

语言模型系列(一)——AWD-LSTM
1,概述
语言模型可以说是NLP中最基本的任务,无论是词向量,预训练模型,文本生成等任务中都带有语言模型的影子。语言模型本质上是对一个自然世界中存在的句子建模,描述一个句子发生的概率,因此语言模型也是一个自回归的任务。语言模型是一个上下文强依赖的任务,不仅需要捕获长距离的信息,还需要学到词之间的位置关系,从目前的技术来看,RNN系的模型在语言模型任务上的表现要优于transformer,主要原因还是因为Transformer在学习词位置关系时的能力弱于RNN,毕竟RNN是严格的从前到后循环依赖的。本系列将从AWD-LSTM开始,看看这之后的比较优质的语言模型的论文,以及transformer在语言模型中的表现。
2,论文解读
作为系列的第一篇,先从最经典的AWD-LSTM开始,因为AWD-LSTM内容较多,且之后的很多论文都是在其基础上改进的,所以详细介绍它。
论文:Regularizing and Optimizing LSTM Language Models
RNN在语言模型任务中的表现是非常优秀的,而且RNN的结构和语言模型的任务特性也很好的切合。但RNN的循环连接容易过拟合。本片论文就是围绕这一点展开的研究,提出了很多中解决RNN过拟合的技术,这一类技术不仅可以用在语言模型中,也可以用在其他RNN建模的任务中,LSTM作为RNN系列中最优秀的代表变体,论文就是在不改变LSTM的原有结构上,引入各种正则化技术,提升模型的泛化能力,改善语言模型的性能。接下来将详细介绍论文中的正则化技术。
1)weighte-dropped LSTM
首先来看下LSTM的公式:
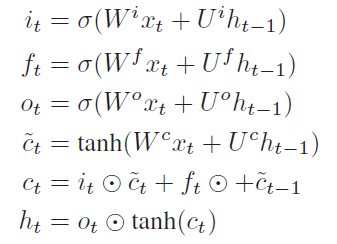
Dropout是神经网络中常用的正则化技术,也可以使用在LSTM的隐层连接中,但通常效果不佳,因为Dropout会破坏LSTM的长距离能力,因为Dropout会随机丢掉一些神经元,即把一些神经元的节点值设置为0。直觉上来看在计算$h_t$的时候,因为$h_{t - 1}$中被drop掉一些神经元,在计算$h_t$的时候就丢掉了一些之前的信息。作者在这里使用DropConnect替换Dropout来对隐层(即$U^i, U^f, U^o, U^c$)权重正则化,那DropConnect为什么又会比Dropout要好,DropConnect是在计算$h_t$时刻的某个神经元的值时只使用$h_{t-1}$中部分的神经元,那么在$h_t$时刻的所有神经元的计算中基本上会 用到$h_{t-1}$的所有神经元的值。一般来说Dropout和DropConnect并没有说哪个正则化技术更好,只看适用的场景,在DNN中来说,使用Dropout正则类似于badding的思想,但是在LSTM中每一次迭代,$h_t$时刻是强依赖$h_{t-1}$,使用Dropout就破坏了时间序列上的信息流动,Dropout和DropConnect正则化的粒度不一样,Dropout是对整个网络正则,而DropConnect是对每次连接正则,所以在LSTM中使用DropConnect更适合。
因为LSTM中的权重在时间步上是共享的,所以每个时间步上可以使用相同的DropConnect mask。类似于variational dropout。
2)Variable length backpropagation sequences
一般在训练语言模型时是将整个语料看作一个连续的很长很长的句子,然后将句子截断成batch size个,然后又按照固定长度对这batch size个序列截断,作者认为固定长度的阶段影响了模型的性能,假设一个长度为100的序列,分成10个固定长度为10的序列,则这里面又1/10的词在反向传播中没有任何信息输入,其实也就是截断后的序列的最后一个词,有8/10的词只能使用部分输入。我感觉这个策略用处不会特别大,你可以把序列长度设长一点,这样序列的依赖就变长了,但也不用太长,因为太长了Lstm也cover不住,句首的信息会因为梯度消失而丢失。
3)Variational dropout
一般的Dropout是每一次连接时都会通过dropout 函数(伯努利分布采样)得到一个dropout mask,但是在LSTM中参数是共享的,作者希望在不同的时刻共享的参数也共享同一套dropout mask,这就是variational dropout,在隐层作者使用了共享mask的dropConnect,而在输入和输出中,作者使用共享mask的variational dropout。但是请注意在不同的mini-batch中,mask是不共享的,所以mask的共享和参数共享还是有区别的,dropout mask的共享是在每一个迭代中发生的,不同的迭代输入的数据不同,为了体现数据的差异性,要保证dropout mask不一致。
4)Embedding dropout
对嵌入层引入dropout,实际上是在词级上操作的,即随机将一些词给去掉,这些被去掉的词的向量值就全为0,并且在前向和反向传播中都保持这样的操作。对其余没有丢掉的词,用$\frac{1}{1 - p_e}$缩放其向量值,$p_e$为dropout 的比例。
5)Weight tying
共享embedding层和output层,因为语言模型的最后输出也是vocab size维,是预测vocab中每个词的概率,从模型设计上来看嵌入层和最后输出层的参数矩阵的维度是很容易保证一致的,而从语言模型的特性上来看两个矩阵之间也是有一定的联系,所以作者选择共享嵌入层和输出层的权重矩阵,这种方法在seq2seq中也经常用到。
6)Independent embedding size and hidden size
在RNN系列的模型中,参数量通常集中在embedding层,作者选择减小embedding size,并且让第一层LSTM的输入和最后一层LSTM的输出的维度等于embedding size。
7)Activation Regularization (AR) and Temporal Activation Regularization (TAR)
除了Dropout正则化技术,作者还引入了L2正则化,在这里主要是对两部分,一是对输出层$h_t$(这个是我没想到的,一般L2都是对权重),称为AR。另一个是对$h_{t + 1}$ 和$h_t$之间的差值,称为TAR,这个其实还是比较好理解的,$h_{t + 1}$是即包含了当前的信息,也包含了之前的信息,所以较$h_t$不应该有较大的差异,这种就类似于滑动平均一样,因为涵盖了大量之前的信息,所以当前的输入值也不应该对结果有太大的改变。两者的公式分别如下:
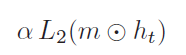

上述都是从正则化,或者去其他提升模型泛化的技术上去改善模型的性能,下面将介绍作者提出的一种新的优化方法,专门为语言模型准备的。
NT-ASGD
研究发现,对于特定的语言建模任务,SGD的效果要优于带动量的,或者自适应学习速率的优化算法,如动量法,Adagrad,RMSProp,Adam等优化算法。作者在这里没有直接使用SGD,而是调研了ASGD(averaged SGD),发现ASGD的有着更好的效果。ASGD中有这么一项,即对过去的权重求均值,ASGD中用过去的参数的均值替换上一步的参数:
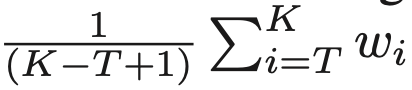
代码中参数$K$是当前迭代次数,$T$是一个阈值,在这里$T$是要预先设置的值,$lr_t$是有学习调配器决定的,然而$T$值,以及学习调配器并不好设定,所以作者提出了NT-ASGD,首先使用恒定的学习速率。具体算法如下:

作者用非单调条件来触发ASGD,即用语言模型中的度量值perplexity来判断在一个非单调区间内,perplexity没有得到改善,就触发ASGD,而这个单调区间的大小设置为n=5效果最佳。
实验设置
实验使用的数据集是PTB和WT2,WT2数据集大约是PTB数据集的两倍,WT2的vocab size是30000,包含了大小写,标点符号,数字等字符,PTB的vocab size是10000,去除了标点符号,数字等字符,所以在测试机存在大量的OOV问题。
网络结构是3层lstm,隐层大小1150,embedding size是400。NT-ASGD中T=750,n=5。batch size设置为WT2=80,PTB=40,大的batch size比使用10-20的batch size效果要好,其实这是显而易见的,太小的batch size,每个batch的特异性太大,不利于网络收敛。并且在完成上述训练后,作者还用ASGD进一步fine-tuning网络。其余如梯度截断,学习速率,动态BPTT的序列长度,dropout的比例见论文。
实验结果
表一是作者在PTB上的测试结果
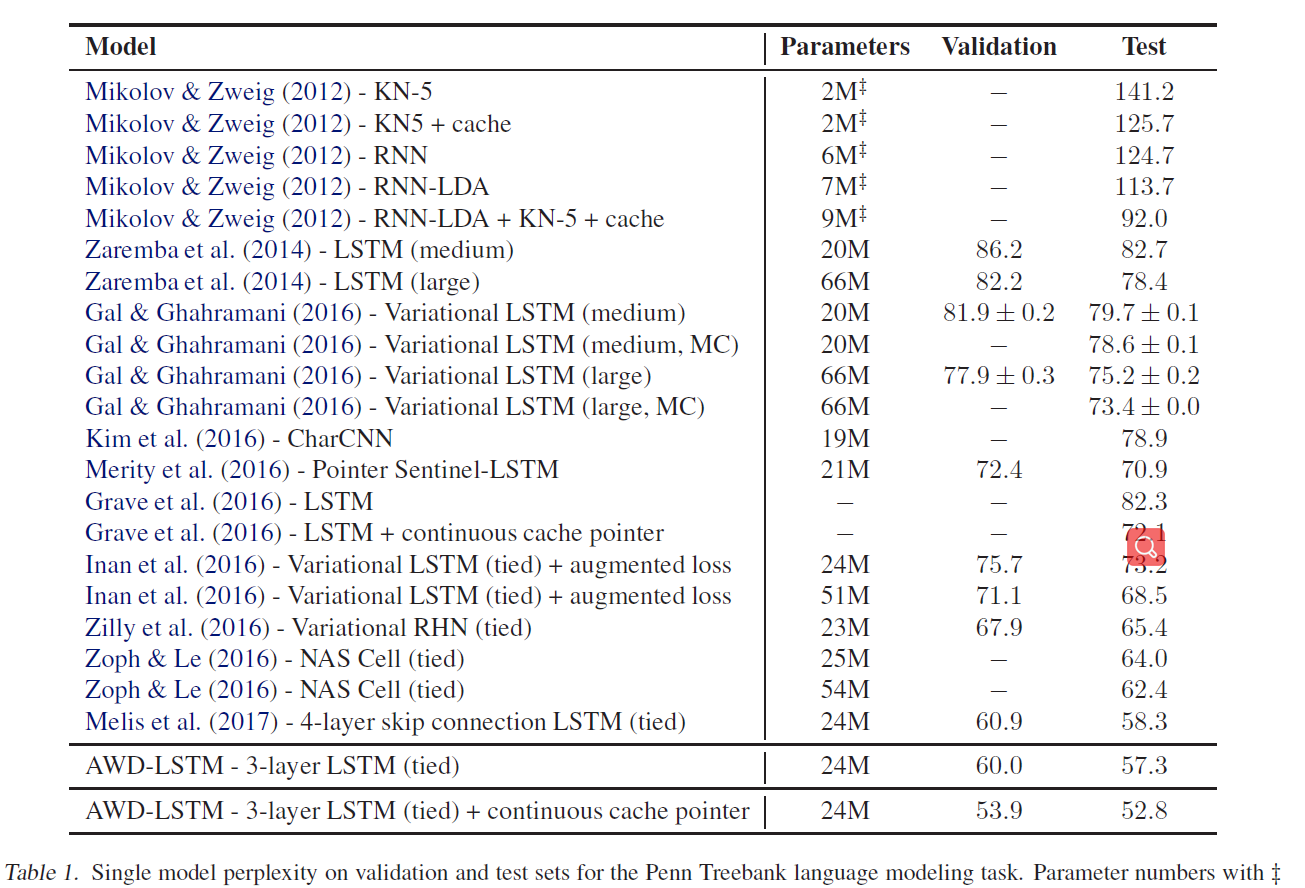
这里有个很有意思的地方,就是上面的Melis的结果,Melis使用自动超参搜索在较小的网络中也能取得很好的表现,而且也证明了语言模型对超参数是非常敏感的(深有感触,目前遇到的最难炼的丹,小数据集上极容易过拟合)。
表2展示了在WT2上的表现
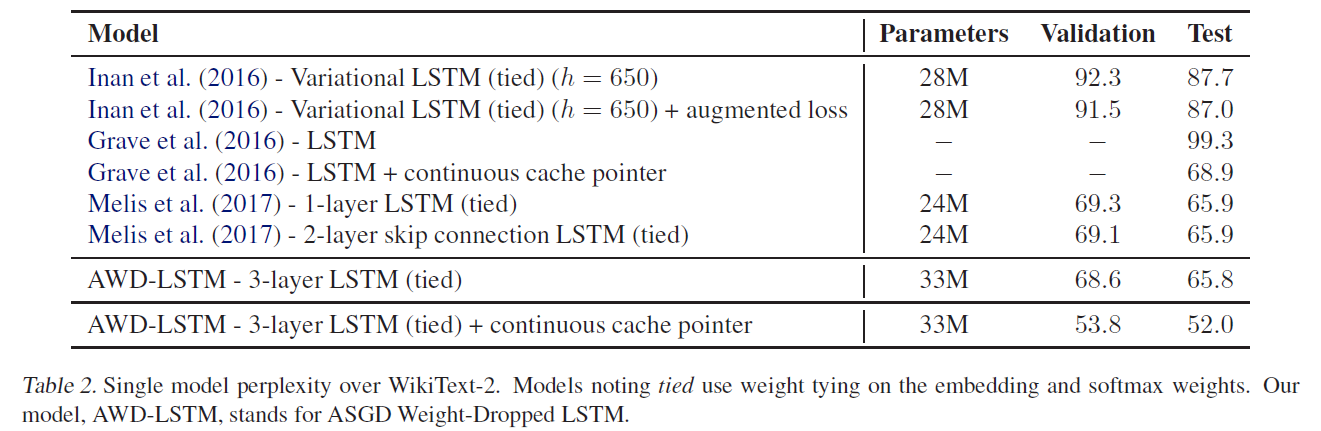
上面这两张表都没什么好看的,就是AWD-LSTM取得了当前最佳的效果,来看看下面这张表:
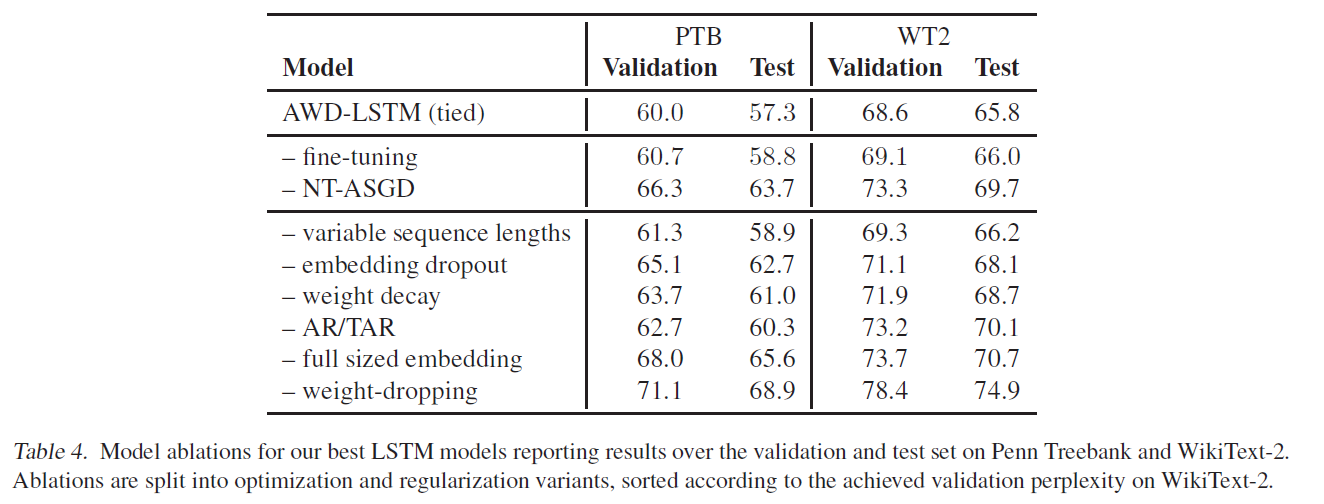
上面表格展示的是当去掉某个策略后的性能,variable sequence lengths是最不重要的,其实这个也正常,一是有隐层状态在传递信息,二是即使增大长度,长度也是有限的,并不会有明显提升,三是语料本身也不一定具备很强的连续性,像从Wiki中抽取出来的数据,不同的文章之间并不会有什么联系。fine-tuning只有微量提升,WT2的验证集上反而有副作用,最重要的当属weight-dropping,这也是自然,毕竟隐层的循环是LSTM的核心,也是语言模型任务的核心。另外值得注意的是NT-ASGD也是有很明显的提升,大多数任务用Adam就能取得很好的效果,但语言模型就是不一样,只能说语言模型是很难炼的丹。
参考文献:
Regularizing and Optimizing LSTM Language Models

 浙公网安备 33010602011771号
浙公网安备 33010602011771号