
大模型入门(五)—— 基于peft微调ChatGLM模型
ChatGLM 是基于 General Language Model (GLM) 架构,针对中文问答和对话进行了优化。经过中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术,ChatGLM因为是中文大模型,在中文任务的表现要优于LLaMa,我在一些实体抽取的任务中微调ChatGLM-6B,都取得了很不错的效果。
GLM: General Language Model Pretraining with Autoregressive Blank Infilling
在微调ChatGLM之前,先简单地了解下它的基础模型GLM,GLM也是基于transformer架构的,在训练任务上构造了自回归的空格填充任务,具体的训练流程如下图所示:
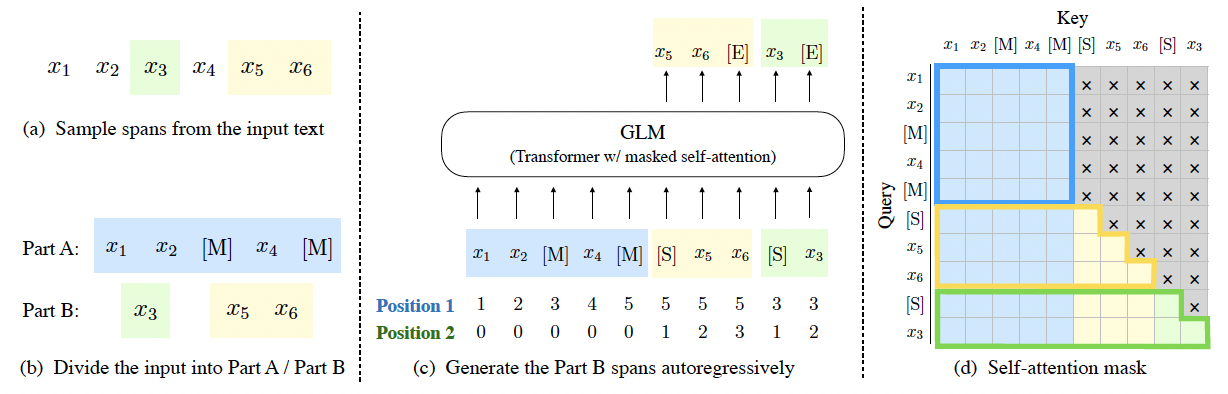
a) 随机抽取句子中的一些片段。
b) 将原句子和抽取的片段分离,并将原句子中被抽离的片段的位置用mask标记符替换。
c) 将抽取的片段随机打乱拼接在原句子后面,句子和片段,片段和片段之间用起始符连接,使用自回归的训练方式去预测抽取的片段。
d) 训练时原句子使用双向attention,如transformer encoder,图d中的蓝色部分,片段使用单向attention,如transformer decoder。
从上面来看训练过程和之前的模型大同小异,不知道较现在大模型通用的decoder-only有没有什么优势。
ChatGLM微调
1、源代码准备
ChatGLM目前的代码没有集成到transformers库中,作者将基于transformers实现的代码和模型文件放到了一起,模型文件和代码见https://huggingface.co/THUDM/chatglm-6b/tree/main,可以通过transformers中的Autoxxx类加载。也可以把代码直接拿出来调用,需要用到的代码有modeling_chatglm.py, tokenization_chatglm.py, configuration_chatglm.py。
2、数据和模型准备
使用的大模型:https://huggingface.co/THUDM/chatglm-6b
微调数据集:https://github.com/LC1332/Chinese-alpaca-lora/blob/main/data/trans_chinese_alpaca_data.json
微调的代码已上传到github:https://github.com/jiangxinyang227/LLM-tuning/tree/master/chatglm_tuning
3、训练方式
训练方式参考大模型入门(四)—— 基于peft 微调 LLaMa模型
值得注意的是,在使用deepspeed训练时,在加载chatglm模型时需要注意,chatglm模型加载默认是使用pytorch中的skip_init初始化,会将参数先加载到meta device上,这种情况就无法使用deepspeed。需要修改的代码是在加载模型时将empty_init设置为False即可。
model = ChatGLMForConditionalGeneration.from_pretrained( Config.base_model, empty_init=False, torch_dtype=torch.float16 )

 浙公网安备 33010602011771号
浙公网安备 33010602011771号