
一、爬虫的基本体系和urllib的基本使用
爬虫
网络是一爬虫种自动获取网页内容的程序,是搜索引擎的重要组成部分。网络爬虫为搜索引擎从万维网下载网页。一般分为传统爬虫和聚焦爬虫。
爬虫的分类
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。通俗的讲,也就是通过源码解析来获得想要的内容。
聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
防爬虫:KS-WAF将爬虫行为分为搜索引擎爬虫及扫描程序爬虫,可屏蔽特定的搜索引擎爬虫节省带宽和性能,也可屏蔽扫描程序爬虫,避免网站被恶意抓取页面。
爬虫的本质
网络爬虫本质就是浏览器http请求。
浏览器和网络爬虫是两种不同的网络客户端,都以相同的方式来获取网页:
1)首先, 客户端程序连接到域名系统(DNS)服务器上,DNS服务器将主机 名转换成ip 地址。
2)接下来,客户端试着连接具有该IP地址的服务器。服务器上可能有多个 不同进程程序在运行,每个进程程序都在监听网络以发现新的选接。.各个进程监听不同的网络端口 (port). 端口是一个l6位的数卞,用来辨识不同的服务。Http请求一般默认都是80端口。
3) 一旦建立连接,客户端向服务器发送一个http请求,服务器接收到请求后,返回响应结果给客户端。
4)客户端关闭该连接。
通用的爬虫框架流程:
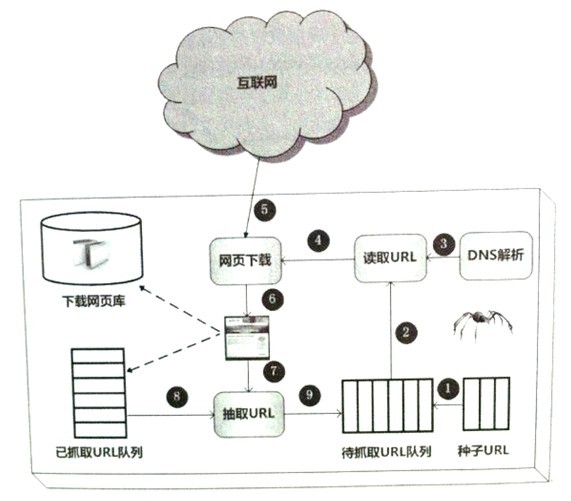
1)首先从互联网页面中精心选择一部分网页,以这 些网页的链接地址作为种子URL;
2)将这些种子URL放入待抓取URL队列中;
3)爬虫从待抓取 URL队列依次读取,并将URL通过DNS解析,把链接地址转换为网站服务器对应的IP地址。
4)然后将IP地址和网页相对路径名称交给网页下载器,
5)网页下载器负责页面内容的下载。
6)对于下载到 本地的网页,一方面将其存储到页面库中,等待建立索引等后续处理;另一方面将下载网页的 URL放入己抓取URL队列中,这个队列记载了爬虫系统己经下载过的网页URL,以避免网页 的重复抓取。
7)对于刚下载的网页,从中抽取出所包含的所有链接信息,并在已抓取URL队列 中检査,如果发现链接还没有被抓取过,则将这个URL放入待抓取URL队歹!
8,9)末尾,在之后的 抓取调度中会下载这个URL对应的网页,如此这般,形成循环,直到待抓取URL队列为空
爬虫的基本流程:
发起请求:
通过HTTP库向目标站点发起请求,也就是发送一个Request,请求可以包含额外的header等信息,等待服务器响应
获取响应内容
如果服务器能正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能是HTML,Json字符串,二进制数据(图片或者视频)等类型
解析内容
得到的内容可能是HTML,可以用正则表达式,页面解析库进行解析,可能是Json,可以直接转换为Json对象解析,可能是二进制数据,可以做保存或者进一步的处理
保存数据
保存形式多样,可以存为文本,也可以保存到数据库,或者保存特定格式的文件
详情请看http://www.cnblogs.com/alex3714/articles/8359348.html
什么是Urllib库
Urllib是Python提供的一个用于操作URL的模块,我们爬取网页的时候,经常需要用到这个库。
升级合并后,模块中的包的位置变化的地方较多。在此,列举一些常见的位置变动,方便之前用Python2.x的朋友在使用Python3.x的时候可以快速掌握。
常见的变化有:
- 在Pytho2.x中使用import urllib2——-对应的,在Python3.x中会使用import urllib.request,urllib.error。
- 在Pytho2.x中使用import urllib——-对应的,在Python3.x中会使用import urllib.request,urllib.error,urllib.parse。
- 在Pytho2.x中使用import urlparse——-对应的,在Python3.x中会使用import urllib.parse。
- 在Pytho2.x中使用import urlopen——-对应的,在Python3.x中会使用import urllib.request.urlopen。
- 在Pytho2.x中使用import urlencode——-对应的,在Python3.x中会使用import urllib.parse.urlencode。
- 在Pytho2.x中使用import urllib.quote——-对应的,在Python3.x中会使用import urllib.request.quote。
- 在Pytho2.x中使用cookielib.CookieJar——-对应的,在Python3.x中会使用http.CookieJar。
- 在Pytho2.x中使用urllib2.Request——-对应的,在Python3.x中会使用urllib.request.Reques
urllib.request 请求模块
urllib.error 异常处理模块
urllib.parse url解析模块
urllib.robotparser robots.txt解析模块
先进行一个简单的实例:利用有道翻译(post请求)
1 #引入模块 2 import urllib.request 3 import urllib.parse 4 5 6 #URL选好非常重要,选不好将会出错 7 url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' 8 9 10 ''' 11 设置Headers 12 有很多网站为了防止程序爬虫爬网站造成网站瘫痪,会需要携带一些headers头部信息才能访问,最长见的有user-agent参数 13 ''' 14 headers = { 15 'Accept': 'application/json, text/javascript, */*; q=0.01', 16 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 17 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36', 18 'X-Requested-With':'XMLHttpRequest' 19 } 20 21 key = input('enter your word:\n') 22 23 form_data = { 24 'i': key, 25 'from':'AUTO', 26 'to':'AUTO', 27 'keyfrom':'fanyi.web', 28 'doctype':'json', 29 'version':'2.1', 30 'action':'FY_BY_REALTIME', 31 'typoResult':'flase' 32 } 33 34 35 36 ''' 37 这里用到urllib.parse,通过urllib.parse.urlencode(form_data).encode(encoding='utf-8')可以将post数据进行转换放到urllib.request.urlopen的data参数中。这样就完成了一次post请求。 38 所以如果我们添加data参数的时候就是以post请求方式请求,如果没有data参数就是get请求方式 39 ''' 40 data =urllib.parse.urlencode(form_data).encode(encoding='utf-8') 41 42 request = urllib.request.Request(url, data=data , headers=headers) 43 44 45 ''' 46 urlopen一般常用的有三个参数,它的参数如下:urllib.requeset.urlopen(url,data,timeout) 47 48 当然上述的urlopen只能用于一些简单的请求,因为它无法添加一些header信息,很多情况下我们是需要添加头部信息去访问目标站的,这个时候就用到了urllib.request 49 50 51 52 ''' 53 response = urllib.request.urlopen(request) 54 55 #response.read()可以获取到网页的内容 56 result = response.read().decode('utf8') 57 #target = json.loads(result) 58 #target = urllib.parse.unquote(target) 59 #print(target['translateResult'][0][0]["tgt"]) 60 #a = target['translateResult'][0][0]["tgt"] 61 #print(type(a)) 62 #print(a) 63 print(result) 64 #print(target)
运行结果:
enter your words: I love python {"type":"EN2ZH_CN", "errorCode":0, "elapsedTime":1, "translateResult":[[{"src":"I love python", "tgt":"我喜欢python"}]] }
另外一个简单的小实例是:豆瓣网剧情片排名前20的电影(Ajax请求)
1 import urllib.request 2 import urllib.parse 3 import json 4 5 url = 'https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action' 6 7 headers = { 8 'Accept': ' */*', 9 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36', 10 'X-Requested-With':'XMLHttpRequest' 11 } 12 13 form_data = { 14 'start': '0', 15 'limit': '20' 16 } 17 18 data =urllib.parse.urlencode(form_data).encode(encoding='utf-8') 19 request = urllib.request.Request(url, data=data , headers=headers) 20 response = urllib.request.urlopen(request) 21 result = response.read() 22 targets = json.loads(result) 23 24 #print(result) 25 for num,target in enumerate(targets): 26 print(num+1, target["title"])
运行结果:
1 肖申克的救赎 2 控方证人 3 霸王别姬 4 美丽人生 5 这个杀手不太冷 6 阿甘正传 7 辛德勒的名单 8 十二怒汉 9 泰坦尼克号 3D版 10 十二怒汉 11 控方证人 12 盗梦空间 13 灿烂人生 14 茶馆 15 背靠背,脸对脸 16 巴黎圣母院 17 三傻大闹宝莱坞 18 千与千寻 19 泰坦尼克号 20 海上钢琴师
这些只是一些简单的运用。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号