
NER技术总结
NER技术是工业界落地比较多的NLP技术,文本数据的结构化都依赖NER技术,本文总结下常用的NER技术。
一、词典匹配
词典匹配是工业界最常用的NER技术,尤其是垂直领域的NER任务。词典匹配的优点是速度快,可解释性强,且精度高。但是词典无法解决歧义性问题,为了降低词典匹配的歧义性问题,往往会限制词典的大小而降低召回率。
词典的匹配方法可以直接用字符匹配,也可以使用Trie树匹配,建议使用Trie树。词典歧义性问题还可以通过特征划分来限制,如商品标题的词典匹配,可以通过类目划分来隔离商品和词典,比如“苹果”在“电子产品”下是一个手机的实体词,在“水果”类目下是一个水果的实体词,但是在其他类目下就是一个非实体词。这样能极大地减少歧义性问题。
二、NER模型
2.1 序列标注
序列标注是最经典的NER技术框架,从开始的LSTM-CRF,LSTM-CNN-CRF到后来的BERT-CRF,BERT-BILSTM-CRF。序列标注一直是NER问题中最常用的技术框架,也是最成熟的技术。尤其是后BERT时代,BERT-BILSTM-CRF已经成了最常用的baseline(或者LSTM-CRF)。因为这些模型都耳熟能详,就不做过多的介绍,需要注意的是:一、使用BERT-BILSTM-CRF时,注意BILSTM-CRF权重更新的学习速率要比BERT权重更新的学习速率大一些;二、BILSTM层数不宜过多,一般1-2层就行,核心还是在于特征提取层。
2.2 指针标注
序列标注在处理NER任务时,有它自身的缺点,比如实体过长时,容易出现标注中断;CRF解码速度过慢;解决实体嵌套的问题比较难等等。指针标注能比较好的处理这些问题。指针标注是通过预测实体词的起始位置和终止位置来识别实体的,一个指针网络可以识别一类实体,多类实体时需要使用到多个指针网络。起始位置和终止位置的识别可以看作是N个2分类(N是序列的长度)。指针网络只需要预测起始和终止位置,所以更容易处理较长的实体,也可以解决嵌套问题,多个指针网络之间是独立的,N个2分类也是独立的,因此可以直接解决嵌套问题。
2.3 片段分类
论文:Span-based Joint Entity and Relation Extraction with Transformer Pre-training
实体识别和关系抽取通常是两个任务,但也有不少工作将两个任务合在一起做多任务学习。本文提出Span-based的实体识别的方法,将实体识别和关系抽取一起训练。对于一段长度为$N$的序列,片段数量为$\frac{n(n+1)}{2}$,在训练的过程中,真实的实体或关系对为正样本,而负样本通过采样的方式生成。具体的网络结构如下:
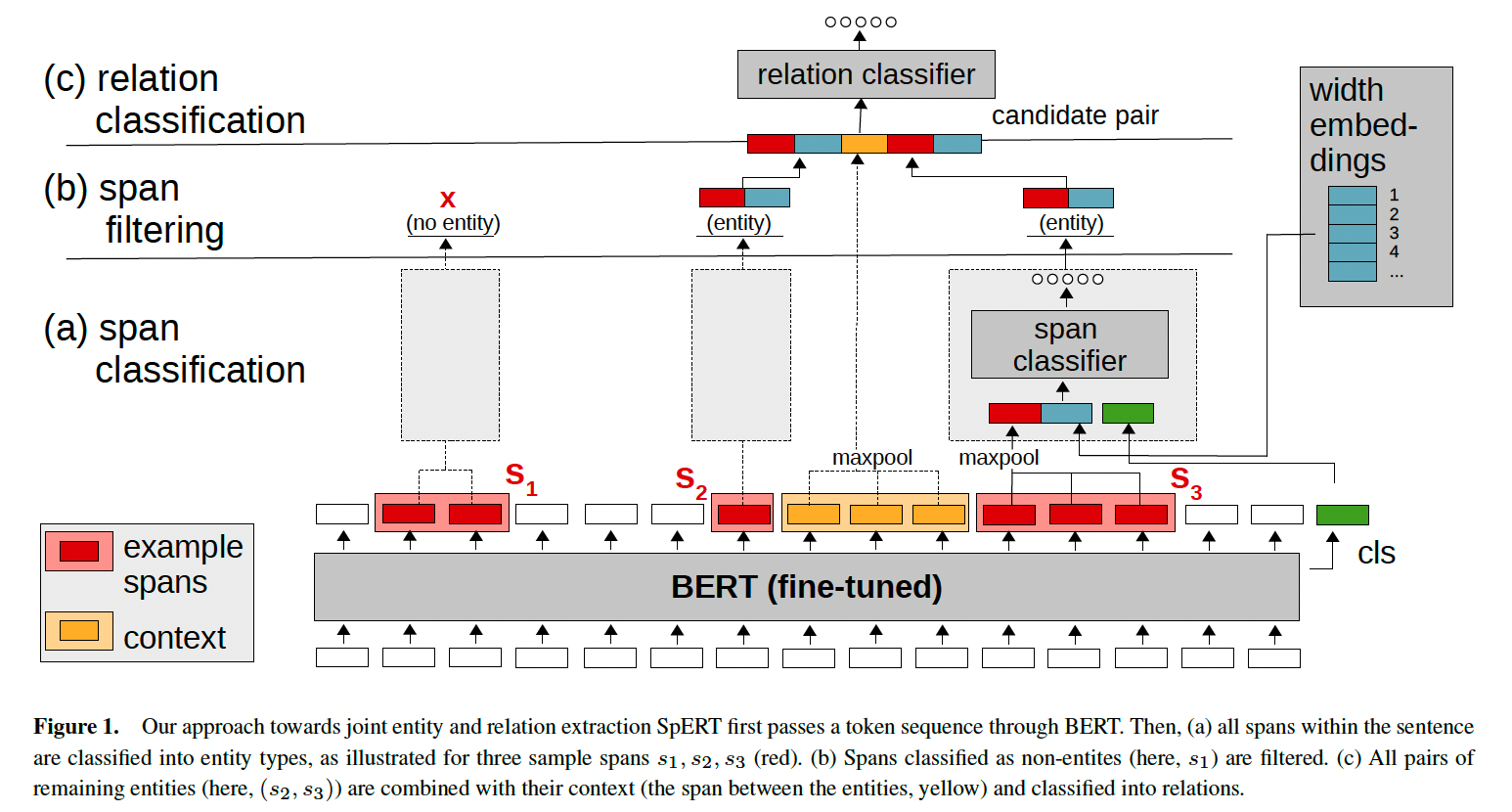
整个网络结构分为三层,模型的底层特征表示使用bert模型。
a) 片段分类
每个片段的表征由三部分向量拼接而成,一是片段中token embedding取max pooling,二是片段长度的embedding,由一个可以学习的embedding矩阵输出,三是全局的序列embedding,即尾部特殊token “cls”的embedding。拼接后的向量经softmax分类即可以得到片段的实体类型。分类的类别数由所有的实体类型和None(表示非实体)组成。具体的公式如下:
![]()
![]()
![]()
上面式子中$f(e_i, e_{i+1}, ...)$表示片段中token embedding取max pooling,$w_{k + 1}$表示片段长度的embedding,$c$表示 cls 的embedding,o 表示向量拼接的操作。
b) 片段过滤
将一些长度过长的片段直接默认为非实体,可以减少片段分类的计算消耗,作者在这里将长度超过10的片段过滤掉,这个值可以视自己的任务来定。
c) 关系分类
在片段分类中得到$S$个实体集合,在关系分类中就有$S \times S$个关系对,注意$(s_i, s_j)$和$(s_j, s_I)$是不同的关系对,因为关系对中有头实体和尾实体的概念。在构建关系对的表征时也是通过拼接的方式。值得注意的是在这里去除了片段分类中使用的cls embedding,转而采用了两个实体间的片段的embedding,命名为$c(s_1, s_2)$,则片段的表征可以表示为

![]()
上式中$x_1^r$和$x_2^r$分别表示片段$(s_1, s_2)$和$(s_2, s_1)$的向量表征。在这里最后的分类层没有使用softmax,而是使用了sigmoid,且sigmoid输出的维度为$R$,即关系的类别数。所以这里是当一个多标签分类的任务来做的,通过卡一个阈值$\alpha$,将分数大于阈值的关系作为实体间的关系。
作者还通过实验提出两个关键问题,一是负采样的数据及方式都会影响到最终的结果,二是max pooling提取片段表征的方式要优于其他的pooling。首先负样本随着数量的增加,F1值会上升后平衡。如下图:

另外负样本采样的方式也不是完全随机,关系分类中的负样本是从实体对中采样的,即是从$S \times S$中采样的,而不是任意片段的组合。其实负样本采样的核心问题还是如何采样出更多的困难负样本。
最后就是max pooling的问题,在作者的实验中max pooling要明显优于其他的pooling方式,这是我没有想到的,尤其是相对于average pooling,理论上对于一个片段,如果这个片段是一个实体,信息量已经是比较集中了,为什么average pooling还这么查,也许这就是neural network。
论文:EMPIRICAL ANALYSIS OF UNLABELED ENTITY PROBLEM IN NAMED ENTITY RECOGNITION
工业界中的实体识别任务通过缺乏干净的训练数据,往往是通过一个领域词典自动标注训练样本,通过这种方式标注会带来两个问题,一是正样本标注错误,但只要严格卡住词典,可以减少正样本标注错误,二是正样本被漏标,这种情况会出现的比较多一点。在使用这样一份数据训练模型时,就会存在大量的正样本被视为“负样本”,从而严重影响模型的性能。作者在这里通过将开源数据中的正样本mask掉转换成“负样本”来模拟这种场景,并且提出通过span classifier来减少这类被误标成“负样本”的数据的影响,作者认为如果使用传统的BIO标注的话,那么所有的错误“负样本”都会被带入从而严重影响模型的性能,在span classifier中负样本是通过采样生成的,采样时就会将部分错误标注为“负样本”的片段给遗漏掉而降低负样本的错误率。这个也很好理解,原来一个长度为N的序列有一个实体词被漏标了,使用BIO标注时会被当成一个负样本,从而贡献了一个错误的负样本,而在使用span classifier时,这个序列有$\frac{n(n+1)}{2}$个片段,按一定的比例$\lambda$采样负样本的话,则会有$\frac{n(n+1)}{2\lambda}$的概率贡献一个错误的负样本。
本质上和上面的论文差不多,不同点在于只有实体识别单个任务,二是片段的表征方式不一样。其模型结构图如下:
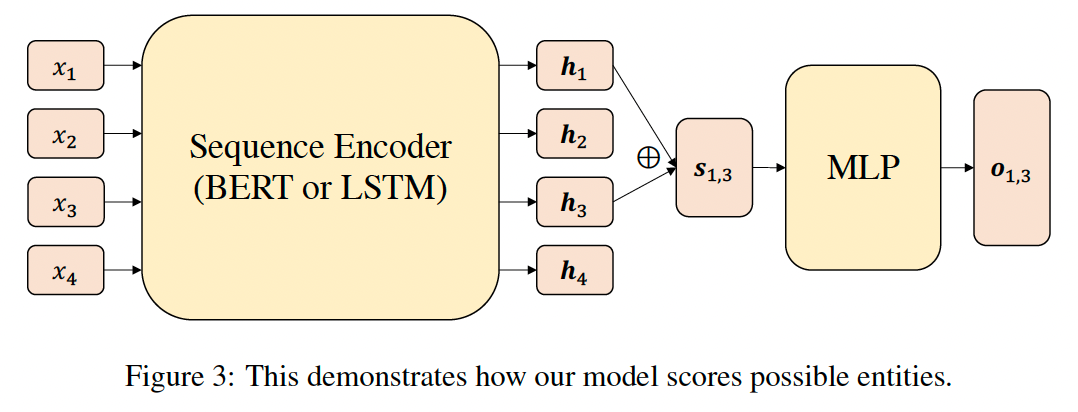
片段的表征在这里只使用的片段的头尾token的embedding。具体表达式如下:
![]()
$\oplus$和$\odot$分别表示拼接和element-wise的乘积。
最后来看一组实验数据,作者通过不同的mask比例来构造错误的负样本,对比BIO和span classifier标注的准确率。
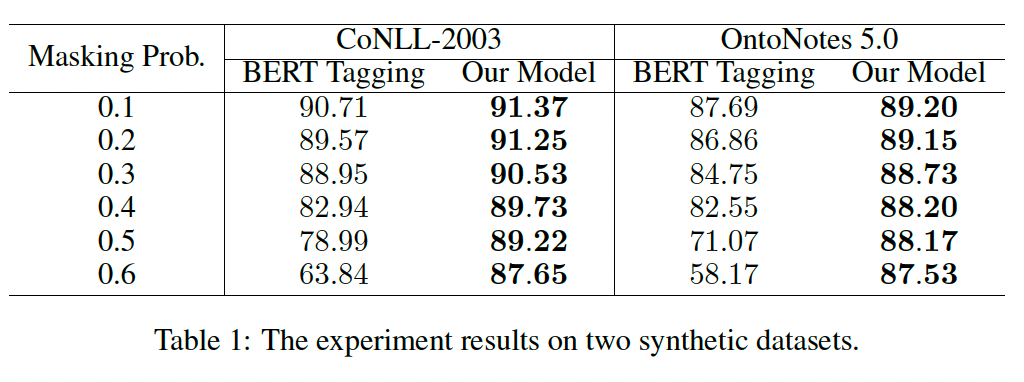
span classifier除了在上述两个场景下使用外,也和双指针一样,可以很容易解决实体过长,或者嵌套实体等问题。
2.4 MRC-NER
论文:A Unified MRC Framework for Named Entity Recognition
阅读理解是一类QA型的问题,给定query后,从一段内容中抽取对应的answer,很多时候answer就是一个实体词,或者一个短语。所以将实体识别任务转换成阅读理解任务也是比较切合的,阅读理解任务在抽取answer时通常用的就是双指针的方法,通过预测answer的起始和终止位置,和双指针的实体识别不同的地方是需要提供query。因此基于阅读理解的实体识别可以分成两部分:一是构造和实体类型相关的query,比如“find an organization such as company, agency and institution in the context”可以作为实体“organization”的相关query;二是使用双指针的方法抽取实体。从这个模式上看和NLP中的Prompt方法很相似,所以构造什么样的 query 其实是会影响到模型的准确性的。为什么要将一个NER任务搞得这么复杂?主要是MRC-NER有两个主要的优点:一是可以很容易地处理嵌套实体的问题,二是引入的query能提供更多和实体相关的信息。
在query的选择中,作者测试了不同的query对结果的影响:
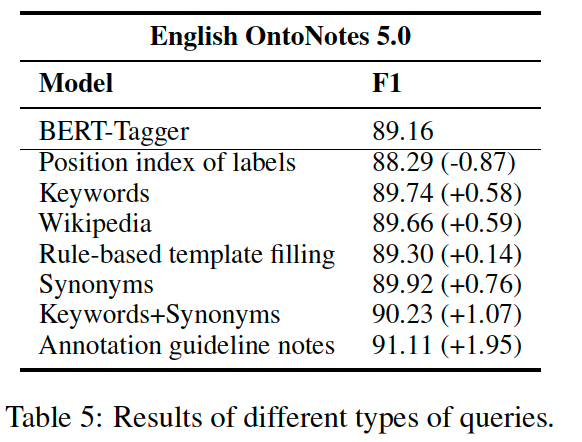
Position index of labels:用数字作为query,例如1、2、3。
Keywords:表示实体类型的关键词。如“organization” 用于实体类型ORG
rule-based template filling: 生成query的模型,如“which organization is mentioned in the text”用于实体类型ORG
Wikipedia: 使用维基百科的定义。
Synonyms: 表示实体类型的同义词。
Keywords + Synonyms:关键词+同义词的拼接。
Annotation guideline notes:注释指南。如”find organizations including companies, agencies and institutions”用于实体类型ORG。
在模型的构建中和双指针差不多,在起始和终止位置有多个预测结果时,也就是实体会有多个组合时,作者提供了一种选择实体的方法。对于多个起始和终止位置集合

将$\hat{I}_{start}$和$\hat{I}_{end}$中任意合法的起始和终止位置组合进入到一个二分类的任务重判断该组合是否是合法的实体。
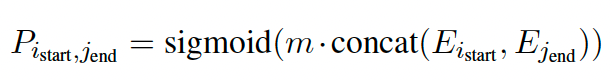
其中 $m$ 是一个可以学习的权重。
三、NER问题扩展
3.1 训练集存在标注错误的情况
论文:CrossWeigh: Training Named Entity Tagger from Imperfect Annotations
在人工标注的数据中,往往存在不少的误标数据,尤其是NER这种标注难度较高的任务。针对这类问题,本文提出了一种训练NER任务的框架——CrossWeigh,该框架适用于大部分NER模型。
CrossWeigh的核心思想是利用K-Fold的思想,先将所有的训练集划分成K份数据集$\{D_1, D_2, ......, D_K\}$,将$D_i$作为测试集,其余的K-1份作为训练集。经过K次训练后可以得到K个模型,并分别预测K份数据集,这样就可以得到所有训练集的预测结果。值得注意的是,训练集划分时,需要确保$D_i$所包含的实体词不应该出现在剩余的K-1份数据集中,这也是我们常用的划分实体识别数据集的方法,避免模型通过记住实体词去识别,而不是通过理解整个句子的上下文去识别。
在CrossWeigh中上述K-Fold过程会被执行t次,每一次划分数据集时都是随机的,确保每一次都不一致。粗略地可以认为模型预测的标签$\hat{y_j}$和真实标签$y_j$一致的话,那真实标签大概率是正确的,模型预测的标签$\hat{y_j}$和真实标签$y_j$不一致的话,那真是标签有可能就是错误的。t次迭代后,每个样本$S_i$都可以得到t次预测结果,通过这t次预测的结果去计算样本$S_i$的训练权重(可以认为$\hat{y_j} = y_j$时样本标注的正确概率高,权重应该大;反之权重应该小),作者基于此给出了一个计算样本权重的公式:
$w_i = \epsilon^{c_i}$
在上面的式子中$\epsilon$是基于统计得到的,表示数据集标注的正确率。$c_i$作者给出了多种计算的方法,最直接的可以使用$\hat{y_j} \neq y_j$的次数。得到$w_i$后,使用训练集训练模型,在计算loss时,就可以将$w_i$带上。
对标注数据存在错误的情况下,使用CrossWeigh框架时对结果是有些提升的。

CrossWeigh的思想还是比较好理解的,我们实际工作中也会通过K-Fold的做法去找出潜在的标注错误的样本,然后人工校验,只不过这里作者引入样本权重对潜在错误的样本降权,但这种做法也可能会把正确的困难样本给降权,所以有人工资源,还是人工校验最好。
3.2 词汇增强
中文NER任务中,通常是直接在字符上标注(中文分词会引入错误,基于词的实体识别会把分词的错误带入,从而导致效果不佳),但只使用字符又会丢失掉词的信息,因此有大量的工作在研究如何通过引入词汇信息来提升NER任务。
论文:Chinese NER Using Lattice LSTM
Lattice-LSTM通过修改LSTM的结构引入词汇信息,可以看作是专门为实体识别定制的LSTM结构。通过对输入的序列分词,将词汇信息在计算字符的记忆状态时引入。Lattice-LSTM的模型结构比较复杂,在推断时延时性较高,且LSTM无法并行。因此不做过多的介绍,感兴趣的可以看原论文。
论文:Simplify the Usage of Lexicon in Chinese NER
本篇论文提出了一种简单的融入词汇信息的方法,且是在embedding层融入的,所以也适应于各种网络结构,且不明显增加模型的复杂度。通过对输入的序列分词,分词可以采用jieba中的全模式分词,将序列中所有可以成词的词语都切出来,这样就会存在一个字符出现在多个词语中,这种将可能包含字符的所有词汇都列出来,一定程度上能消除分词错误带来的负面影响。
以一个例子来看,如何引入词汇信息:

首先引入{B、M、E、S}来表示字符处于词汇的哪个位置,B表示词汇首个字符,M表示词汇中间,E表示词汇最后一个字符,S表示词汇是单个字符。以上面的图中为例,对于“山”这个字符,会出现在“山西”、“中山西路”、“中山”、“山”这四个字符中,所以可能得到四个集合$S_B$,$S_M$,$S_E$,$S_S$,每个集合中会有 0 个或者多个词汇,如果为空,则添加一个特殊词汇“NONE”到集合中。得到 4 个集合后,分别对 4 个集合embedding,得到表征集合的向量:

上式中$z(w)$是离线计算好的,统计得到的词汇的词频。最后将这 4 个集合的向量拼接到字符向量上作为最终的字符的embedding输入到下游模型中。
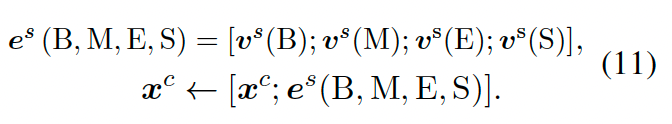
这篇论文提出的方法无论是在推断速度还是精度上都取得了更好的效果。在引入词汇信息增强时值得尝试。具体的性能指标见原论文。
论文:FLAT: Chinese NER Using Flat-Lattice Transformer
FLAT利用attention和位置向量的特性,将词汇信息引入到字符中,不需要像Lattice-LSTM中那样构造Lattice结构。基于FLAT的特性,所以很适合transformer结构,或者说是在transformer结构上提出的一种融合词汇信息的方法。
一张图可以概括FLAT的方法:

1)分词仍然采用全模式切词的方式切词,得到的词汇直接拼接在序列后面,在这里字符和词汇都是一个单独的token,引入两个位置信息 Head 和 Tail 来表示token的头尾位置。
2)因为要考虑字符和词汇之间的关系,所以要引入相对位置来表示它们之间的关系,因为每个token都有头尾两个位置信息,所以提出了 4 种相对位置距离:
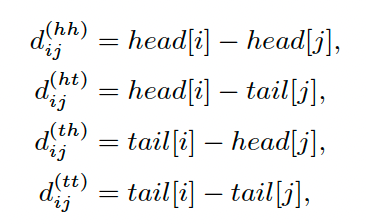
结合这 4 种距离,可以得到每个token之间的相对位置关系:
![]()
其中$P_d$的计算公式如下:
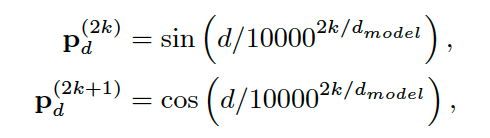
3)引入相对位置信息,计算 token 之间 attention 信息,最后只针对字符token标注,词汇token会被mask掉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号