自动化基础0813
# md5加密
import hashlib
# md5加密
# 加盐值:可以是字符串,可以是数字/时间戳或者随机数
def get_md5_data(data, salt=''):
md5 = hashlib.md5()
data = f"{data}{salt}"
md5.update(data.encode('utf-8'))
return md5.hexdigest()
RSA非对称加密
客户端拿到公钥,使用对应的函数把明文数据加密。
public.pem文件里存放公钥
外面系统接口自动化封装
-
公共的发送请求的方法
-
URL和请求方式做成配置文件
- cnf
- ini
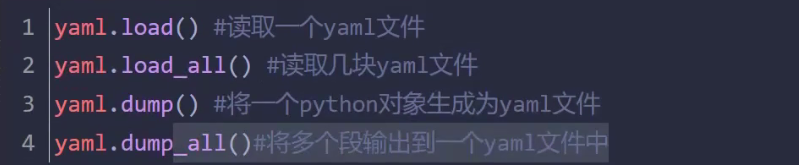
- yaml(推荐)
- xml
yaml配置文件
pip install pyyaml
YAML有以下基本规则:
1、大小写敏感
2、使用缩进表示层级关系
3、禁止使用tab缩进,只能使用空格键
4、缩进长度没有限制,只要元素对齐就表示这些元素属于一个层级。
5、使用#表示注释
6、字符串可以不用引号标注
**kwargs
# **kwargs,不使用*args,可以避免参数的传递的顺序
# 在函数定义的时候,该函数里面,会吧用户传递的参数a=100.b=200 封装成字典{'a':'100','b':'200'} --装包
# 在函数调用的时候,使用**变量,会把传递的字典 {'a':'100','b':'200'}变成a=100.b=200 --解包
def func(*args, **kwargs): # 装包
print(args)
print(kwargs)
func(*(11, 22, 33), **{"a": 100, "b": 200}) # 拆包
inspect
inspect.``trace(context=1)¶
返回介于当前帧和引发了当前正在处理的异常的帧之间的所有帧记录的列表。列表中的第一条记录代表调用者;最后一条记录代表了引发异常的地方。
自动化测试流程
- 基类封装--基本功能,后续还需要优化
- 请求封装
- md5加密
- 登陆接口调试完成
- 需要登陆接口的测试用例 excel yaml
- 使用python去读取对应的用例数据 ,简单---进阶---高阶用法
- 引入框架执行
- 执行测试用例
- 报告
项目测试用例设计+执行Excel测试用例

xlrd .xls
openpyxl .xlsx
涉及到用例的结构
手工测试===>给人看
自动化测试用例===>给代码/工具看
excel:功能测试(描述型)---变成---自动化测试(数据型)
接口自动化测试用例要素
- 用例编号
- 模块
- 接口名称
- 优先级
- 标题
- URI
- 前置条件
- 请求方法
- 请求头
- 请求参数
- 预期结果
- 实际结果
从excel用例里读取数据
方案一:
import xlrd
def get_excel_data(file_path, sheet_name):
# 打开工作簿
work_book = xlrd.open_workbook(file_path, formatting_info=True) # formatting_info=True保持文件格式
# 找到工作表sheet
# print(work_book.sheet_names()) # 找到所以工作表
work_sheet = work_book.sheet_by_name(sheet_name)
# 获取一行数据
# print(work_sheet.row_values(0)) # 第一行
# 获取一列数据
# print(work_sheet.col_values(0)) # 第一列
# 获取单元格数据
# print(work_sheet.cell(0, 0).value) # 第1行,第1列
# 获取对应的数据
# req_body = work_sheet.cell(1, 9).value # 请求体数据
# res_data = work_sheet.cell(1, 11).value # 预期响应数据
# 方案一:求总行号,较笼统,不能避免excel写错的数据
# 方案二:对列做遍历,做过滤
row_index = 0 # 初始行
res_list = []
for i in work_sheet.col_values(0): # i第1列的的每个数据
req_body = work_sheet.cell(row_index, 9).value # 请求体数据
res_data = work_sheet.cell(row_index, 11).value # 预期响应数据
row_index += 1 #
res_list.append((req_body, res_data))
print(res_list)
for i in res_list:
print(i)
if __name__ == '__main__':
get_excel_data('../data/Delivery_System_V1.5.xls', '登录模块')
"""
测试反馈:
1- 如果测试的店铺模块的列出店铺接口,使用这个代码获取到所有的用例的数据,不是列出接口的用例会报错
2- 后续自动化测试需要的内容,用例描述,必须改代码
优化方案:
1- 采取标识去识别这个接口对应的测试用例
2- 9.11 获取数据的需求不固定 可能根据场景来, *args
"""
方案优化
import xlrd
import json
# 直接让用户传递对应的列编号
def get_excel_data(file_path, sheet_name, case_name, *args, run_case=None):
print(args) # ()args装包成元祖
# print(kwargs) # ()kwargs 装包成字典
# 打开工作簿
work_book = xlrd.open_workbook(file_path, formatting_info=True) # formatting_info=True保持文件格式
# 找到工作表sheet
# print(work_book.sheet_names()) # 找到所以工作表
work_sheet = work_book.sheet_by_name(sheet_name)
# 获取一行数据
# print(work_sheet.row_values(0)) # 第一行
# 获取一列数据
# print(work_sheet.col_values(0)) # 第一列
# 获取单元格数据
# print(work_sheet.cell(0, 0).value) # 第1行,第1列
# -------化抽象为具体---------
# args=('URI','请求头数据')
# 目标:吧列名变成列编号
col_index_list = []
for col_name in args:
col_index_list.append(work_sheet.row_values(0).index(col_name)) # 列表没有find方法,只有index方法
print('需要获取的列编号是--->', col_index_list) # [5, 7]
# ---------------用例筛选-------------------
# 抽象---具体化: run_case=['all','001',003-005','007']
run_case_list = [] # 最终执行测试用例的编号
# 1.全选用例
if run_case is None or 'all' in run_case:
run_case_list = work_sheet.col_values(0) # ['Login001','Login002']
else: # 不是全部选择
for one in run_case:
if '-' in one: # 连续的用例 '003-005' 'Login003,Login004,Login005'
start, end = one.split('-') # start==003 end==005
for num in range(int(start), int(end) + 1):
# 把3,4,5变为'Login003,Login004,Login005'
run_case_list.append(f'{case_name}{num:0>3}') # num是3 num:0>3 右对齐补三位置,补0
else: # 单个的用例
run_case_list.append(f'{case_name}{one:0>3}')
print('运行的测试用例--->', run_case_list)
# -------------------------------------------
# 获取对应的数据
# req_body = work_sheet.cell(1, 9).value # 请求体数据
# res_data = work_sheet.cell(1, 11).value # 预期响应数据
# 方案一:求总行号,较笼统,不能避免excel写错的数据
# 方案二:对列做遍历,做过滤
row_index = 0 # 初始行
res_list = []
for one in work_sheet.col_values(0): # one第1列的的每个数据
if case_name in one and one in run_case_list: # case_name 取用例编号里的数据进行过滤
# req_body = work_sheet.cell(row_index, 9).value # 请求体数据
# res_data = work_sheet.cell(row_index, 11).value # 预期响应数据
col_data = []
for num in col_index_list:
tmp = is_json(work_sheet.cell(row_index, num).value)
col_data.append(tmp)
res_list.append(tuple(col_data)) # 列表套元祖
row_index += 1
print('使用的excel用例数据---->', res_list)
for i in res_list:
print('使用的excel用例数据分别为--->', i)
def is_json(data):
"""
:param data: 是否为json被判断的数据
:return:
- 字典
- 字符串
"""
try:
return json.loads(data) # 直接转成字典
except:
return data
if __name__ == '__main__':
get_excel_data('../data/Delivery_System_V1.5.xls', '登录模块', "Login", '标题', '请求参数',
run_case=['001', '003-005', '006'])
"""
测试反馈1:
1- 如果测试的店铺模块的列出店铺接口,使用这个代码获取到所有的用例的数据,不是列出接口的用例会报错
2- 后续自动化测试需要的内容,用例描述,必须改代码
优化方案:
1- 采取标识去识别这个接口对应的测试用例
2- 9.11 获取数据的需求不固定 可能根据场景来, *args
"""
'''
测试反馈2:
1-请求体数据:登陆接口的类型是 json字符串,登陆接口需要啥 代码里请求体都需要字典格式
- 如果是json,就转为字典
- 如果不是json,不能转
2-当前的数据是获取接口所有的用例,给pytest 没有办法做到用例的指定执行 优化:选指定的用例去执行
优化方案:
1-用例筛选 1 2 3 4 5
场景:
- 1.全部运行 all
- 2.运行单个 1
- 3.几个连续的 3 4 5
- 4.混合筛选 12 3 5
- 5.不连续 1 3 5
测试人员如何去传递这个筛选 *args **kwargs---做配置层 yaml
'''
pytest
pytest安装
pip install pytest
pip install pytest-html 原生态报告模板
查看pytest是否安装成功
pip show pytest
pytest的init配置可以修改
- pytest测试文件必须以test开头或结尾
- 测试类必须以Test开头,并且不能有init方法
- 测试方法必须以test开头
- 断言必须使用assert
数据驱动
-
关键字驱动
-
行为驱动
-
数据驱动
data driver testing ddt
测试数据与功能函数分离,运行自动化测试时,框架会读取数据源的数据,把数据作为参数传递到功能函数中。由于一般测试用例覆盖多条不同输入,根据不同的前置条件选取多条数据执行多次同一功能函数,这样可以减少重复代码,不同测试条件之间的测试结果互相不影响,这就是数据驱动
yaml配置
一、简介
YAML 语言(发音 /ˈjæməl/ )的设计目标,就是方便人类读写。它实质上是一种通用的数据串行化格式。
它的基本语法规则如下。
- 大小写敏感
- 使用缩进表示层级关系
- 缩进时不允许使用Tab键,只允许使用空格。
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
# 表示注释,从这个字符一直到行尾,都会被解析器忽略。
YAML 支持的数据结构有三种。
- 对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary)
- 数组:一组按次序排列的值,又称为序列(sequence) / 列表(list)
- 纯量(scalars):单个的、不可再分的值
以下分别介绍这三种数据结构。
二、对象
对象的一组键值对,使用冒号结构表示。
animal: pets
转为 JavaScript 如下。
{ animal: 'pets' }
Yaml 也允许另一种写法,将所有键值对写成一个行内对象。
hash: { name: Steve, foo: bar }
转为 JavaScript 如下。
{ hash: { name: 'Steve', foo: 'bar' } }
三、数组
一组连词线开头的行,构成一个数组。
- Cat - Dog - Goldfish
转为 JavaScript 如下。
[ 'Cat', 'Dog', 'Goldfish' ]
数据结构的子成员是一个数组,则可以在该项下面缩进一个空格。
- - Cat - Dog - Goldfish
转为 JavaScript 如下。
[ [ 'Cat', 'Dog', 'Goldfish' ] ]
数组也可以采用行内表示法。
animal: [Cat, Dog]
转为 JavaScript 如下。
{ animal: [ 'Cat', 'Dog' ] }
四、复合结构
对象和数组可以结合使用,形成复合结构。
languages: - Ruby - Perl - Python websites: YAML: yaml.org Ruby: ruby-lang.org Python: python.org Perl: use.perl.org
转为 JavaScript 如下。
{ languages: [ 'Ruby', 'Perl', 'Python' ], websites: { YAML: 'yaml.org', Ruby: 'ruby-lang.org', Python: 'python.org', Perl: 'use.perl.org' } }
五、纯量
纯量是最基本的、不可再分的值。以下数据类型都属于 JavaScript 的纯量。
- 字符串
- 布尔值
- 整数
- 浮点数
- Null
- 时间
- 日期
数值直接以字面量的形式表示。
number: 12.30
转为 JavaScript 如下。
{ number: 12.30 }
布尔值用true和false表示。
isSet: true
转为 JavaScript 如下。
{ isSet: true }
null用~表示。
parent: ~
转为 JavaScript 如下。
{ parent: null }
时间采用 ISO8601 格式。
iso8601: 2001-12-14t21:59:43.10-05:00
转为 JavaScript 如下。
{ iso8601: new Date('2001-12-14t21:59:43.10-05:00') }
日期采用复合 iso8601 格式的年、月、日表示。
date: 1976-07-31
转为 JavaScript 如下。
{ date: new Date('1976-07-31') }
YAML 允许使用两个感叹号,强制转换数据类型。
e: !!str 123 f: !!str true
转为 JavaScript 如下。
{ e: '123', f: 'true' }
六、字符串
字符串是最常见,也是最复杂的一种数据类型。
字符串默认不使用引号表示。
str: 这是一行字符串
转为 JavaScript 如下。
{ str: '这是一行字符串' }
如果字符串之中包含空格或特殊字符,需要放在引号之中。
str: '内容: 字符串'
转为 JavaScript 如下。
{ str: '内容: 字符串' }
单引号和双引号都可以使用,双引号不会对特殊字符转义。
s1: '内容\n字符串' s2: "内容\n字符串"
转为 JavaScript 如下。
{ s1: '内容\\n字符串', s2: '内容\n字符串' }
单引号之中如果还有单引号,必须连续使用两个单引号转义。
str: 'labor''s day'
转为 JavaScript 如下。
{ str: 'labor\'s day' }
字符串可以写成多行,从第二行开始,必须有一个单空格缩进。换行符会被转为空格。
str: 这是一段 多行 字符串
转为 JavaScript 如下。
{ str: '这是一段 多行 字符串' }
多行字符串可以使用|保留换行符,也可以使用>折叠换行。
this: | Foo Bar that: > Foo Bar
转为 JavaScript 代码如下。
{ this: 'Foo\nBar\n', that: 'Foo Bar\n' }
+表示保留文字块末尾的换行,-表示删除字符串末尾的换行。
s1: | Foo s2: |+ Foo s3: |- Foo
转为 JavaScript 代码如下。
{ s1: 'Foo\n', s2: 'Foo\n\n\n', s3: 'Foo' }
字符串之中可以插入 HTML 标记。
message: | <p style="color: red"> 段落 </p>
转为 JavaScript 如下。
{ message: '\n<p style="color: red">\n 段落\n</p>\n' }
七、引用
锚点&和别名*,可以用来引用。
defaults: &defaults adapter: postgres host: localhost development: database: myapp_development <<: *defaults test: database: myapp_test <<: *defaults
等同于下面的代码。
defaults: adapter: postgres host: localhost development: database: myapp_development adapter: postgres host: localhost test: database: myapp_test adapter: postgres host: localhost
&用来建立锚点(defaults),<<表示合并到当前数据,*用来引用锚点。
下面是另一个例子。
- &showell Steve - Clark - Brian - Oren - *showell
转为 JavaScript 代码如下。
[ 'Steve', 'Clark', 'Brian', 'Oren', 'Steve' ]
八、函数和正则表达式的转换
这是 JS-YAML 库特有的功能,可以把函数和正则表达式转为字符串。
# example.yml fn: function () { return 1 } reg: /test/
解析上面的 yml 文件的代码如下。
var yaml = require('js-yaml'); var fs = require('fs'); try { var doc = yaml.load( fs.readFileSync('./example.yml', 'utf8') ); console.log(doc); } catch (e) { console.log(e); }
从 JavaScript 对象还原到 yaml 文件的代码如下。
var yaml = require('js-yaml'); var fs = require('fs'); var obj = { fn: function () { return 1 }, reg: /test/ }; try { fs.writeFileSync( './example.yml', yaml.dump(obj), 'utf8' ); } catch (e) { console.log(e); }
allure报告
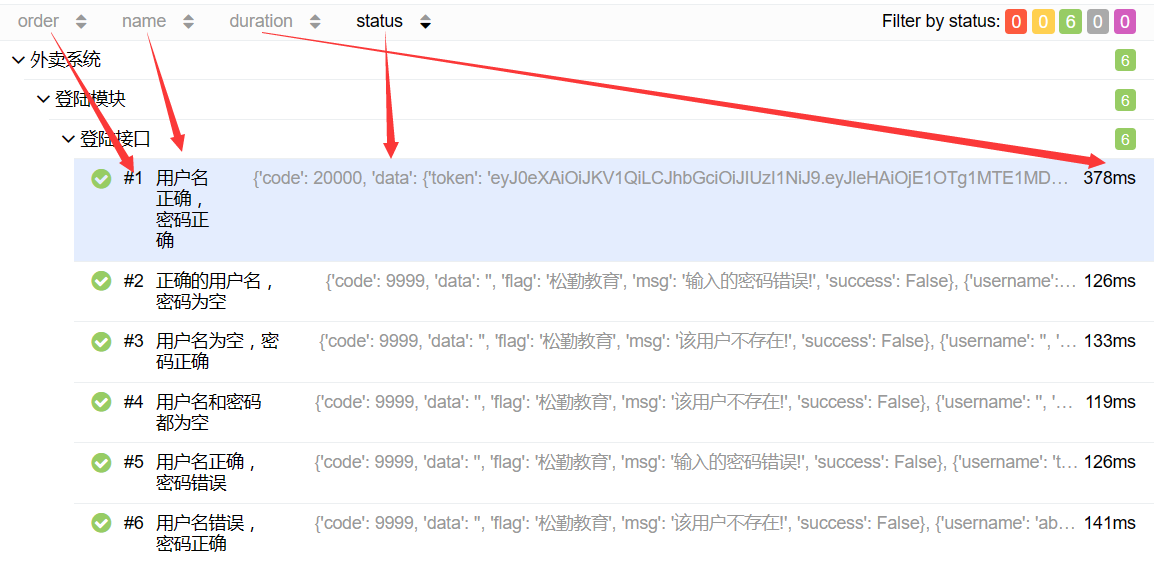
pytest传参
@pytest.mark.parametrize('req_body,exp_data', get_excel_data('登录模块', "Login")) # 变量 值
- @allure.epic('外卖系统') # 项目级别
- @allure.feature('登陆模块') # 登陆模块
- @allure.story('登陆接口') #方法级别
- @allure.title('{title}') #用例级别
生成报告
if __name__ == '__main__':
pytest.main([__file__, '-s', '--alluredir=../outFiles/report/tmp', '--clean-alluredir'])
os.system('allure serve ../outFiles/report/tmp')
import pytest
from libs.login import Login
from utils.handle_excel import get_excel_data
import os
import allure
@allure.feature('登陆模块') # 登陆模块
@allure.epic('外卖系统') # 项目级别
# 创建测试类(pytest不能继承)
class TestLogin:
@pytest.mark.parametrize('title,req_body,exp_data', get_excel_data('登录模块', "Login")) # 变量 值
@allure.story('登陆接口') # 方法级别
@allure.title('{title}') # 用例级别
# print(get_excel_data('登录模块', "Login"))
# 创建测试方法-对接口的测试
def test_login(self, title, req_body, exp_data):
# 调用登陆业务接口
res = Login().login(req_body)
# 断言 实际与预期是否一致 找关键信息进行断言
assert res['msg'] == exp_data['msg']
if __name__ == '__main__':
pytest.main([__file__, '-s', '--alluredir=../outFiles/report/tmp', '--clean-alluredir'])
os.system('allure serve ../outFiles/report/tmp')
"""
allure报告原理
现成的报告模板,如果需要这个接口的报告,需要给他对应的测试结果的数据
- 1.pytest运行完成需要生成对应测试结果的数据 xxx.json
- 2.需要使用allure的指令去读取并生成对应的报告
"""
店铺业务
token在基类里封装
增删改查作为公共方法也封装到基类里。再子类去继承。如果父类的方法满足,就直接继承。如果有差异,就重写方法。
-----------------------------186921245237920887921379734591
Content-Disposition: form-data; name="file"; filename="OIP-C.jpg"
Content-Type: image/jpeg
查询接口
更新编辑接口
更新接口的主接口需要用到图片上传的接口的一些响应字段
fixture

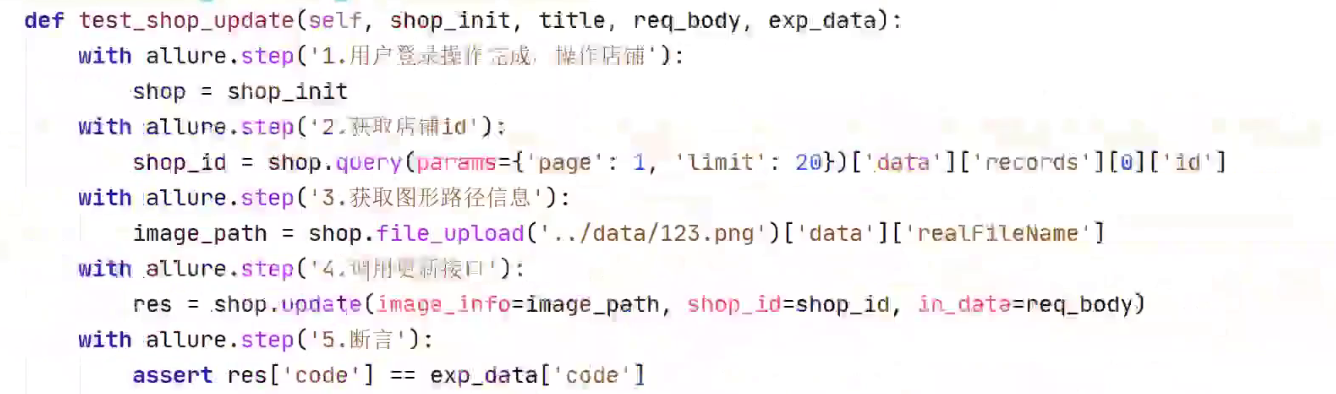
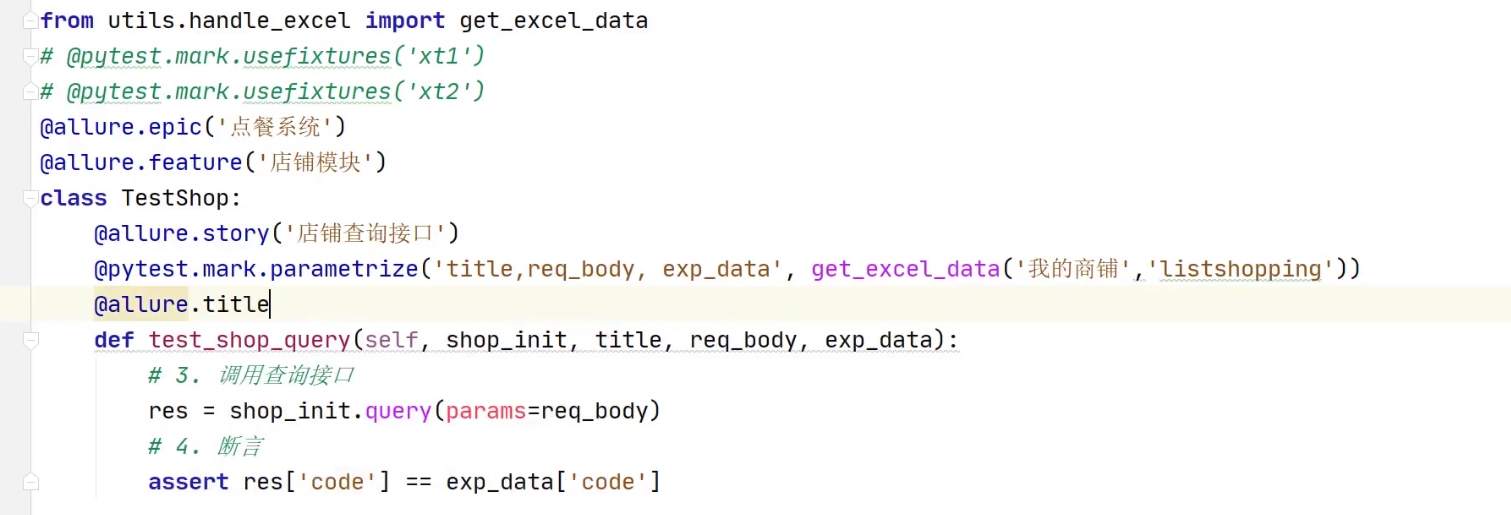
路径处理
import os
print(__file__)
# 获取上一层目录
project_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 防止反斜杠问题
# 数据文件路径
data_path = os.path.join(project_path, 'data')
# print(data_path)
# 配置路径
config_path = os.path.join(project_path, 'configs')
# 报告路径
report_path = os.path.join(project_path, r'outFiles\report\temp')
pytest编码处理
'''
当一个接口,需要多个关联的前置条件
如何关联2个fixture ,把上一个fixture函数返回值给下一个fixture 使用
1-如果需要使用fixture的函数的返回值,可以直接使用fixture的函数名
2-没有返回值,使用fixture.usefixture
with allure.step('第一步干嘛,第二步干嘛,一步步写'):
'''
def pytest_collection_modifyitems(items):
"""
测试用例收集完成时,将收集到的item的name和nodeid的中文显示在控制台上
"""
for item in items:
item.name = item.name.encode("utf-8").decode("unicode_escape")
item._nodeid = item.nodeid.encode("utf-8").decode("unicode_escape")
pytest -s #在项目目录下全部运行
run.bat

pytest-sugar糖果库

用例定制化执行
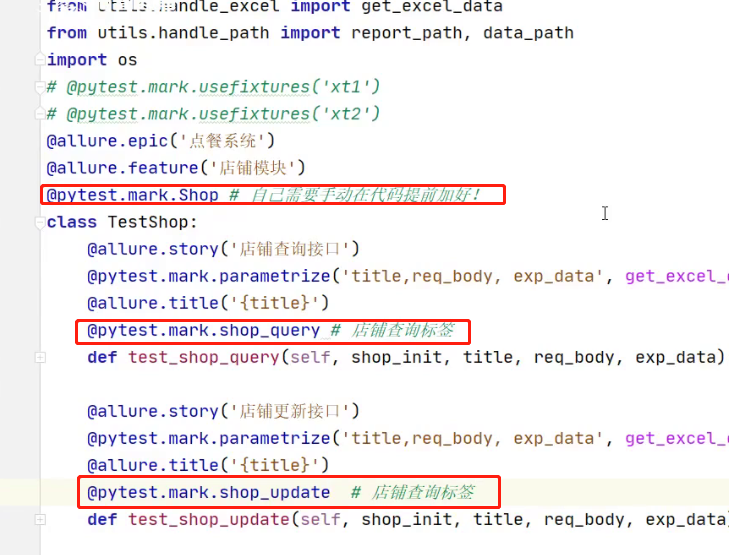

打标签,只管接口层
ddt来选择执行的用例数据
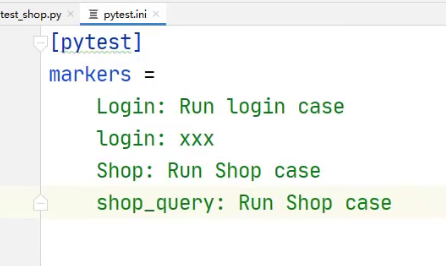
去除打完标签的警告

可以筛选模块的接口层,也可以筛选模块层
-
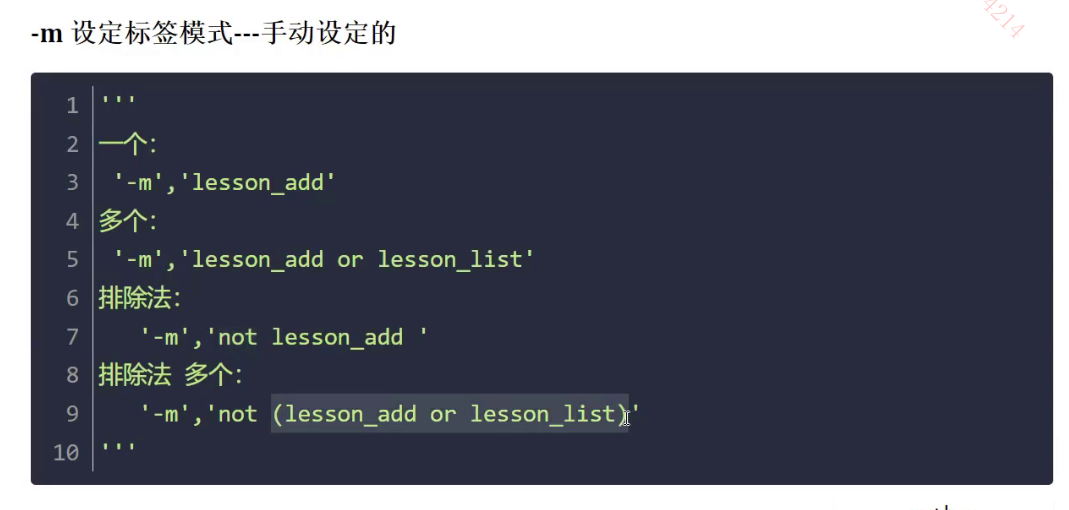
-m :纯手工
- 每一个模块和接口都需要自己去规划好,标签名也需要自己去写
- 需要再pytest.ini提前写标签
- 可以结合 逻辑运算符
- 指令调用:pytest -s -m 标签名
-
-k 可以模糊匹配
- 可以筛选模块里的接口执行
- 也可以筛选对于的模块执行
-
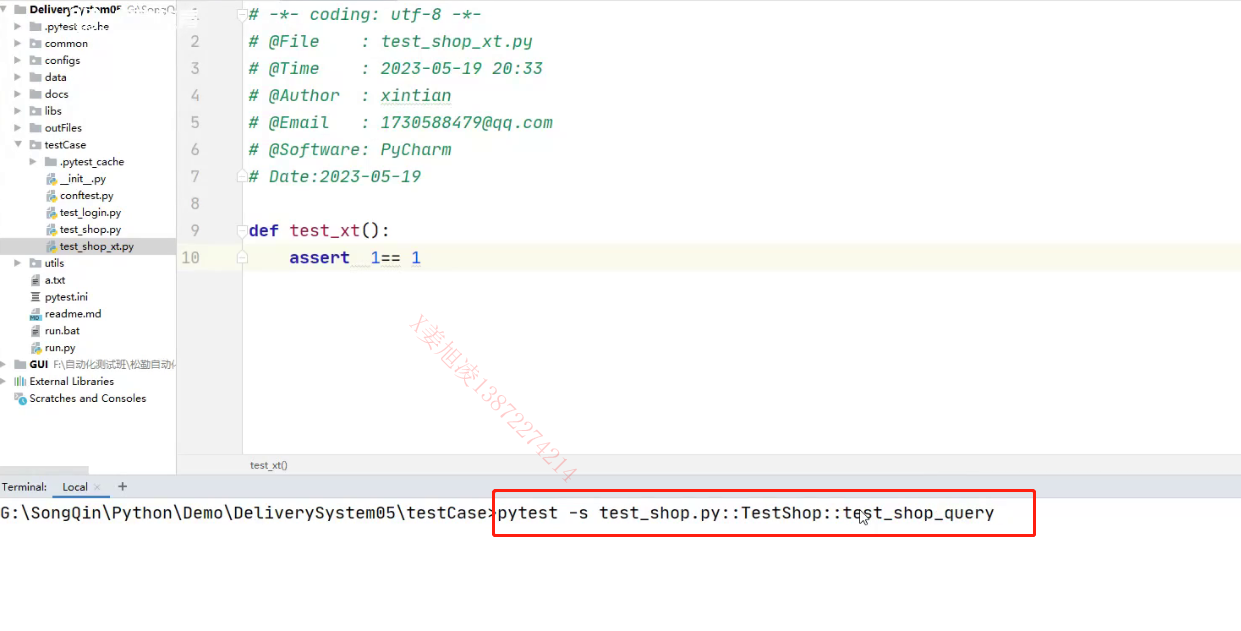
层级关系写法:
-
pytest -s 测试文件名::测试类名名::测试方法名
-
直接注释相关测试代码
-
skip
- 强制跳过
- skipif
-

yaml文件
-
mock

模拟一个假的后端

 浙公网安备 33010602011771号
浙公网安备 33010602011771号