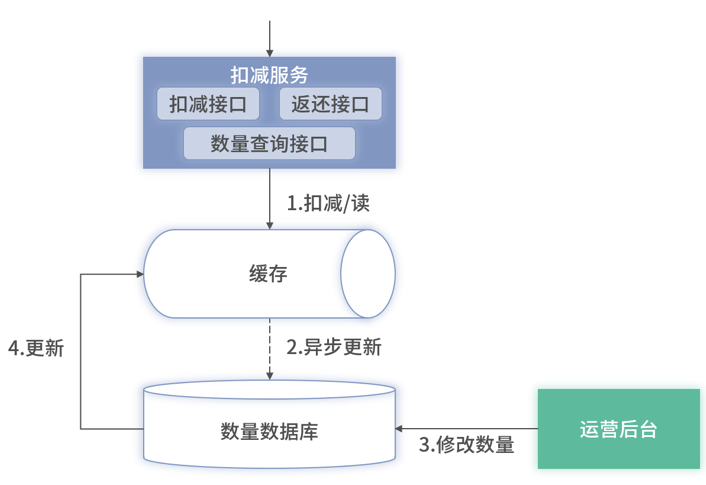
key为:sku_stock_{sku}。前缀sku_stock是固定不变,所有以此为前缀的均表示是库存。{sku}是占位符,在实际存储时被具体的skuid替代。
value:库存数量。当前此key表示的sku剩余可购买的数量。
对于 Redis 中存储的流水表采用 hash 结构,即 key + hashField + hashValue 的形式。
key:sx_{sku}。前缀sx_是按上述缩短的形式设计的,只起到了区分的作用。{sku}为占位符
hashField:此次扣减流水编号。
hashValue: 此次扣减的数量
lua 是一个类似 JavaScript、Shell 等的解释性语言,它可以完成 Redis 已有命令不支持的功能。用户在编写完 lua 脚本之后,将此脚本上传至 Redis 服务端,服务端会返回一个标识码代表此脚本。在实际执行具体请求时,将数据和此标识码发送至 Redis 即可。Redis 会和执行普通命令一样,采用单线程执行此 lua 脚本和对应数据。
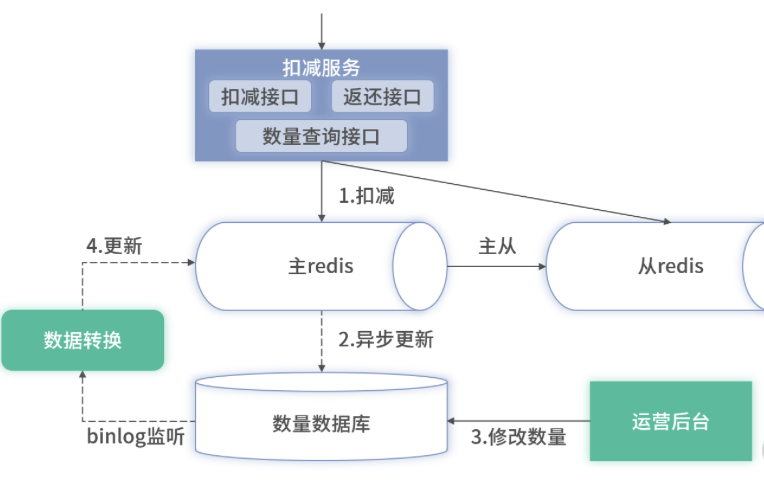
纯缓存方案的主要优点是性能提升明显
在极端情况下可能会出现丢数据,进而产生少卖。另外,为了保证不出现少卖,纯缓存的方案需要做很多的对账、异常处理等的设计,系统复杂度会大幅增加

 浙公网安备 33010602011771号
浙公网安备 33010602011771号