

PHP学习笔记:通过curl实现采集网站内容
关于curl,请各位同学自行百度,我直接上案例。
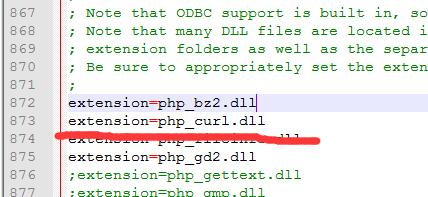
首先开启你的curl拓展,在php.ini文件把curl拓展开启,即取消extension=php_curl.dll的分号。
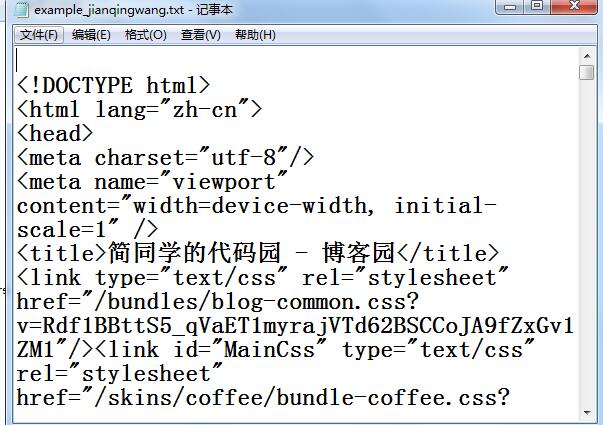
eg:利用curl采集网站内容,并输出到txt文档:
目标:抓取本博客首页,并输出到文档
<?php
$ch = curl_init("http://www.cnblogs.com/jianqingwang/");
$fp = fopen("example_jianqingwang.txt", "w");
curl_setopt($ch, CURLOPT_FILE, $fp);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_exec($ch);
curl_close($ch);
fclose($fp);
?>
效果:
eg:抓取网站内容,并直接输出
目标:抓取http://www.cnblogs.com/jianqingwang/,并直接输出
<?
// 1. 初始化
$ch = curl_init();
// 2. 设置选项,包括URL
curl_setopt($ch, CURLOPT_URL, "http://www.cnblogs.com/jianqingwang/");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 0);//改为0就不输出
curl_setopt($ch, CURLOPT_HEADER, 0);
// 3. 执行并获取HTML文档内容
$output = curl_exec($ch);
// 4. 释放curl句柄
curl_close($ch);
?>
效果:

说明:这里界面有点不一样,是因为css和图片地址都是相对路径,所以图片、css都失效了。
eg:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号