


binlog2redis
如何发送Binlog
MySQL 的 Binlog 分为三种数据格式:statement、row 及 mixed 格式
1. statement 格式
update demo_table set status='无效' where id =1 内容太少,传输速度快。解析上述的 SQL 获取变更的字段,存在一定的开发成本。
2. row 格式
{
"before":{
"id":1,
"message":"文本",
"status":"有效",
"created":"xxxx-xx-xx",
"modified":"xxxx-xx-xx"
},
"after":{
"id":1,
"message":"文本",
"status":"无效",
"created":"xxxx-xx-xx",
"modified":"xxxx-xx-xx"
},
"change_fields":["status"]
}
数据同步的实现代码会非常简单,但缺点是,上述格式产生的数据量较大。
3. mixed 模式
mixed 模式是上述两种模式的动态结合。采用 mixed 模式的 Binlog 会根据每一条执行的 SQL 动态判断是记录为 row 格式还是 statement 格式。
在实际应用中,推荐使用 row 模式或者 mixed 模式
原因一:这两种格式的数据量全,可以让你做更多的逻辑。因为随着业务需求的发展,同步逻辑会出现非常多的个性化需求,越多信息的数据,在编写代码时会越简单。
原因二:row 模式无须解析SQL,实现复杂度非常低。在执行的 SQL 非常复杂时,对 statement 模式里记录的 SQL 的解析需要耗费大量开发精力,越复杂的解析越容易产生 Bug,所以推荐更加简单的 row 模式的数据格式。
Binlog 如何高效消费
1. 全串行的方式进行消费
问题一:串行消费效率低,延迟大。
问题二:单线程无法利用水平扩展,架构有缺陷。
2. 采用并行的方式提升吞吐量及扩展性
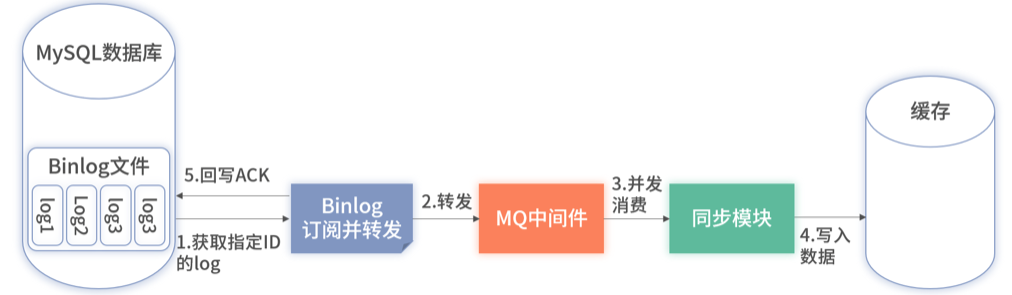
上述架构里,借用了 MQ 进行拆分。在 Binlog 处仍然进行串行消费,但只是 ACK 数据。ACK 后数据直接发送到 MQ 的某一个 Topic 里即可。因为只做 ACK 并转发至 MQ,不涉及业务逻辑,所以性能消耗非常小,大概只有几毫秒或纳秒。
MQ 中间件里的串行通道的数据均会串行执行,而多个串行通道间则可以并发执行。借助 MQ 中间件的此特性,既解决了乱序问题又保证了吞吐量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号