
[转]Redis内部数据结构详解-sds
本文是《Redis内部数据结构详解》系列的第二篇,讲述Redis中使用最多的一个基础数据结构:sds。
不管在哪门编程语言当中,字符串都几乎是使用最多的数据结构。sds正是在Redis中被广泛使用的字符串结构,它的全称是Simple Dynamic String。与其它语言环境中出现的字符串相比,它具有如下显著的特点:
- 可动态扩展内存。sds表示的字符串其内容可以修改,也可以追加。在很多语言中字符串会分为mutable和immutable两种,显然sds属于mutable类型的。
- 二进制安全(Binary Safe)。sds能存储任意二进制数据,而不仅仅是可打印字符。
- 与传统的C语言字符串类型兼容。这个的含义接下来马上会讨论。
看到这里,很多对Redis有所了解的同学可能已经产生了一个疑问:Redis已经对外暴露了一个字符串结构,叫做string,那这里所说的sds到底和string是什么关系呢?可能有人会猜:string是基于sds实现的。这个猜想已经非常接近事实,但在描述上还不太准确。有关string和sds之间关系的详细分析,我们放在后面再讲。现在为了方便讨论,让我们先暂时简单地认为,string的底层实现就是sds。
在讨论sds的具体实现之前,我们先站在Redis使用者的角度,来观察一下string所支持的一些主要操作。下面是一个操作示例:

以上这些操作都比较简单,我们简单解释一下:
- 初始的字符串的值设为”tielei”。
- 第3步通过append命令对字符串进行了追加,变成了”tielei zhang”。
- 然后通过setbit命令将第53个bit设置成了1。bit的偏移量从左边开始算,从0开始。其中第48~55bit是中间的空格那个字符,它的ASCII码是0x20。将第53个bit设置成1之后,它的ASCII码变成了0x24,打印出来就是’$’。因此,现在字符串的值变成了”tielei$zhang”。
- 最后通过getrange取从倒数第5个字节到倒数第1个字节的内容,得到”zhang”。
这些命令的实现,有一部分是和sds的实现有关的。下面我们开始详细讨论。
sds的数据结构定义
我们知道,在C语言中,字符串是以’\0’字符结尾(NULL结束符)的字符数组来存储的,通常表达为字符指针的形式(char *)。它不允许字节0出现在字符串中间,因此,它不能用来存储任意的二进制数据。
我们可以在sds.h中找到sds的类型定义:
1
|
typedef char *sds;
|
肯定有人感到困惑了,竟然sds就等同于char ?我们前面提到过,sds和传统的C语言字符串保持类型兼容,因此它们的类型定义是一样的,都是char 。在有些情况下,需要传入一个C语言字符串的地方,也确实可以传入一个sds。但是,sds和char *并不等同。sds是Binary Safe的,它可以存储任意二进制数据,不能像C语言字符串那样以字符’\0’来标识字符串的结束,因此它必然有个长度字段。但这个长度字段在哪里呢?实际上sds还包含一个header结构:
1
|
struct __attribute__ ((__packed__)) sdshdr5 {
|
sds一共有5种类型的header。之所以有5种,是为了能让不同长度的字符串可以使用不同大小的header。这样,短字符串就能使用较小的header,从而节省内存。
一个sds字符串的完整结构,由在内存地址上前后相邻的两部分组成:
- 一个header。通常包含字符串的长度(len)、最大容量(alloc)和flags。sdshdr5有所不同。
- 一个字符数组。这个字符数组的长度等于最大容量+1。真正有效的字符串数据,其长度通常小于最大容量。在真正的字符串数据之后,是空余未用的字节(一般以字节0填充),允许在不重新分配内存的前提下让字符串数据向后做有限的扩展。在真正的字符串数据之后,还有一个NULL结束符,即ASCII码为0的’\0’字符。这是为了和传统C字符串兼容。之所以字符数组的长度比最大容量多1个字节,就是为了在字符串长度达到最大容量时仍然有1个字节存放NULL结束符。
除了sdshdr5之外,其它4个header的结构都包含3个字段:
- len: 表示字符串的真正长度(不包含NULL结束符在内)。
- alloc: 表示字符串的最大容量(不包含最后多余的那个字节)。
- flags: 总是占用一个字节。其中的最低3个bit用来表示header的类型。header的类型共有5种,在sds.h中有常量定义。
1
|
#define SDS_TYPE_5 0
|
sds的数据结构,我们有必要非常仔细地去解析它。
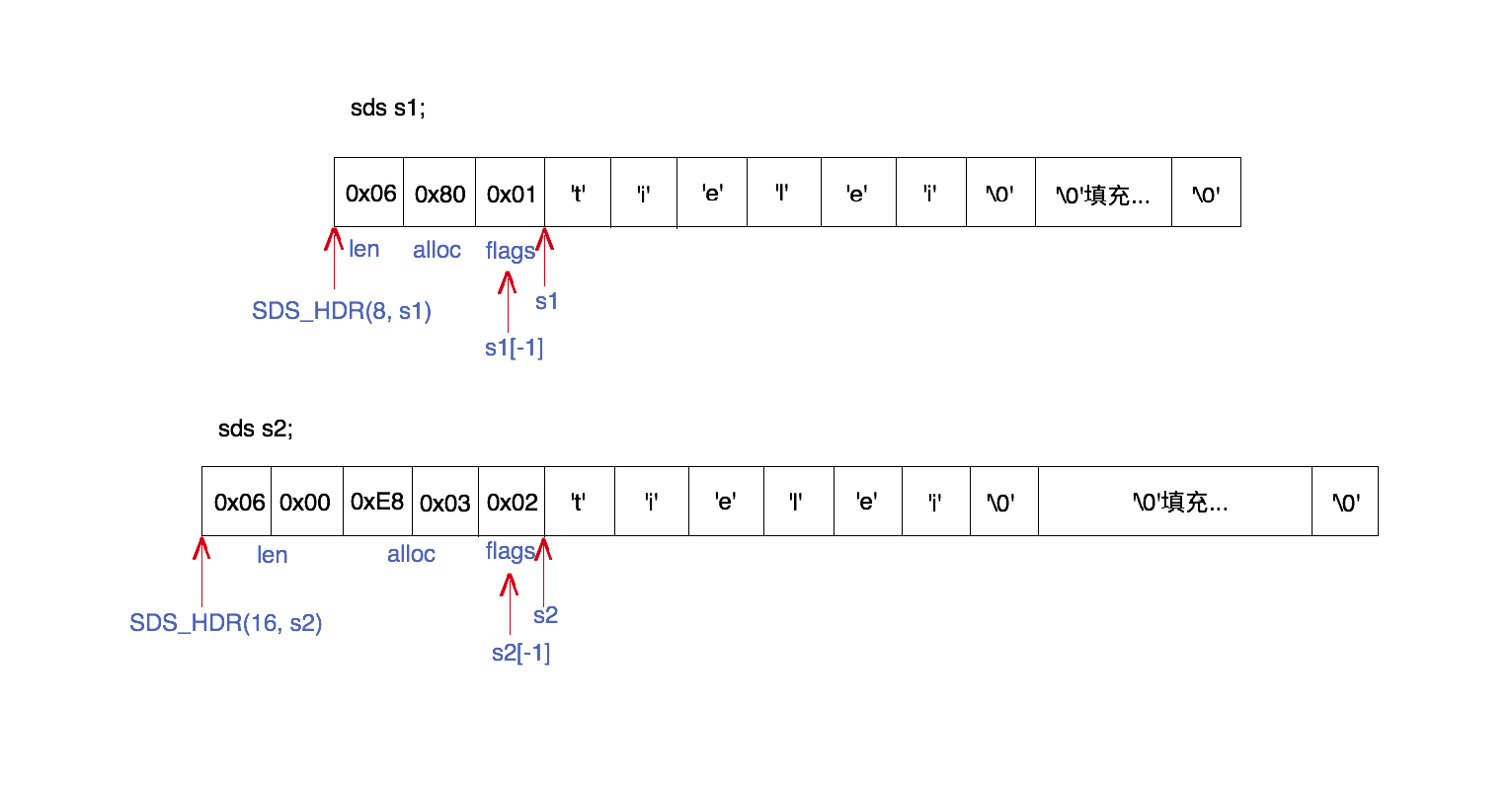
上图是sds的一个内部结构的例子。图中展示了两个sds字符串s1和s2的内存结构,一个使用sdshdr8类型的header,另一个使用sdshdr16类型的header。但它们都表达了同样的一个长度为6的字符串的值:”tielei”。下面我们结合代码,来解释每一部分的组成。
sds的字符指针(s1和s2)就是指向真正的数据(字符数组)开始的位置,而header位于内存地址较低的方向。在sds.h中有一些跟解析header有关的宏定义:
1
|
#define SDS_TYPE_MASK 7
|
其中SDS_HDR用来从sds字符串获得header起始位置的指针,比如SDS_HDR(8, s1)表示s1的header指针,SDS_HDR(16, s2)表示s2的header指针。
当然,使用SDS_HDR之前我们必须先知道到底是哪一种header,这样我们才知道SDS_HDR第1个参数应该传什么。由sds字符指针获得header类型的方法是,先向低地址方向偏移1个字节的位置,得到flags字段。比如,s1[-1]和s2[-1]分别获得了s1和s2的flags的值。然后取flags的最低3个bit得到header的类型。
- 由于s1[-1] == 0x01 == SDS_TYPE_8,因此s1的header类型是sdshdr8。
- 由于s2[-1] == 0x02 == SDS_TYPE_16,因此s2的header类型是sdshdr16。
有了header指针,就能很快定位到它的len和alloc字段:
- s1的header中,len的值为0x06,表示字符串数据长度为6;alloc的值为0x80,表示字符数组最大容量为128。
- s2的header中,len的值为0x0006,表示字符串数据长度为6;alloc的值为0x03E8,表示字符数组最大容量为1000。(注意:图中是按小端地址构成)
在各个header的类型定义中,还有几个需要我们注意的地方:
- 在各个header的定义中使用了attribute ((packed)),是为了让编译器以紧凑模式来分配内存。如果没有这个属性,编译器可能会为struct的字段做优化对齐,在其中填充空字节。那样的话,就不能保证header和sds的数据部分紧紧前后相邻,也不能按照固定向低地址方向偏移1个字节的方式来获取flags字段了。
- 在各个header的定义中最后有一个char buf[]。我们注意到这是一个没有指明长度的字符数组,这是C语言中定义字符数组的一种特殊写法,称为柔性数组(flexible array member),只能定义在一个结构体的最后一个字段上。它在这里只是起到一个标记的作用,表示在flags字段后面就是一个字符数组,或者说,它指明了紧跟在flags字段后面的这个字符数组在结构体中的偏移位置。而程序在为header分配的内存的时候,它并不占用内存空间。如果计算sizeof(struct sdshdr16)的值,那么结果是5个字节,其中没有buf字段。
- sdshdr5与其它几个header结构不同,它不包含alloc字段,而长度使用flags的高5位来存储。因此,它不能为字符串分配空余空间。如果字符串需要动态增长,那么它就必然要重新分配内存才行。所以说,这种类型的sds字符串更适合存储静态的短字符串(长度小于32)。
至此,我们非常清楚地看到了:sds字符串的header,其实隐藏在真正的字符串数据的前面(低地址方向)。这样的一个定义,有如下几个好处:
- header和数据相邻,而不用分成两块内存空间来单独分配。这有利于减少内存碎片,提高存储效率(memory efficiency)。
- 虽然header有多个类型,但sds可以用统一的char *来表达。且它与传统的C语言字符串保持类型兼容。如果一个sds里面存储的是可打印字符串,那么我们可以直接把它传给C函数,比如使用strcmp比较字符串大小,或者使用printf进行打印。
弄清了sds的数据结构,它的具体操作函数就比较好理解了。
sds的一些基础函数
- sdslen(const sds s): 获取sds字符串长度。
- sdssetlen(sds s, size_t newlen): 设置sds字符串长度。
- sdsinclen(sds s, size_t inc): 增加sds字符串长度。
- sdsalloc(const sds s): 获取sds字符串容量。
- sdssetalloc(sds s, size_t newlen): 设置sds字符串容量。
- sdsavail(const sds s): 获取sds字符串空余空间(即alloc - len)。
- sdsHdrSize(char type): 根据header类型得到header大小。
- sdsReqType(size_t string_size): 根据字符串数据长度计算所需要的header类型。
这里我们挑选sdslen和sdsReqType的代码,察看一下。
1
|
static inline size_t sdslen(const sds s) {
|
跟前面的分析类似,sdslen先用s[-1]向低地址方向偏移1个字节,得到flags;然后与SDS_TYPE_MASK进行按位与,得到header类型;然后根据不同的header类型,调用SDS_HDR得到header起始指针,进而获得len字段。
通过sdsReqType的代码,很容易看到:
- 长度在0和2^5-1之间,选用SDS_TYPE_5类型的header。
- 长度在2^5和2^8-1之间,选用SDS_TYPE_8类型的header。
- 长度在2^8和2^16-1之间,选用SDS_TYPE_16类型的header。
- 长度在2^16和2^32-1之间,选用SDS_TYPE_32类型的header。
- 长度大于2^32的,选用SDS_TYPE_64类型的header。能表示的最大长度为2^64-1。
注:sdsReqType的实现代码,直到3.2.0,它在长度边界值上都一直存在问题,直到最近3.2 branch上的commit 6032340才修复。
sds的创建和销毁
1
|
sds sdsnewlen(const void *init, size_t initlen) {
|
sdsnewlen创建一个长度为initlen的sds字符串,并使用init指向的字符数组(任意二进制数据)来初始化数据。如果init为NULL,那么使用全0来初始化数据。它的实现中,我们需要注意的是:
- 如果要创建一个长度为0的空字符串,那么不使用SDS_TYPE_5类型的header,而是转而使用SDS_TYPE_8类型的header。这是因为创建的空字符串一般接下来的操作很可能是追加数据,但SDS_TYPE_5类型的sds字符串不适合追加数据(会引发内存重新分配)。
- 需要的内存空间一次性进行分配,其中包含三部分:header、数据、最后的多余字节(hdrlen+initlen+1)。
- 初始化的sds字符串数据最后会追加一个NULL结束符(s[initlen] = ‘\0’)。
关于sdsfree,需要注意的是:内存要整体释放,所以要先计算出header起始指针,把它传给s_free函数。这个指针也正是在sdsnewlen中调用s_malloc返回的那个地址。
sds的连接(追加)操作
1
|
sds sdscatlen(sds s, const void *t, size_t len) {
|
sdscatlen将t指向的长度为len的任意二进制数据追加到sds字符串s的后面。本文开头演示的string的append命令,内部就是调用sdscatlen来实现的。
在sdscatlen的实现中,先调用sdsMakeRoomFor来保证字符串s有足够的空间来追加长度为len的数据。sdsMakeRoomFor可能会分配新的内存,也可能不会。
sdsMakeRoomFor是sds实现中很重要的一个函数。关于它的实现代码,我们需要注意的是:
- 如果原来字符串中的空余空间够用(avail >= addlen),那么它什么也不做,直接返回。
- 如果需要分配空间,它会比实际请求的要多分配一些,以防备接下来继续追加。它在字符串已经比较长的情况下要至少多分配SDS_MAX_PREALLOC个字节,这个常量在sds.h中定义为(1024*1024)=1MB。
- 按分配后的空间大小,可能需要更换header类型(原来header的alloc字段太短,表达不了增加后的容量)。
- 如果需要更换header,那么整个字符串空间(包括header)都需要重新分配(s_malloc),并拷贝原来的数据到新的位置。
- 如果不需要更换header(原来的header够用),那么调用一个比较特殊的s_realloc,试图在原来的地址上重新分配空间。s_realloc的具体实现得看Redis编译的时候选用了哪个allocator(在Linux上默认使用jemalloc)。但不管是哪个realloc的实现,它所表达的含义基本是相同的:它尽量在原来分配好的地址位置重新分配,如果原来的地址位置有足够的空余空间完成重新分配,那么它返回的新地址与传入的旧地址相同;否则,它分配新的地址块,并进行数据搬迁。参见http://man.cx/realloc。
从sdscatlen的函数接口,我们可以看到一种使用模式:调用它的时候,传入一个旧的sds变量,然后它返回一个新的sds变量。由于它的内部实现可能会造成地址变化,因此调用者在调用完之后,原来旧的变量就失效了,而都应该用新返回的变量来替换。不仅仅是sdscatlen函数,sds中的其它函数(比如sdscpy、sdstrim、sdsjoin等),还有Redis中其它一些能自动扩展内存的数据结构(如ziplist),也都是同样的使用模式。
浅谈sds与string的关系
现在我们回过头来看看本文开头给出的string操作的例子。
- append操作使用sds的sdscatlen来实现。前面已经提到。
- setbit和getrange都是先根据key取到整个sds字符串,然后再从字符串选取或修改指定的部分。由于sds就是一个字符数组,所以对它的某一部分进行操作似乎都比较简单。
但是,string除了支持这些操作之外,当它存储的值是个数字的时候,它还支持incr、decr等操作。那么,当string存储数字值的时候,它的内部存储还是sds吗?实际上,不是了。而且,这种情况下,setbit和getrange的实现也会有所不同。这些细节,我们放在下一篇介绍robj的时候再进行系统地讨论。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号