
supervisor
一、什么是supervisor
supervisor是一个Linux/Unix系统上的进程监控工具,supervisor是一个Python开发的通用的进程管理程序,可以管理和监控Linux上面的进程,能将一个普通的命令行进程变为后台daemon,并监控进程状态,异常退出时能自动重启。不过同daemontools一样,它不能监控daemon进程
supervisor官网点此。
二、为什么要用supervisor
- 使用简单 supervisor提供了一种统一的方式来start、stop、monitor你的进程, 进程可以单独控制,也可以成组的控制。你可以在本地或者远程命令行或者web接口来配置Supervisor。 在linux下的很多程序通常都是一直运行着的,一般来说都需要自己编写一个能够实现进程start/stop/restart/reload功能的脚本,然后放到/etc/init.d/下面。但这样做也有很多弊端,第一我们要为每个程序编写一个类似脚本,第二,当这个进程挂掉的时候,linux不会自动重启它的,想要自动重启的话,我们还要自己写一个监控重启脚本。 而supervisor则可以完美的解决这些问题。supervisor管理进程,就是通过fork/exec的方式把这些被管理的进程,当作supervisor的子进程来启动。这样的话,我们只要在supervisor的配置文件中,把要管理的进程的可执行文件的路径写进去就OK了。第二,被管理进程作为supervisor的子进程,当子进程挂掉的时候,父进程可以准确获取子进程挂掉的信息的,所以当然也就可以对挂掉的子进程进行自动重启,当然重启还是不重启,也要看你的配置文件里面有木有设置autostart=true了。 supervisor通过INI格式配置文件进行配置,很容易掌握,它为每个进程提供了很多配置选项,可以使你很容易的重启进程或者自动的轮转日志。
- 集中管理 supervisor管理的进程,进程组信息,全部都写在一个ini格式的文件里就OK了。而且,我们管理supervisor的时候的可以在本地进行管理,也可以远程管理,而且supervisor提供了一个web界面,我们可以在web界面上监控,管理进程。 当然了,本地,远程和web管理的时候,需要调用supervisor的xml_rpc接口,这个也是后话。 supervisor可以对进程组统一管理,也就是说咱们可以把需要管理的进程写到一个组里面,然后我们把这个组作为一个对象进行管理,如启动,停止,重启等等操作。而linux系统则是没有这种功能的,我们想要停止一个进程,只能一个一个的去停止,要么就自己写个脚本去批量停止。
三、supervisor组件组成
- supervisord 主进程,负责管理进程的server,它会根据配置文件创建指定数量的应用程序的子进程,管理子进程的整个生命周期,对crash的进程重启,对进程变化发送事件通知等。同时内置web server和XML-RPC Interface,轻松实现进程管理。。该服务的配置文件在/etc/supervisor/supervisord.conf。
- supervisorctl 客户端的命令行工具,提供一个类似shell的操作接口,通过它你可以连接到不同的supervisord进程上来管理它们各自的子程序,命令通过UNIX socket或者TCP来和服务通讯。用户通过命令行发送消息给supervisord,可以查看进程状态,加载配置文件,启停进程,查看进程标准输出和错误输出,远程操作等。服务端也可以要求客户端提供身份验证之后才能进行操作。
- Web Server supervisor提供了web server功能,可通过web控制进程(需要设置[inethttpserver]配置项)。
- XML-RPC Interface XML-RPC接口, 就像HTTP提供WEB UI一样,用来控制supervisor和由它运行的程序。
# 安装 yum install python-setuptools easy_install supervisor # 查看版本 supervisord -v # 设置配置文件 ### 生成配置文件,且放在/etc目录下 echo_supervisord_conf > /etc/supervisord.conf #为了不将所有新增配置信息全写在一个配置文件里,这里新建一个文件夹,每个程序设置一个配置文件,相互隔离 mkdir /etc/supervisord.d/ ### 修改配置文件 vim /etc/supervisord.conf # 加入以下配置信息 [include] files = /etc/supervisord.d/*.conf # 在supervisord.conf中设置通过web可以查看管理的进程,加入以下代码(默认即有,取消注释即可) [inet_http_server] port=9001 username=user password=123 # 启动 supervisord -c /etc/supervisord.conf # 查看是否监听 lsof -i:9001 # 修改默认配置文件,复制系统重启删除 将tmp改为/var/run或者/var/log或者其它 现在通过 http://ip:9001/ 就可以查看supervisor的web界面了(默认用户名及密码是user和123),当然目前还没有加入任何监控的程序。

写一个脚本,验证supervisor的监控效果
import json import sys from http.server import HTTPServer, BaseHTTPRequestHandler if sys.argv[1:]: port = int(sys.argv[1]) else: port = 8888 data = {'result': 'this is a test'} host = ('0.0.0.0', port) class Resquest(BaseHTTPRequestHandler): def do_GET(self): self.send_response(200) self.send_header('Content-type', 'application/json') self.end_headers() self.wfile.write(json.dumps(data).encode()) if __name__ == '__main__': server = HTTPServer(host, Resquest) print("Starting server, listen at: %s:%s" % host) server.serve_forever()
增加一个配置文件,以便supervisor用来监控test_http.py程序。
[program:http_test] command=python3 /root/temp/http_test.py 8888 ; 被监控的进程路径 directory=/root/temp ; 执行前要不要先cd到目录去,一般不用 priority=1 ;数字越高,优先级越高 numprocs=1 ; 启动几个进程 autostart=true ; 随着supervisord的启动而启动 autorestart=true ; 自动重启。。当然要选上了 startretries=10 ; 启动失败时的最多重试次数 exitcodes=0 ; 正常退出代码(是说退出代码是这个时就不再重启了吗?待确定) stopsignal=KILL ; 用来杀死进程的信号 stopwaitsecs=10 ; 发送SIGKILL前的等待时间 redirect_stderr=true ; 重定向stderr到stdout
重新启动supervisord,或者重新加载配置文件
supervisorctl reload # 或者 supervisorctl -c /etc/supervisord.conf
此时再访问http页面,就会发现test_http.py程序已经被监控了,且已经自动启动了。
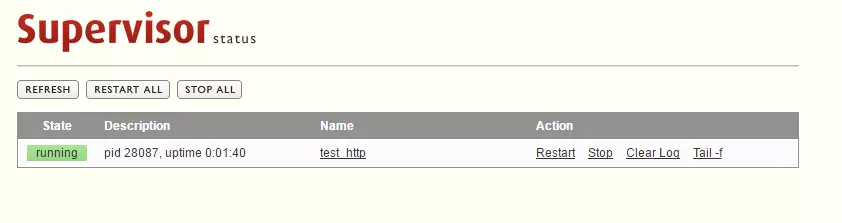
此时也可以访问test_http.py程序提供的http服务了,比如http://ip:9999。
注意:supervisor只能监控前台程序, 如果你的程序是通过fork方式实现的daemon服务,则不能用它监控,否则supervisor> status 会提示:BACKOFF Exited too quickly (process log may have details)。 因此像apache、tomcat服务默认启动都是按daemon方式启动的,则不能通过supervisor直接运行启动脚本(service httpd start),相反要通过一个包装过的启停脚本来完成,比如tomcat在supervisor下的启停脚本请参考:Controlling tomcat with supervisor或者supervisor-tomcat.conf。
另外,可以将supervisor随系统启动而启动,Linux 在启动的时候会执行 /etc/rc.local 里面的脚本,所以只要在这里添加执行命令即可:
# 如果是 Ubuntu 添加以下内容(这里要写全路径,因为此时PATH的环境变量未必设置) /usr/local/bin/supervisord -c /etc/supervisord.conf # 如果是 Centos 添加以下内容 /usr/bin/supervisord -c /etc/supervisord.conf
部署FLASK
""" uwsgi.ini """ [uwsgi] module = wsgi:app master = true processes = 1 chdir = /data/project/amazon-track-api/amazon_track_api http = /data/project/amazon-track-api/myproject.sock http = 0.0.0.0:8080 # logto = /data/project/amazon-track-api/myproject.log chmod-socket = 660 vacuum = true enable-threads = true # 参数 - module相当于之前命令行中的-w参数; - processes相当于之前的-p参数; - socket此处包含两个,一个是指定了暴露的端口,另外指定了一个myproject.sock文件保存socker信息。 - chdir是项目路径地址。 - logto是日志输出地址。 # 启动 uwsgi --ini ./uwsgi.ini """ nginx """ worker_processes 4; events { worker_connections 1024; } http { include /usr/local/nginx/conf/mime.types; default_type application/octet-stream; server { listen 8081; location / { include /usr/local/nginx/conf/uwsgi_params; uwsgi_pass 127.0.0.1:8080; } } } # 启动 nginx -c ./nginx.conf """ supvisor 控制uwsgi """ # 新增配置文件 [program:amazon-track-api] directory=/data/project/amazon-track-api/ command=/home/loctek-admin/anaconda3/envs/amazon-track-api/bin/uwsgi --ini /data/project/amazon-track-api/uwsgi.ini environment=PATH=/home/loctek-admin/anaconda3/envs/amazon-track-api/bin user=root autostart=true autorestart=true stdout_logfile=/var/log/amazon-track-api/out.log stderr_logfile=/var/log/amazon-track-api/err.log
""" UWSGI参数配置 """ master = true #启动主进程,来管理其他进程,其它的uwsgi进程都是这个master进程的子进程,如果kill这个master进程,相当于重启所有的uwsgi进程。 chdir = /web/www/mysite #在app加载前切换到当前目录, 指定运行目录 module = mysite.wsgi # 加载一个WSGI模块,这里加载mysite/wsgi.py这个模块 py-autoreload=1 #监控python模块mtime来触发重载 (只在开发时使用) lazy-apps=true #在每个worker而不是master中加载应用 socket = /test/myapp.sock #指定socket文件,也可以指定为127.0.0.1:9000,这样就会监听到网络套接字 processes = 2 #启动2个工作进程,生成指定数目的worker/进程 buffer-size = 32768 #设置用于uwsgi包解析的内部缓存区大小为64k。默认是4k。 daemonize = /var/log/myapp_uwsgi.log # 使进程在后台运行,并将日志打到指定的日志文件或者udp服务器 log-maxsize = 5000000 #设置最大日志文件大小 disable-logging = true #禁用请求日志记录 vacuum = true #当服务器退出的时候自动删除unix socket文件和pid文件。 listen = 120 #设置socket的监听队列大小(默认:100) pidfile = /var/run/uwsgi.pid #指定pid文件 enable-threads = true #允许用内嵌的语言启动线程。这将允许你在app程序中产生一个子线程 reload-mercy = 8 #设置在平滑的重启(直到接收到的请求处理完才重启)一个工作子进程中,等待这个工作结束的最长秒数。这个配置会使在平滑地重启工作子进程中,如果工作进程结束时间超过了8秒就会被强行结束(忽略之前已经接收到的请求而直接结束) max-requests = 5000 #为每个工作进程设置请求数的上限。当一个工作进程处理的请求数达到这个值,那么该工作进程就会被回收重用(重启)。你可以使用这个选项来默默地对抗内存泄漏 limit-as = 256 #通过使用POSIX/UNIX的setrlimit()函数来限制每个uWSGI进程的虚拟内存使用数。这个配置会限制uWSGI的进程占用虚拟内存不超过256M。如果虚拟内存已经达到256M,并继续申请虚拟内存则会使程序报内存错误,本次的http请求将返回500错误。 harakiri = 60 #一个请求花费的时间超过了这个harakiri超时时间,那么这个请求都会被丢弃,并且当前处理这个请求的工作进程会被回收再利用(即重启)
五、supervisor管理
supervisor的管理可以用命令行工具(supervisorctl)或者web界面管理,如果一步步按上面步骤操作,那么web管理就可以正常使用了,这里单独介绍下supervisorctl命令工具:
### 查看supervisorctl支持的命令 # supervisorctl help default commands (type help <topic>): ===================================== add exit open reload restart start tail avail fg pid remove shutdown status update clear maintail quit reread signal stop version ### 查看当前运行的进程列表 # supervisorctl status test_http RUNNING pid 28087, uptime 0:05:17 """ update 更新新的配置到supervisord(不会重启原来已运行的程序) reload,载入所有配置文件,并按新的配置启动、管理所有进程(会重启原来已运行的程序) start xxx: 启动某个进程 restart xxx: 重启某个进程 stop xxx: 停止某一个进程(xxx),xxx为[program:theprogramname]里配置的值 stop groupworker: 重启所有属于名为groupworker这个分组的进程(start,restart同理) stop all,停止全部进程,注:start、restart、stop都不会载入最新的配置文 reread,当一个服务由自动启动修改为手动启动时执行一下就ok """
六、supervisor配置参数
supervisord的配置文件主要由几个配置段构成,配置项以K/V格式呈现。
1.unixhttpserver配置块
在该配置块的参数项表示的是一个监听在socket上的HTTP server,如果[unixhttpserver]块不在配置文件中或被注释,则不会启动基于socket的HTTP server。该块的参数介绍如下:
- file:一个unix domain socket的文件路径,HTTP/XML-RPC会监听在这上面 - chmod:在启动时修改unix domain socket的mode - chown:修改socket文件的属主 - username:HTTP server在认证时的用户名 - password:认证密码
2.inethttpserver配置块
在该配置块的参数项表示的是一个监听在TCP上的HTTP server,如果[inethttpserver]块不在配置文件中或被注释,则不会启动基于TCP的HTTP server。该块的参数介绍如下:
- port:TCP监听的地址和端口(ip:port),这个地址会被HTTP/XML-RPC监听 - username:HTTP server在认证时的用户名 - password:认证密码
3.supervisord配置块
该配置块的参数项是关于supervisord进程的全局配置项。该块的参数介绍如下:
- logfile:log文件路径 - logfile_maxbytes:log文件达到多少后自动进行轮转,单位是KB、MB、GB。如果设置为0则表示不限制日志文件大小 - logfile_backups:轮转日志备份的数量,默认是10,如果设置为0,则不备份 - loglevel:error、warn、info、debug、trace、blather、critical - pidfile:pid文件路径 - umask:umask值,默认022 - nodaemon:如果设置为true,则supervisord在前台启动,而不是以守护进程启动 - minfds:supervisord在成功启动前可用的最小文件描述符数量,默认1024 - minprocs:supervisord在成功启动前可用的最小进程描述符数量,默认200 - nocleanup:防止supervisord在启动的时候清除已经存在的子进程日志文件 - childlogdir:自动启动的子进程的日志目录 - user:supervisord的运行用户 - directory:supervisord以守护进程运行的时候切换到这个目录 - strip_ansi:消除子进程日志文件中的转义序列 - environment:一个k/v对的list列表
该块的参数通常不需要改动就可以使用,当然也可以按需修改。
4.program配置块
- command:启动程序使用的命令,可以是绝对路径或者相对路径 - process_name:一个python字符串表达式,用来表示supervisor进程启动的这个的名称,默认值是%(program_name)s - numprocs:Supervisor启动这个程序的多个实例,如果numprocs>1,则process_name的表达式必须包含%(process_num)s,默认是1 - numprocs_start:一个int偏移值,当启动实例的时候用来计算numprocs的值 - priority:权重,可以控制程序启动和关闭时的顺序,权重越低:越早启动,越晚关闭。默认值是999 - autostart:如果设置为true,当supervisord启动的时候,进程会自动重启。 - autorestart:值可以是false、true、unexpected。false:进程不会自动重启,unexpected:当程序退出时的退出码不是exitcodes中定义的时,进程会重启,true:进程会无条件重启当退出的时候。 - startsecs:程序启动后等待多长时间后才认为程序启动成功 - startretries:supervisord尝试启动一个程序时尝试的次数。默认是3 - exitcodes:一个预期的退出返回码,默认是0,2。 - stopsignal:当收到stop请求的时候,发送信号给程序,默认是TERM信号,也可以是 HUP, INT, QUIT, KILL, USR1, or USR2。 - stopwaitsecs:在操作系统给supervisord发送SIGCHILD信号时等待的时间 - stopasgroup:如果设置为true,则会使supervisor发送停止信号到整个进程组 - killasgroup:如果设置为true,则在给程序发送SIGKILL信号的时候,会发送到整个进程组,它的子进程也会受到影响。 - user:如果supervisord以root运行,则会使用这个设置用户启动子程序 - redirect_stderr:如果设置为true,进程则会把标准错误输出到supervisord后台的标准输出文件描述符。 - stdout_logfile:把进程的标准输出写入文件中,如果stdout_logfile没有设置或者设置为AUTO,则supervisor会自动选择一个文件位置。 - stdout_logfile_maxbytes:标准输出log文件达到多少后自动进行轮转,单位是KB、MB、GB。如果设置为0则表示不限制日志文件大小 - stdout_logfile_backups:标准输出日志轮转备份的数量,默认是10,如果设置为0,则不备份 - stdout_capture_maxbytes:当进程处于stderr capture mode模式的时候,写入FIFO队列的最大bytes值,单位可以是KB、MB、GB - stdout_events_enabled:如果设置为true,当进程在写它的stderr到文件描述符的时候,PROCESS_LOG_STDERR事件会被触发 - stderr_logfile:把进程的错误日志输出一个文件中,除非redirect_stderr参数被设置为true - stderr_logfile_maxbytes:错误log文件达到多少后自动进行轮转,单位是KB、MB、GB。如果设置为0则表示不限制日志文件大小 - stderr_logfile_backups:错误日志轮转备份的数量,默认是10,如果设置为0,则不备份 - stderr_capture_maxbytes:当进程处于stderr capture mode模式的时候,写入FIFO队列的最大bytes值,单位可以是KB、MB、GB - stderr_events_enabled:如果设置为true,当进程在写它的stderr到文件描述符的时候,PROCESS_LOG_STDERR事件会被触发 - environment:一个k/v对的list列表 - directory:supervisord在生成子进程的时候会切换到该目录 - umask:设置进程的umask - serverurl:是否允许子进程和内部的HTTP服务通讯,如果设置为AUTO,supervisor会自动的构造一个url
七、集群管理
supervisor不支持跨机器的进程监控,一个supervisord只能监控本机上的程序,大大限制了supervisor的使用。
不过由于supervisor本身支持xml-rpc,因此也有一些基于supervisor二次开发的多机器进程管理工具。比如:
- Django-Dashvisor Web-based dashboard written in Python. Requires Django 1.3 or 1.4.
- Nodervisor Web-based dashboard written in Node.js.
- Supervisord-Monitor Web-based dashboard written in PHP.
- SupervisorUI Another Web-based dashboard written in PHP.
- cesi cesi is a web interface provides manage supervizors from same interface.
git clone https://github.com/Gamegos/cesi cd cesi && mkdir pack python setup.py build python setup.py install sqlite3 /自己的路径path/userinfo.db < userinfo.sql cp cesi.conf /etc/cesi.conf ### 自行修改cesi.conf内容,kv对,很简单 cd cesi && python web.py ### 即可启动成功
cesi.conf配置文件的设置:
[node:local] ### 设置监控的各个机器 username = user password = 123 host = 192.168.14.8 port = 9001 ;[node:<node_name2>] ### 如果有多台机器,就依次添加 ;username = <username> ;password = <password> ;host = <hostname> ;port = <port> ;[environment:<environment_name>] ;members = <node_name>, <node_name2> [cesi] database = /root/temp/cesi/userinfo.db ### 设置db路径 activity_log = /root/temp/cesi/cesi.log ### 设置log路径 host = 0.0.0.0
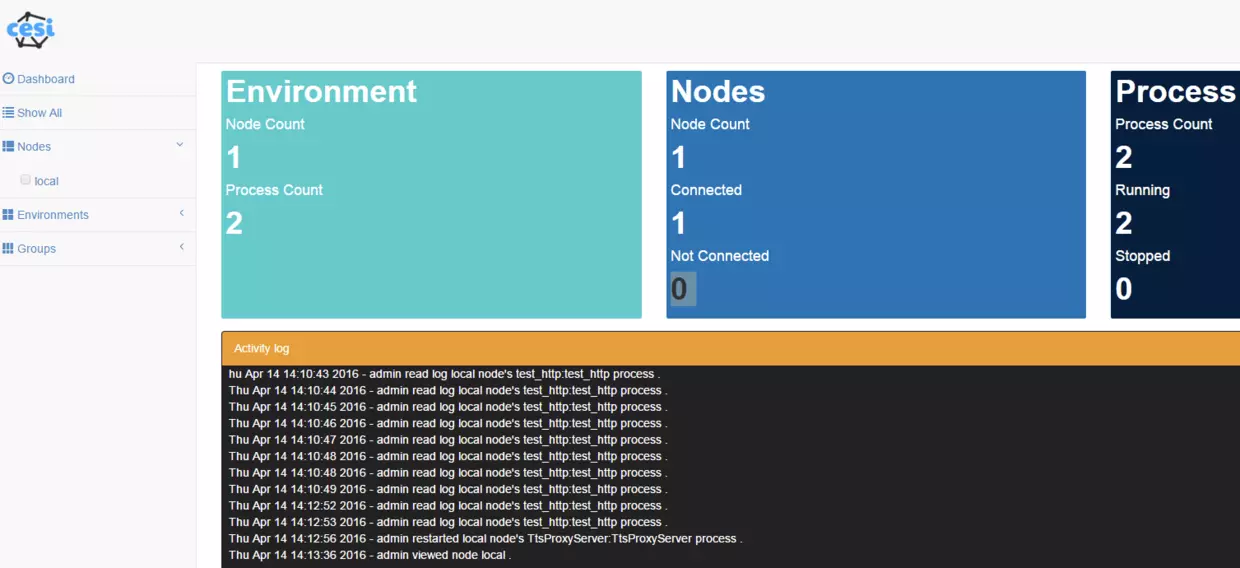
一切顺利的话,可通过页面http://ip:5000,用户名,密码都是admin,最终的效果如下所示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号