多模态预训练模型(一)
随着预训练和transformer模型在自然语言处理领域大放异彩后,多模态领域也逐渐被应用起来。近两年来围绕着基于transformer的多模态预训练模型也越来越多。多模态即多种异构模态的数据,文本、图片、语音等。以最常见的文本、图片应用来讨论,文本、图片也是目前研究最多的多模态领域。
多模态预训练模型按照模型结构可以分为单流和双流两种结构。单流是指图片和文本在embedding之后就融合在一起进入后续的transformer层,双流是指文本和图片单独享有自己的transformer层,只在最后做轻量的融合。现有的多模态预训练模型都跳不出这两种结构,更多的多模态预训练模型在预训练任务上下功夫、引入更多的预训练任务,设计统一的架构去训练所有的任务等等。除此之外,图片的embedding也有会不同的方式。
一、多模态预训练模型结构
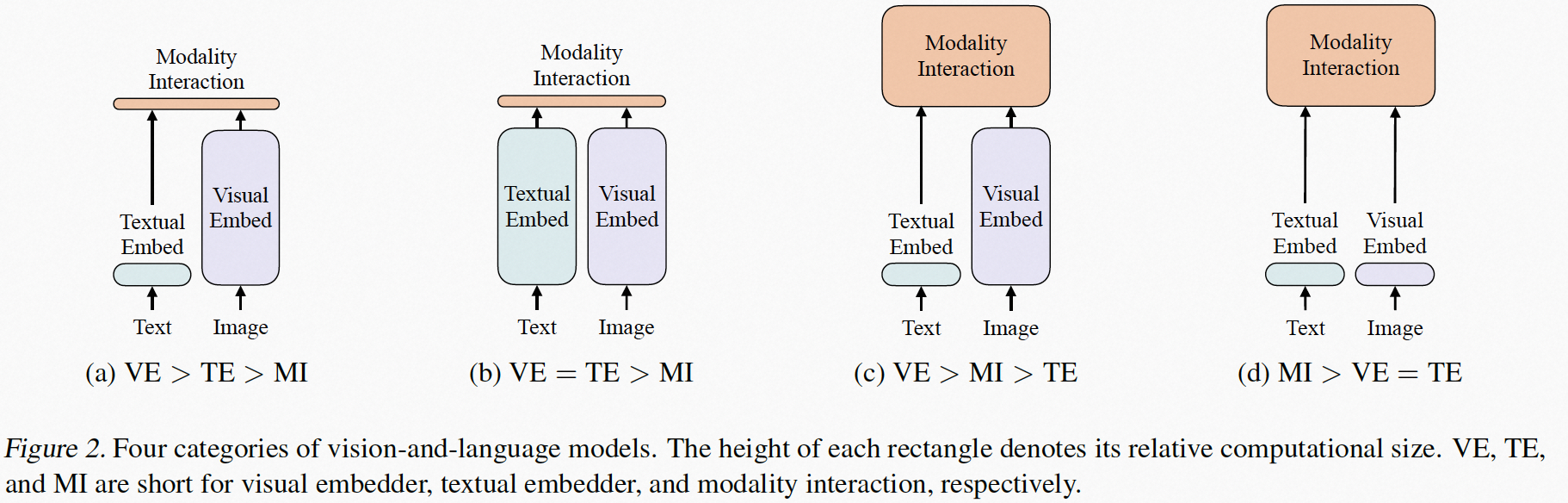
套用VILT论文中的一张图, 图a和b是双流结构,它们的Modality Interaction层是比较浅的,这种结构的优点的在下游使用时,尤其是图文匹配的任务中,两个模态单独处理的部分可以离线跑、线上只加载交互的部分,减轻线上的计算压力。缺点是两个模态的信息交互不足,可能效果上有所欠缺。而单流结构就恰恰相反。
二、图像处理模块
transformer结构接受的是二维的数据,你需要将一张图片转换成序列数据输出到transformer中,通常的方式有三种:object detector,patch, pixel。
object detector:使用Faster R-CNN抽取出图片中有用的目标,将每个目标看作一个token。
patch: 将图片划分成N个P×P的patch,然后每个patch可以展开成一维经过线性变换得到一个patch embedding,也可以每个patch过CNN网络得到一个patch embedding,这个也是现在最常用的方法。
pixel: 图片先过CNN模块得到更多的高阶特征,然后再feature map上随机取一个pixel作为token,输入到transformer结构中。
三、模型简介
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
Vilt是在Vit的基础上设计的多模态预训练模型,图片使用Vit中的patch embedding的方式,采用单流结构。预训练任务有图文匹配、Mask language model、word patch align。
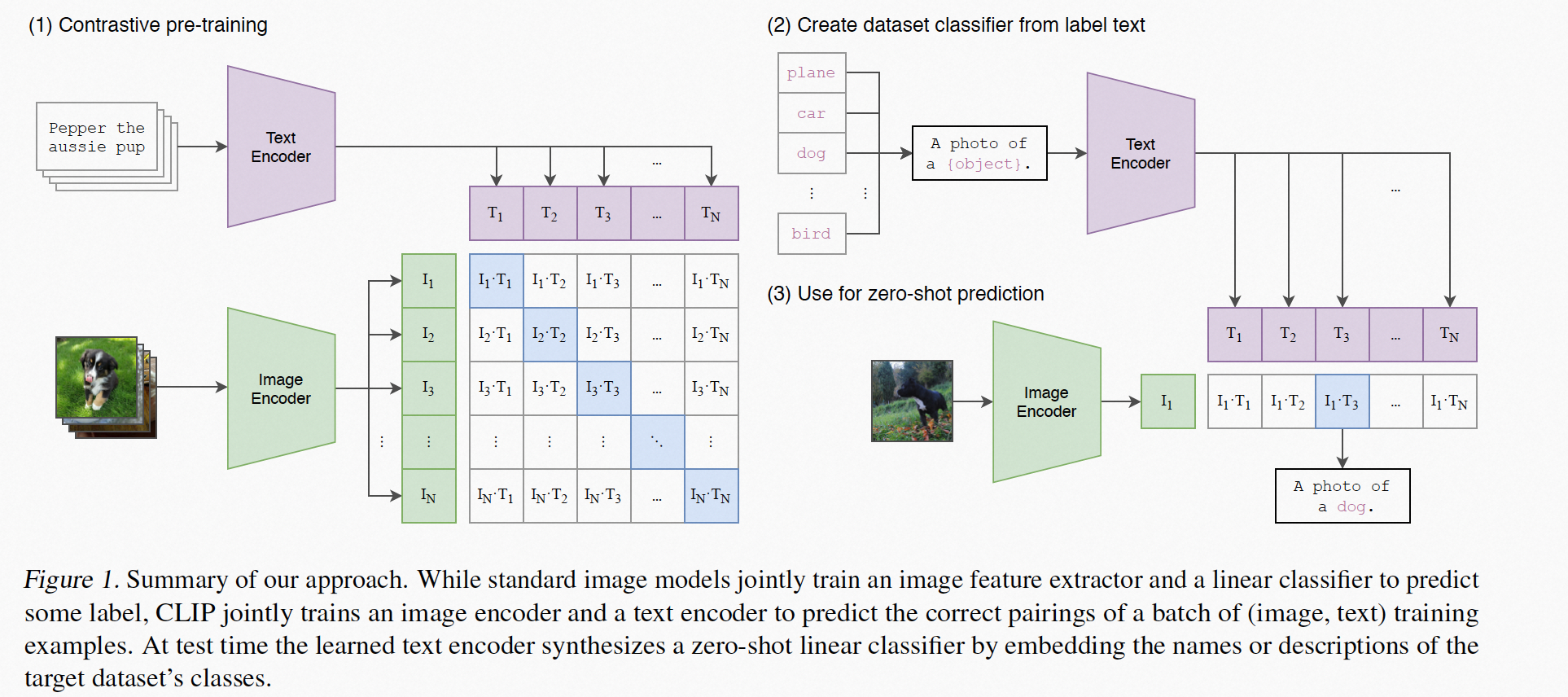
CLIP:Learning Transferable Visual Models From Natural Language Supervision
CLIP是一个很经典的工作,通过图文对自监督训练模型,在zero-shot场景下效果也很好,CLIP中的zero-shot需要人工输入一些指示信息,而这些指示信息会被模型和图片结合在一起,所以说在CLIP中引入了自然语言的监督信息,相较于imagenet不在是单一维度的类别标签信息,会涵盖多个维度的概念。CLIP是一个双流结构的模型,图文的输出会经过一个线性变换到同一空间、然后计算余弦距离,最后在in-batch下计算交叉熵。
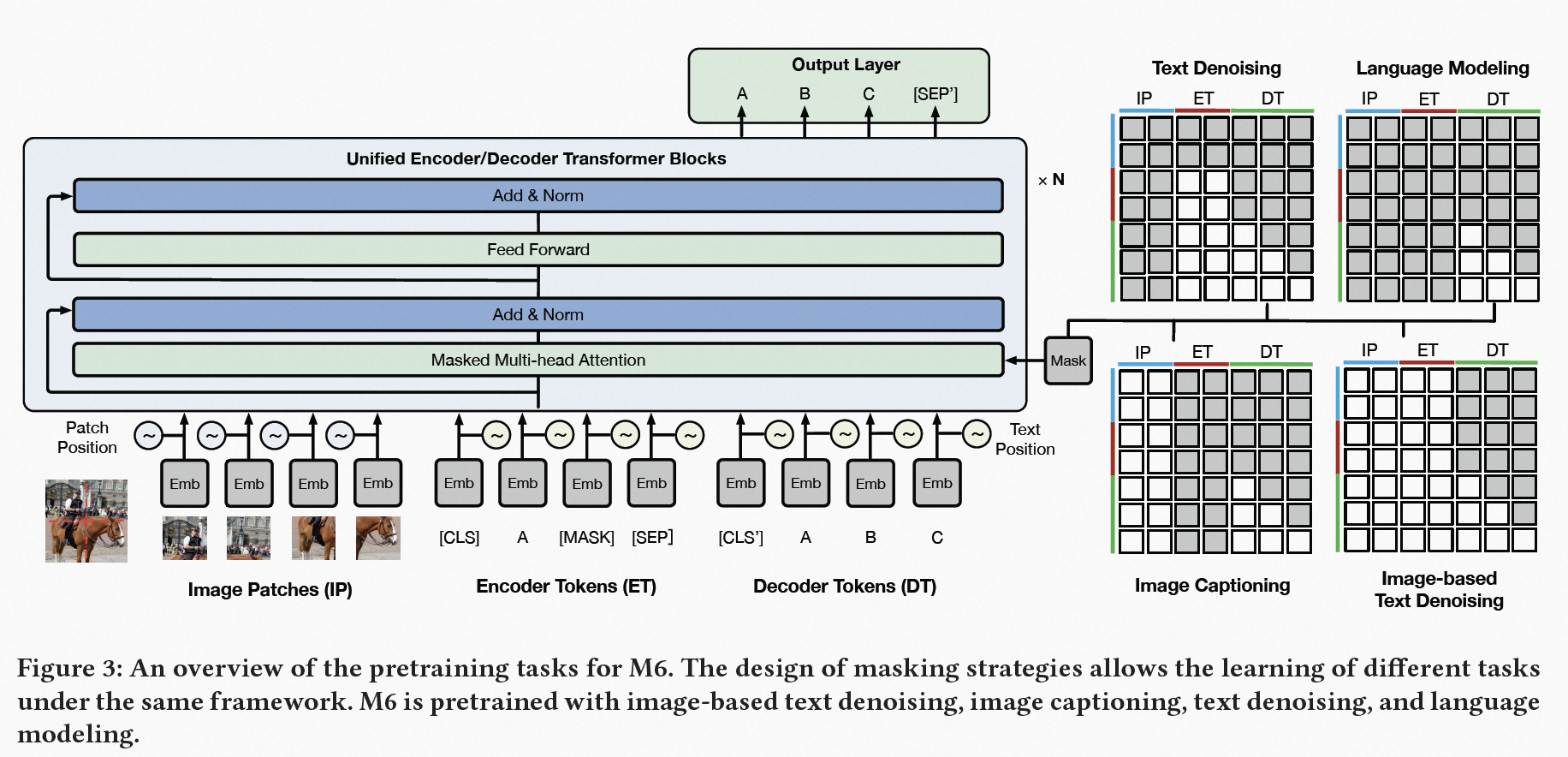
M6: A Chinese Multimodal Pretrainer
M6用一个生成的结构统一了理解任务和生成任务。类似于NLP中的UniLM。让模型既可以做理解任务,也可以做生成任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号