
本文将主要从数据、参数、模型、训练等角度分析InternVL的改进历程
InternVL1.0的核心工作是把视觉编码器的参数量级提升到与文本编码器相当的水平上
- 数据: 合并了多个数据集的共计6.03B,过滤得到4.98B的公开数据
- 参数: 视觉编码器增大到了6B,与8B的LLaMA相当。连接层新增了96个可学习query和cross-attention层,共1B参数量
- 模型: 将视觉和文本编码器使用更多的query与MLP进行深度对齐。不再是之前的较少的query与MLP组成的所谓"glue"或线性投影
- 训练: 使用渐进式训练。先用粗糙的4.98B数据训练对比任务,再用1.03B的高质量数据训练生成任务,最后用4M的高质量指令数据训练监督式微调任务
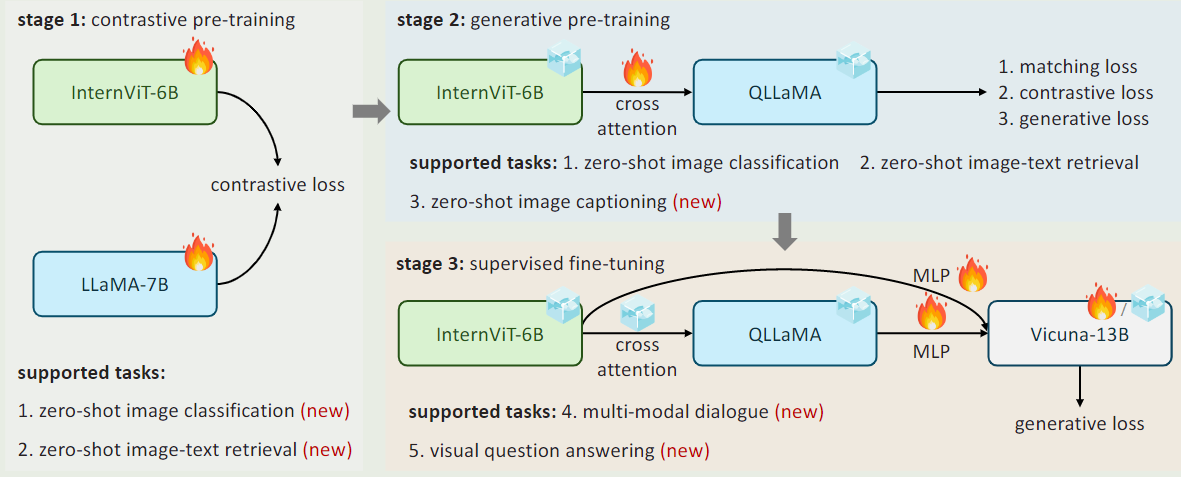
- 补充: 1)从训练部分可以知道VLLM的能力达到顶尖水平,大致需要4B左右的数据。2)单流结构:指在进入LLM之前视觉文本token就已经融合在一起,其中文本输入先后通过分词器(分成一个个子块)、embedding层(连续化),然后与经过视觉编码器的视觉token融合在一起。最后在进入LLM(也就是共同进入同一个transformer);双流结构:视觉和文本输入都各自对应一个专门的transformer decoder,他们各自的输出后面只会做一些简单的对齐操作,用于匹配和分类任务。3)InternVL不是简单的单流或双流结构,或者说它是一种特殊的单流结构,因为他们后面一起进入了一个大模型(LM Decoder),只是这个LM Decoder有三个输入:经过了embedding的文本token、经过了MLP的视觉token、以及先经过视觉编码,再经过QLLMA,再经过MLP的视觉token。通过引入这个QLLMA,以及额外的生成性任务的训练,InternVL还具备了
图像字幕生成、图像检索、图像分类能力。
InternVL1.1的核心工作是增强中文和OCR能力
- 数据: 先后使用了72M和6M的数据
- 参数: 预训练加微调共计19B
- 模型: 把与视觉编码器连接的较为繁重的中间件QLLaMA换成了MLP,因为LLaVA、MiniGPT4V等很多工作都证明了不需要Q-former,只用MLP就够了
- 训练: 两段式训练。先用72M样本训练ViT和MLP,这中间使用了插值法将分辨率提升到448×448,并利用pixel shuffle减少token总量,从而降低训练成本。再用6M样本训练MLP和LLM,这里的样本有中文翻译内容,增强了模型的中文理解能力

- 补充: 为什么换掉了QLLMA:1)参数太多,模型训练耗时较长。2)核心原因:QLLMA脱胎于LLMA 7B,QFormer本质是一个Bert加了额外的cross attention,也就是说LLMA更大,相当于QFormer的更具重量级的版本。然而,就像上面说的那样,已经有工作证明QFormer根本不需要,那么更重的QLLMA也就更不需要了。3)从原理上讲,QFormer具有一个显示压缩的操作,即它的查询向量远小于token数量,QFormer通过交叉注意力将N维视觉空间投影到M维语义空间,虽然一定程度上能抑制无关信息,但也不可避免的损失了一些语义信息。
InternVL1.2的核心工作是集成多个模型来增强视觉编码器,同时把文本编码器更换成参数量更大的Nous-Hermes-2-Yi-34B。
- 数据: 先后使用了39.3M和1.2M视觉指令调优样本
- 参数: 预训练加微调共计40.07B
- 模型: 把视觉编码器通过集成多个模型进行增强,把文本编码器换成参数量更大的Nous-Hermes-2-Yi-34B
- 训练: 两段式训练。先用39.3M样本训练ViT和MLP。再用1.2M样本训练MLP和LLM。

- 补充: 这篇文章里作者生成6B的视觉编码器使得它在量级上与文本编码器相当是很重要的,但事实上并没有消融实验证明更小的情况下效果会明显变差,例如1,2,3,4,5,6B下分别实验。
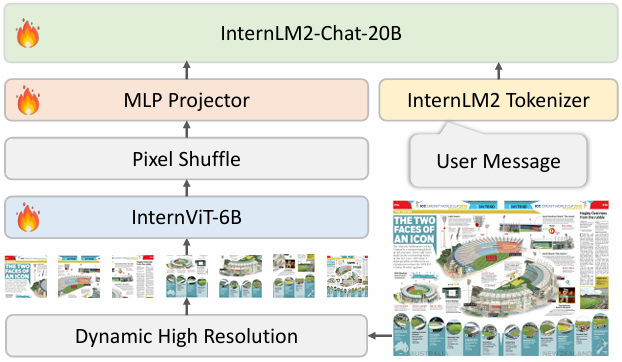
InternVL1.5的核心工作是更强的视觉编码器(丢弃3层不重要的权重层),同时把文本编码器更换成InternLM2-20B。另外提出使用动态分辨率和高质量的双语数据集
- 数据: 先后使用了39.3M和1.2M视觉指令调优样本
- 参数: 预训练加微调共计26B
- 模型: 把视觉编码器通过集成多个模型进行增强,把文本编码器换成参数量更大的Nous-Hermes-2-Yi-34B
- 训练: a.分阶段训练:InternVL 1.5的训练分为两个阶段。首先,在预训练阶段,训练InternViT-6B视觉编码器和MLP投影器,以优化视觉特征提取。然后,在微调阶段,对整个模型的260亿参数进行微调,以增强多模态能力
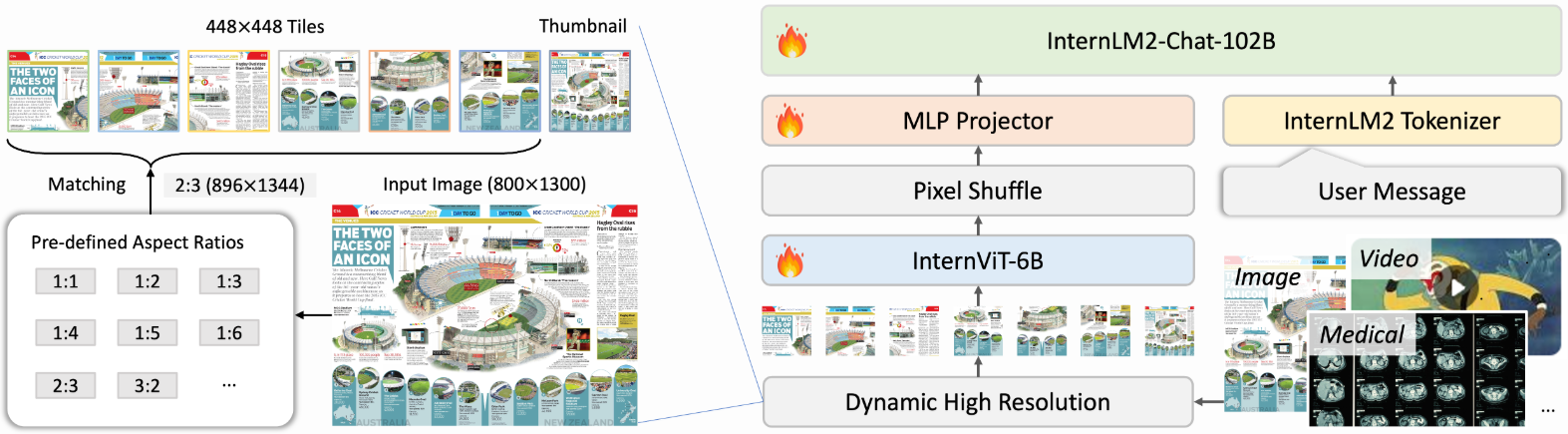
b.动态分辨率训练:在训练过程中,模型采用动态分辨率策略,根据图像的纵横比和分辨率将图像分割成448×448像素的图像块,最多支持12个图像块。在测试阶段,模型可以零样本扩展到最多40个图像块,即4K分辨率
c.数据翻译流程:为了增强模型的多语言能力,采用了数据翻译流程,利用开源的大语言模型(LLM)或GPT-3.5将英文数据集翻译成其他语言(如中文)。通过这种方法,可以保持双语标注的一致性和准确性,并且可以轻松扩展到更多语言
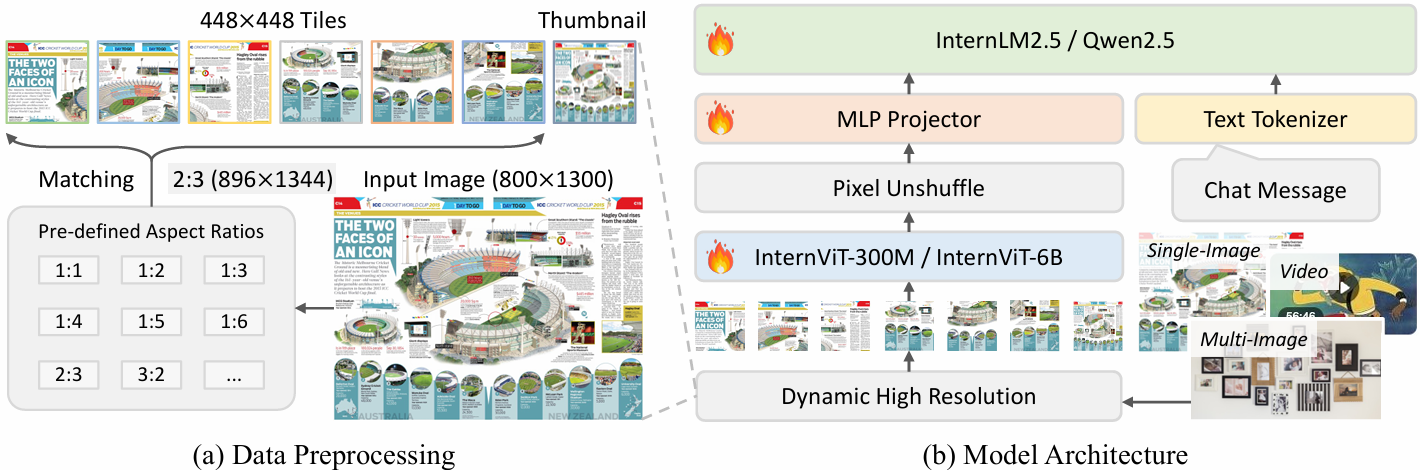
- 补充: 动态分辨率策略主要包含以下几个关键原理:
(1)动态纵横比匹配: 预定义35种可能的图块组合方式(如1x1, 1x2, 2x6等),根据输入图像的原始纵横比,选择最接近且不超过原图面积2倍的组合方式,例如800x1300图像会被调整为896x1344(2x3图块组合)
(2)智能图块分割: 将调整后的图像分割为448x448像素的图块,训练时最多分割12个图块,测试时可扩展至40个(支持4K分辨率),例如文档图像可能被分割为多行多列的图块。
(3)全局缩略图融合: 额外生成448x448的全局缩略图,与局部图块共同输入,兼顾全局上下文和局部细节,总视觉token数训练时为256-3,328,测试时可达10,496
(4)像素重排优化: 使用pixel shuffle操作将每个图块的视觉token压缩至1/4,保证高分辨率处理时的计算效率,单个448x448图块最终表示为256个视觉token
InternVL2的核心工作是将繁重的6B视觉编码器换成了300M的ViT(2B-8B的InternVL),另外图像端可以输入生物医疗图像和视频
InternVL2.5的核心工作是引入了JPEG压缩和损失函数重加权技术
- 数据: 数据总量来到了16.3M,通过统一对话模版、模型打分、应用启发式规则来提升数据质量。另外引入JPEG压缩技术来模拟互联网中常见的数据降质现象,提高对噪声、压缩图像的鲁棒性
- 参数: InternVL 2.5 系列模型具有多种参数规模,包括 1B、2B、4B、8B、26B、38B 和 78B 等不同版本
- 模型: InternVL 采用 InternViT 作为视觉编码器,有 InternViT-300M 和 InternViT-6B 两种不同模型规模
- 训练: 为了提高模型对现实场景的适应性和整体性能,引入了随机 JPEG 压缩和损失函数重加权等技术。随机 JPEG 压缩通过模拟互联网图像的降质情况,提高模型对噪声和压缩图像的鲁棒性;损失函数重加权则通过平衡不同长度回应的贡献,避免模型在训练过程中对较短或较长回应的偏见。损失重加权技术: 传统的损失函数计算方式包括 token averaging 和 sample averaging,这两种方法各有其局限性。
Token Averaging:计算所有 tokens 的平均损失。每个 token 对最终损失的贡献相同,这可能导致模型对 token 数量更多的回应过度优化,从而降低在基准测试中的性能。
Sample Averaging:首先计算每个样本内的平均损失(跨 tokens),然后再计算样本的平均损失。这种方法确保每个样本对最终损失的贡献相同,但可能导致模型倾向于生成较短的回应,从而影响用户体验。
为了避免这两种方法的偏向,InternVL 2.5 引入了一种称为 square averaging 的损失函数重加权策略。在这种策略中,权重\(\omega\)被设置为 \(\frac{1}{\sqrt{x}}\),其中\(x\)是回应中token的数量。这种方法平衡了不同长度回应的贡献,减少了模型对长回应或短回应的偏向。
- 补充: 这里的损失重加权技术 本质上是为了让对损失贡献高的样本或token反而具有更低一点的损失贡献,相当于削强补弱,具体体现在倒数那里。
InternVL3的核心工作是引入了可变视觉编码、原生多模态预训练、混合偏好优化、使用Visual的测试时缩放
- 数据: 预训练阶段,在InternVL2.5的数据基础上加入了图形用户界面(GUI)任务,工具使用,3D场景理解和视频理解对应数据。微调阶段,引入额外的工具使用,3D场景理解,GUI操作,科学图表,创意写作和多模态推理样本。混合偏好优化阶段,基于MMPR v1.2中提出的数据管道和样本构建偏好对,包括大约30万个样本。
- 参数: 系列模型,参数从9.3819M(InternVL3-1B)到78.41B(InternVL3-78B)不等
- 模型: InternVL 3的架构遵循与其前身相同的一般框架,坚持“ViT-MLP-LLM”范式,集成了可变视觉位置编码(V2 PE),它利用更小,更灵活的视觉标记的位置增量。受益于V2 PE,InternVL 3表现出更好的长上下文理解能力相比它的前辈。
- 训练: 原生多模态预训练,不再像其他模型一样先预训练仅语言的大模型再适应额外的模态,InternVL3通过交织多模态数据(例如,图像-文本、视频-文本或交错图像-文本序列)与大规模文本语料库。这种统一的训练方案允许预训练模型同时学习语言和多模态能力,最终增强其处理视觉语言任务的能力,而无需引入额外的桥接模块或后续的模型间对齐程序。
- 补充: (1)可变视觉编码:对于同一个编码位置,“塞入”多个视觉token,这样有限且整数表示的位置编码矩阵就可以编码更多图像token,而不会导致位置溢出问题。
- 原生多模态预训练: 统一文本图像的数据格式模版,对于纯本文数据添加虚拟视觉标记,保持输入结构统一。空标记编码:学习特殊的"无视觉内容"嵌入向量。梯度阻断:防止空标记影响视觉编码器参数。
- 混合偏好优化:混合偏好优化旨在拉大模型的好回答与差回答之间的距离(DPO),同时惩罚好回答的提升度不高的情况,以及惩罚差回答的下降幅度不高的情况(BCO),再加上生成损失,三者混合。具体来说,DPO(Direct Preference Optimization)损失表达为:

BCO(Best-of-n Comparison Optimization)损失表达为:
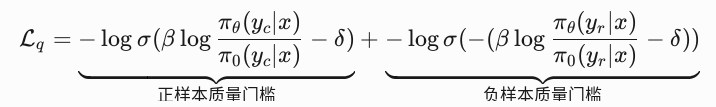
- 测试时缩放(Test-Time Scaling) 是一种在模型推理阶段(而非训练阶段)通过动态调整策略提升生成答案质量的技术。它的核心思想是:对同一问题生成多个候选答案,通过评估每个候选答案的推理过程,选择最优解输出。这种方法特别适用于需要多步推理的任务(如数学题求解、复杂逻辑分析)。
posted @
2025-04-29 11:19
期间雨
阅读(
643)
评论()
收藏
举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号