


全量缓存抗百万QPS
全量缓存是指将数据库中的所有数据都存储在缓存中,同时在缓存中不设置过期时间的一种实现方式
基于 Binlog 的全量缓存架构
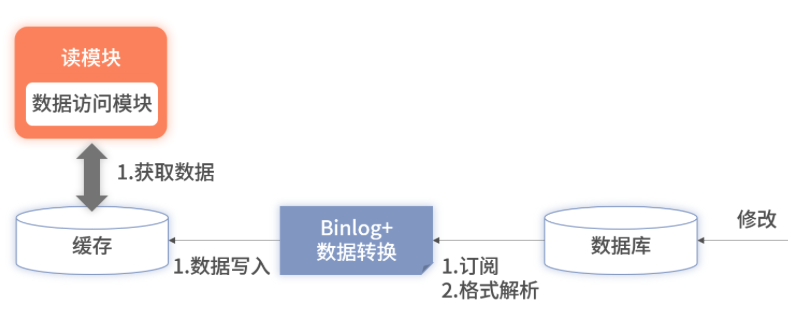
Binlog 的同步方案后,全量缓存的架构变得更加完整
1. 降低了延迟
缓存基本上是准实时的,数据库的主从同步保持在毫秒级别
2. 解决了分布式事务的问题
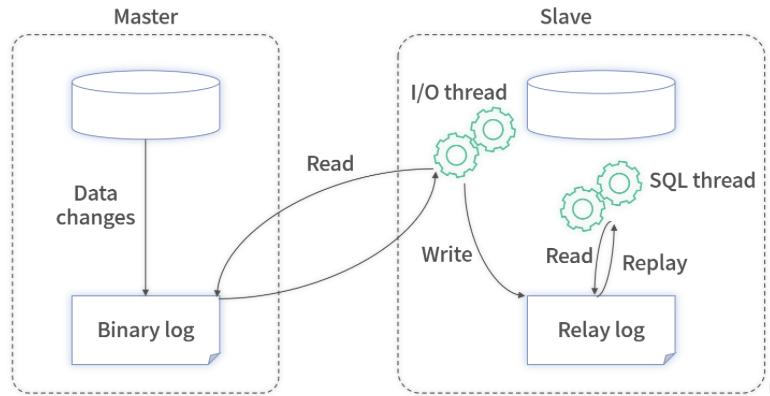
Binlog 的主从复制是基于 ACK 机制
3. 提升了代码的简洁性和可维护性
使用 Binlog 的全量缓存存在的问题
第一个问题:提升了系统的整体复杂度。
第二个问题:缓存的容量会成倍上升,相应的资源成本也大幅上升。
存储在缓存中的数据需要经过筛选,有业务含义且会被查询的才进行存储
缓存中的数据可以进行压缩。可以采用 Gzip、Snappy 等一些较常见的压缩算法进行处理,但压缩算法通常较消耗 CPU。
将数据按 JSON 格式序列化时,可以在字段上添加替代标识
Class DemoClass{
@Field("1")
private field1;
@Field("2")
private field2;
}
多机房实时热备
为了提升性能和可用性,可以将数据同步模块写入的缓存由一个集群变成两个集群
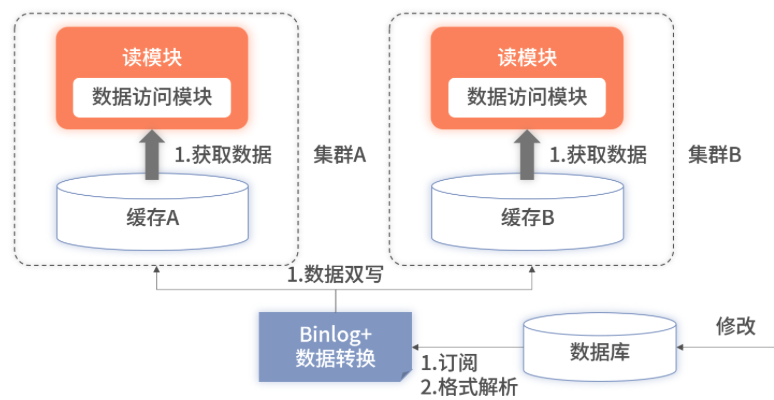
第一:提升了性能。
第二:增加了可用性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号