
SQL高级
in 操作符
允许在WHERE子句中规定多个值.
IN操作符是多个OR条件的简写.
SELECT column_name(s)
FROM table_name
WHERE column_name IN (value1, value2, ...);
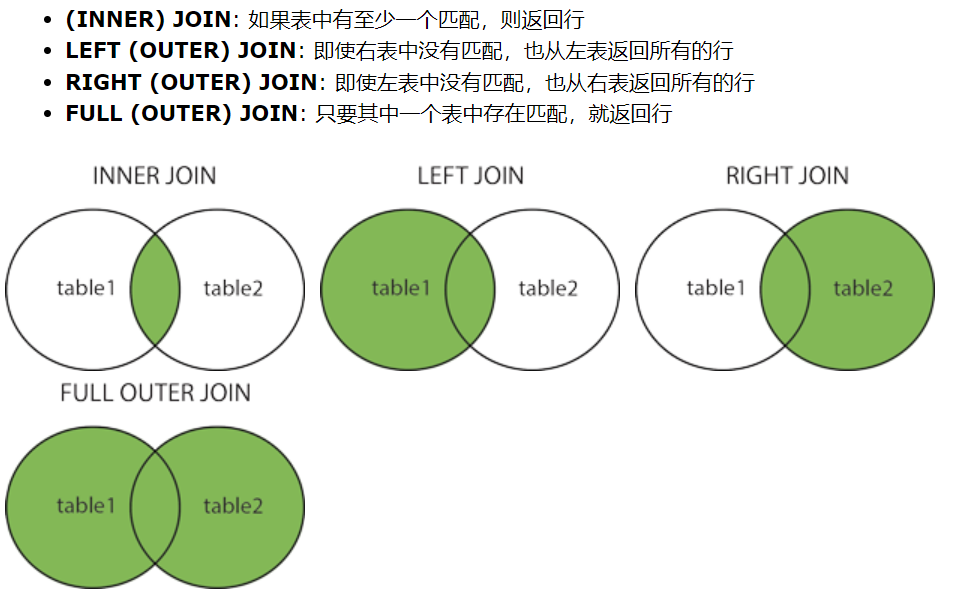
join 关键字
join : 连接三个表
SELECT Orders.OrderID, Customers.CustomerName, Shippers.ShipperName
FROM (
(Orders INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID)
INNER JOIN Shippers ON Orders.ShipperID = Shippers.ShipperID
);
left join
LEFT JOIN 关键字会从左表 (table1) 那里返回所有的行,即使在右表 (table2) 中没有匹配的行。如果没有匹配项,则结果从右侧为NULL。
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name = table2.column_name;
right join
RIGHT JOIN 关键字返回右表(table2)中的所有记录,以及左表(table1)中的匹配记录。当没有匹配项时,左侧的结果为NULL。
SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name = table2.column_name;
full join
以上 SQL 语句将产生 table1 和 table2 的并集,能匹配和不能匹配的行全部被返回,但是能匹配的行将合并为一行,不能匹配的行将另一个表中的数据用 NULL 值替换
SELECT table1.column1, table2.column2...
FROM table1
FULL JOIN table2
ON table1.common_column1 = table2.common_column2;
group by 语句
以下 SQL 语句列出了每个地区的客户数量,按从高到低排序:
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country
ORDER BY COUNT(CustomerID) DESC;
having子句
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组后的各组数据。
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
HAVING condition
ORDER BY column_name(s);
SELECT Employees.LastName, COUNT(Orders.OrderID) AS NumberOfOrders
FROM Orders
INNER JOIN Employees ON Orders.EmployeeID = Employees.EmployeeID
WHERE LastName = 'Davolio' OR LastName = 'Fuller'
GROUP BY LastName
HAVING COUNT(Orders.OrderID) > 25;
case 语句
CASE语句遍历条件并在满足第一个条件时返回一个值(如IF-THEN-ELSE语句)。因此,一旦条件为真,它将停止读取并返回结果。如果没有条件为 true,则返回 ELSE 子句中的值。
如果没有其他部分,并且没有条件为 true,则返回 NULL。
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
ELSE result
END;
使用case -> 格式 -> [ 各种函数 ] (case 列名1 when 列名2/值 then 1/处理方式 , else null/别的处理方式 end ) as 别名
SELECT
date `日期`,
count(CASE `result` WHEN '胜' THEN 1 else null END) AS `胜`,
count(CASE `result` WHEN '负' THEN 1 else null END) AS `负`
FROM
08_t_game
GROUP BY
date
SELECT `年份`,
max(CASE `季度` WHEN '1' then `销量` ELSE 0 END) as 一季度,
max(CASE `季度` WHEN '2' then `销量` ELSE 0 END) as 二季度,
max(CASE `季度` WHEN '3' then `销量` ELSE 0 END) as 三季度,
max(CASE `季度` WHEN '4' then `销量` ELSE 0 END) as 四季度
from 07_t_order_sale
GROUP BY `年份`
思路二: 使用if函数
SELECT date `日期`,
count(IF(result = '胜', 1, NULL)) `胜`,
count(IF(result = '负', 1, NULL)) `负`
FROM
08_t_game
GROUP BY
date
IFNULL 函数
SELECT ProductName, UnitPrice * (UnitsInStock + IFNULL(UnitsOnOrder, 0))
FROM Products;
create index 语句
CREATE INDEX 语句用于在表中创建索引。
从本质上看,索引是根据表的一个或者多个字段生成的子表,该子表中的数据已经进行了排序。子表除了包含指定字段中的数据,还包含一个 rowid 列,用于存储当前记录在原始表中的位置。
索引用于更快地从数据库检索数据。用户看不到索引,它们只是用来加速搜索/查询。
在表上创建一个简单的索引。允许使用重复的值:
CREATE INDEX index_name
ON table_name (column1, column2, ...);
在表上创建一个唯一的索引。唯一的索引意味着两个行不能拥有相同的索引值。
CREATE UNIQUE INDEX index_name
ON table_name (column1, column2, ...);
现在您可以针对 name 字段创建索引,用以提高检索姓名时的效率,如下所示:
CREATE INDEX myIndex
ON website(name);
myIndex 是索引的名字。
删除索引
ALTER TABLE website
DROP INDEX myIndex;
本文来自博客园,作者:简筱莜,转载请注明原文链接:https://www.cnblogs.com/jianxiaoyou/p/17204855.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号