
图像经典模型(一)
1、概述
本文想简单的记述下在CV领域经典模型的发展历程
2、经典论文
论文:AlexNet (ImageNet Classification with Deep Convolutional Neural Networks)
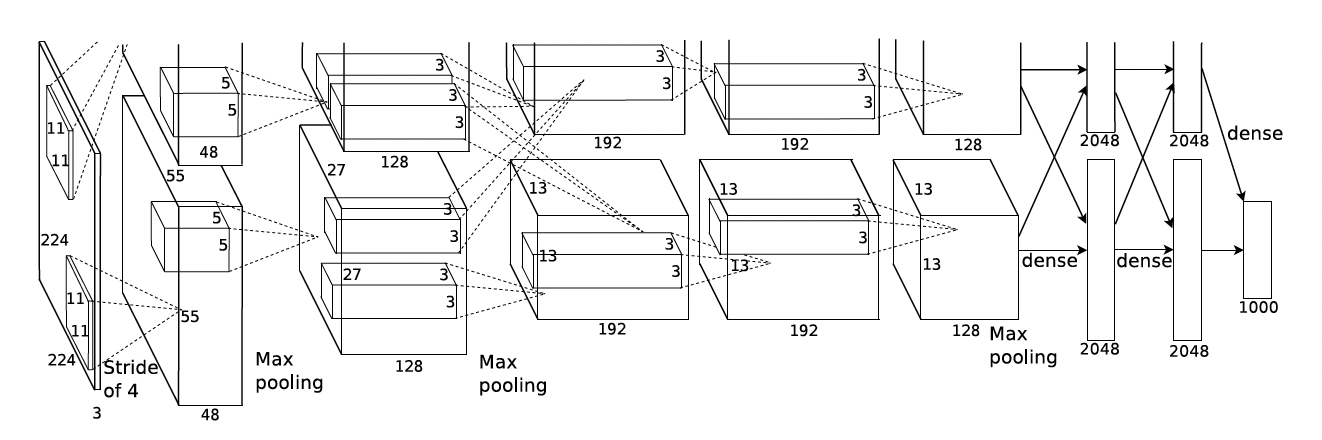
2021年的AlexNet是具有重大意义的,也是从这之后进入了深度神经网络的时代。AlexNet网络使用了5层卷积层和3层FC层,使用的卷积核尺寸有11/5/3,除了推动深度神经网络的发展,也提出了不少后续被广泛使用的技术:
1、使用Relu(非饱和非线性函数)替代tanh,sigmoid(饱和非线性函数),加速迭代,解决sigmoid梯度弥散的问题。
2、使用Dropout正则化,防止模型过拟合。
3、使用LRN归一化,提高模型泛化能力,后被BN取代。
4、使用多GPU训练模型
5、使用重叠的最大池化 (池化框大于池化stride),也是现在常用的池化方式,而此前CNN普遍使用平均池化,最大池化可以避免平均池化的模糊化效果,且重叠操作可以提升特征的丰富性。
6、数据增强,对图像裁剪,翻转等操作增强数据集。
论文:VGGNet(VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION)
VGGNet 的整体结构和AlexNet很相似,也是5层卷积层,3层FC层组成,只不过每层卷积层是由多个3x3或者1x1的卷积子层堆叠而成,整个网络的层数可以达到19层,通过加深网络层数提高准确性。网络参数如下
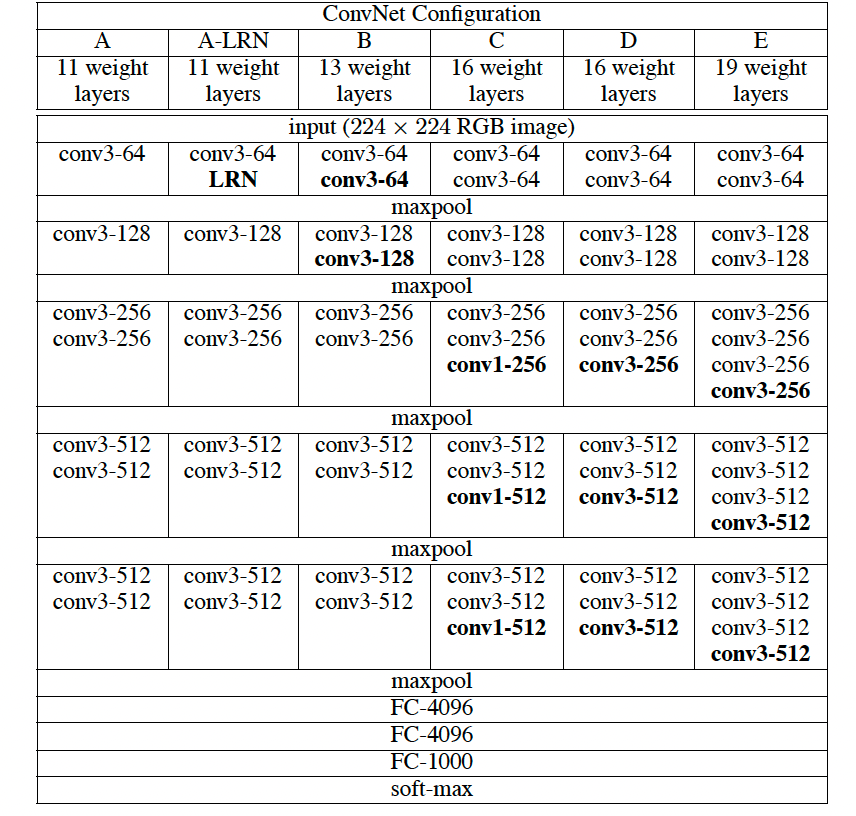
1、VGGNet 中去掉了LRN层,认为没效果,还增加了参数量。
2、使用小卷积核(3x3,1x1),从感受野的角度来看,3个3x3的卷积层等于7x7的卷积层,而参数量小了将近一半,1x1的卷积层在不改变感受野的情况下也可以提升模型的非线性能力。
3、证明了加深网络,可以提高模型的准确性。
4、逐层训练,先训练浅层网络,后用浅层网络的参数初始化深层网络的部分层。
论文:GoogleNet(Going Deeper with Convolutions)
GoogleNet 中将一些子结构模块化,在这里提出了Inception模块,用来融合不同粒度的特征。并且进一步将网络做深到22,而且由于Inception结构,网络的宽度也被进一步加宽。模型网络参数如下:
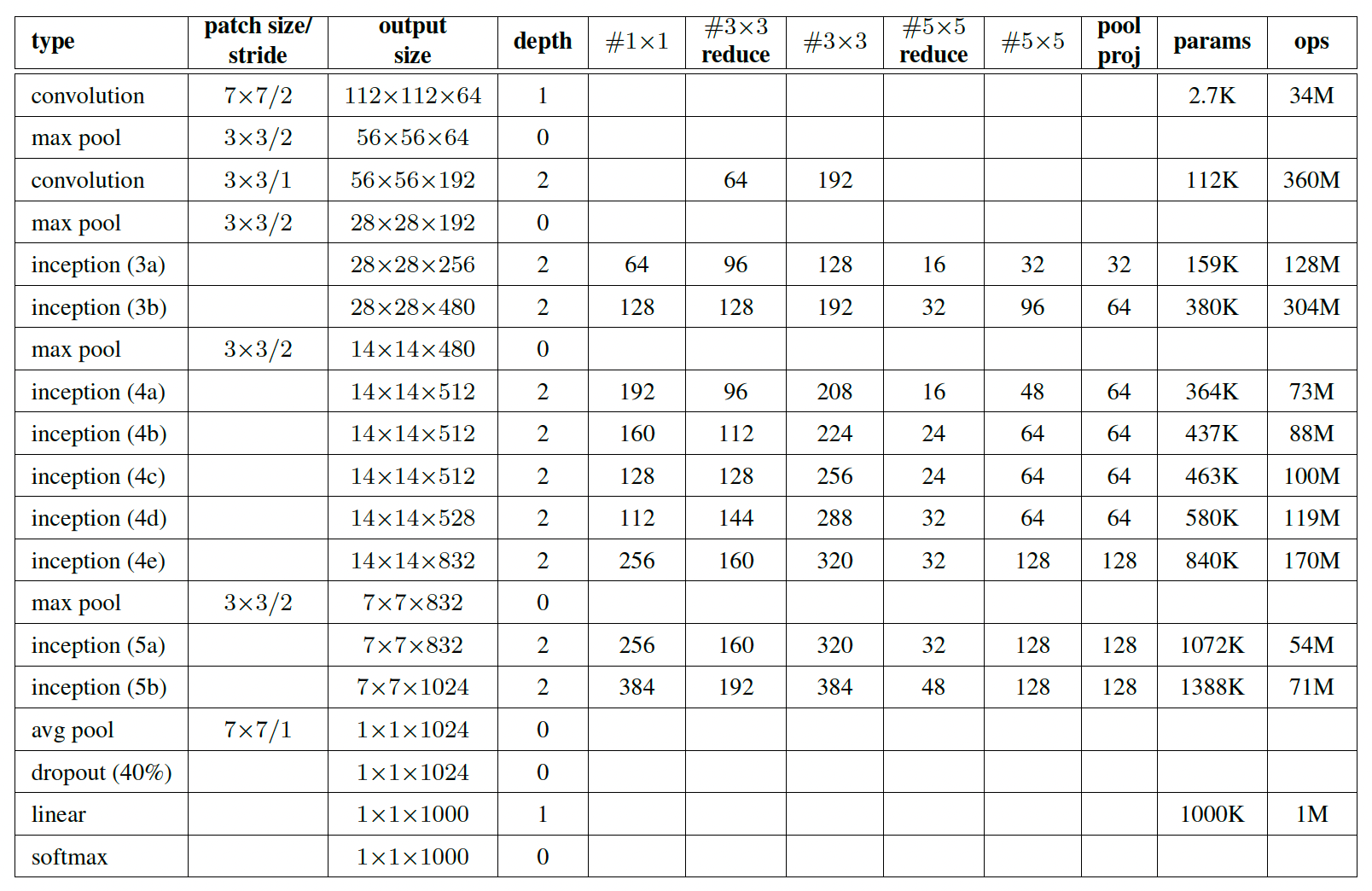
两种Inception结构:
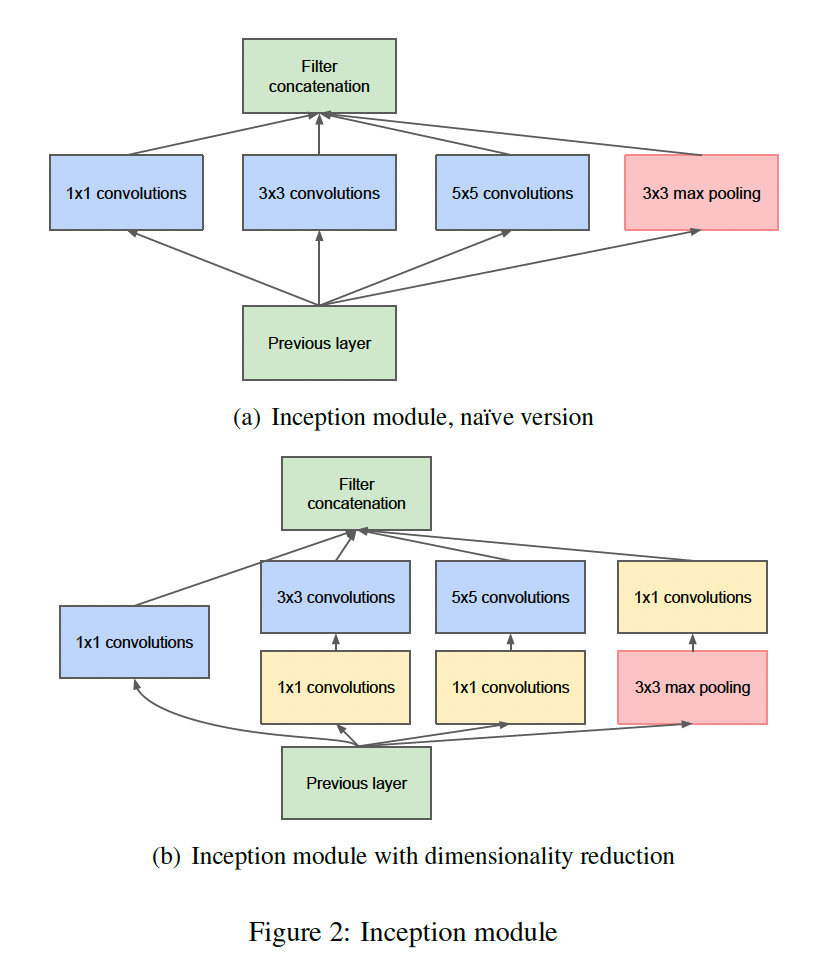
Inception结构是一种并联结构,不同于传统的串联结构提取的特征图尺度单一,Inception使用不同大小的卷积核提取不同粒度的特征后拼接。在上图b中,还使用1x1的卷积核来降维输入通道数,可以达到减小模型参数量,并引入更多非线性的能力。
Inception在后续仍有多个版本迭代,核心目的还是在于如何加深网络,并减少模型参数,增强模型表达能力的同时防止过拟合。
论文:ResNet (Deep Residual Learning for Image Recognition)
ResNet又是一个具有重大意义的工作,引入残差连接极大地提升了网络深度,最深做到了152层。在ResNet 之前,GoogleNet已经做到了22层,但后续随着网络的进一步加深,网络的效果反而变差。假设上,在一个浅层网络上堆叠一些层来增加网络深度,最坏的情况也应该和浅层网络的效果一致,即新增的这些层什么也不学习,仅复制浅层网络的特征,而不是变得更糟糕,那么这些新增的层就实现了恒等映射的功能。基于这个假设,作者提出了残差连接,对于一个堆叠的结构,当输入为$x$时,输出为$H(x)$,现在我们希望网络结构能学习到残差$F(x) = H(x) - x$,此时若要学得$H(x) = x$,只要学习到$F(x) = 0$,而后者明显更容易学习,因为一般每层网络中参数初始化偏向于0,并且Relu能够将负数激活为0。残差结构如下:
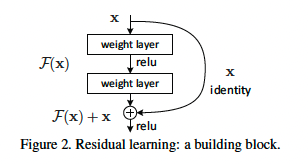
残差网络如下:
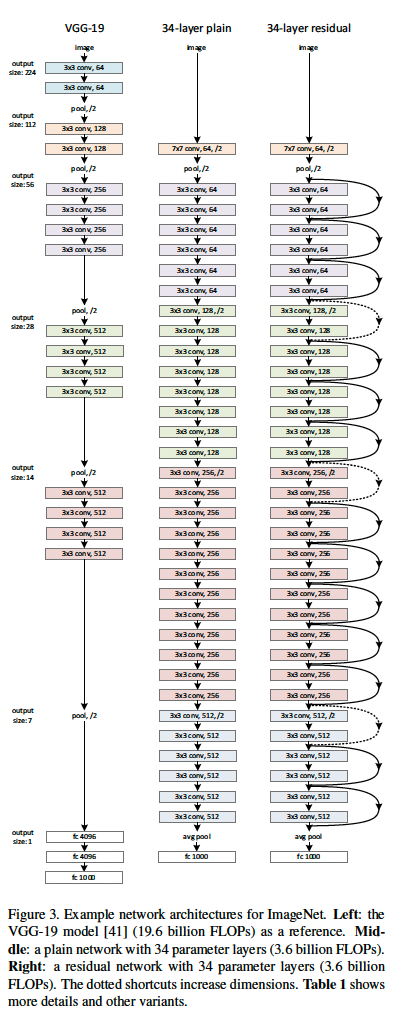
作者提供的网络结构参数如下:
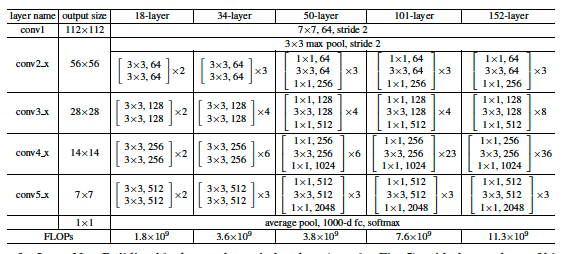
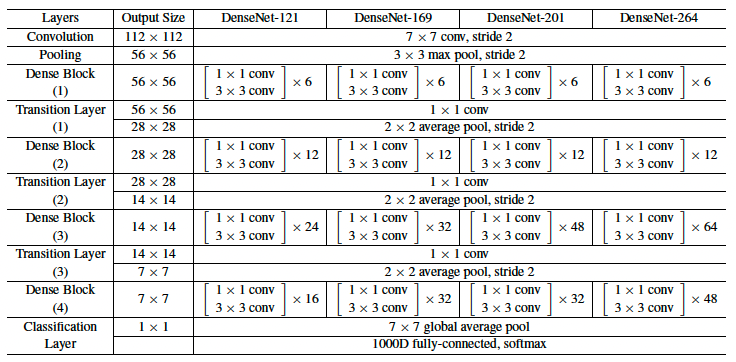
论文:DenseNet (Densely Connected Convolutional Networks)
DenseNet 中认为当网络变深后,输出到输入的路径就会变长,梯度经过这么长的路径反向传播时很可能会消失,所以DenseNet中提出复用之前的特征来解决这个问题。DenseNet中是由多个Dense Block组成的,在Dense Block中,每一层都从前面所有层获得额外的输入,并将自己的特征映射传递到后续的所有层,结构示意图如下:
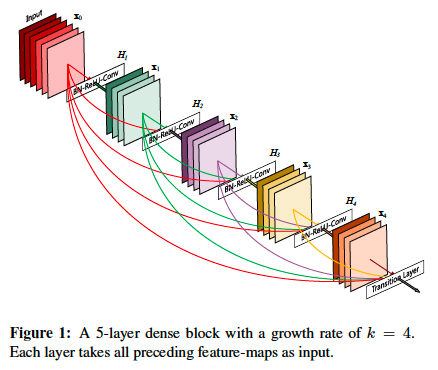
所以对于一个$L$层的网络来说就会有$L(L+1) / 2$个连接,在Dense Block中,对于一个$l$层,如果每层的feature map数为$k$个,那么第$l$层会产生$k_0 + k(l-1)$个feature map,在这里$k$通常取得比较小,如12,因为每一层都与之前所有层相关,所以每一层输出的feature map不需要很大,只需要提供一些新增的特征即可。在Dense Block内的每一层,由于输入是之前所有层的拼接,所以输入的feature map数也不会很少,为了较少计算量和参数,作者使用1x1的卷积降维。
在每个Dense Block之间,作者引入一个Transition layer用于连接所有的Block,由BN + 1x1卷积 + 2x2 avg-pooling组成,1x1卷积可以降维通道数,池化层可以下采样。具体网络结构参数如下:
论文:SENet (Squeeze-and-Excitation Networks)
SENet不同于之前的网络,它更像是BN层一样,是一个适用于所有网络结构的插件,通过Squeeze-Excitation 机制来计算各通道之间的相关性,并通过门机制为各个通道赋予一个权重。其结构如下:
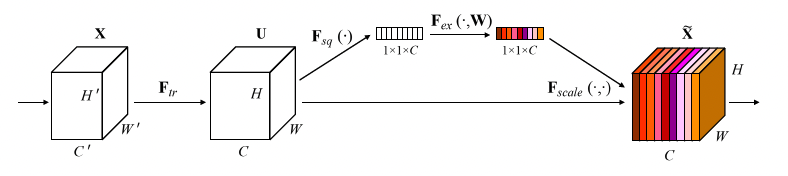
1、对于[H, W, C]的输入,通过global average pooling执行Squeeze得到一个1x1xC的向量。
2、紧接两个FC层组成一个Bottleneck结构建模通道间的相关性,得到维度一致的输出。
3、过一个Sigmoid函数,得到0-1之间的归一化的权重。
4、将上面得到的权重点乘到[H, W, C]的输入上。
下面展示了SE模块在Inception和Resnet中的应用:
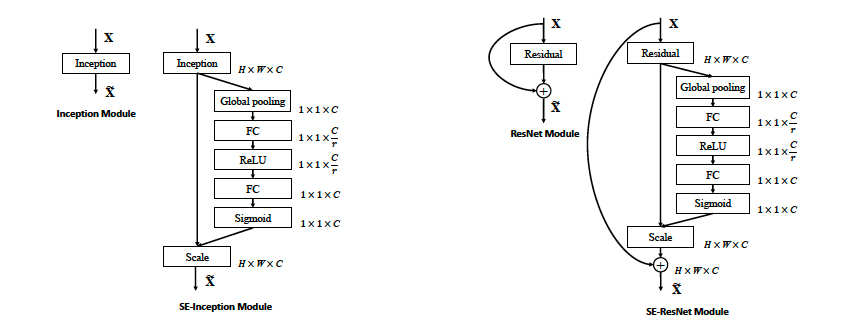
SENet通过建立通道间的相关性,并标定通道的重要性,在不明显提升模型的计算量和参数时,能较大地提升模型的效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号