模型层以及orm查询
模型层以及orm查询
一.单表查询
1)前期准备工作
新建一个数据库(用navicate就行)

-
添加代码

-
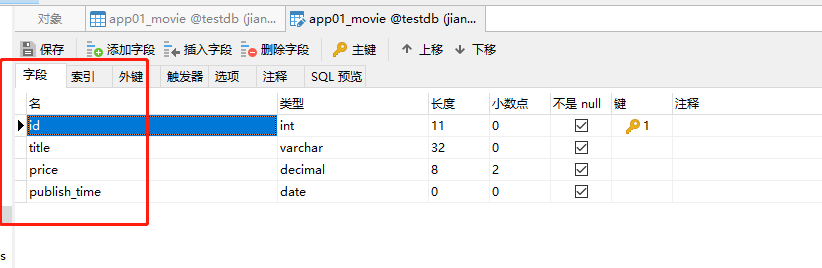
开始在models.py文件中创建表类
1 class Movie(models.Model): 2 title = models.CharField(max_length=32) 3 price = models.DecimalField(max_digits=8, decimal_places=2) 4 publish_time = models.DateField() # 表示添加的时间是年月日 5 ''' 6 补充:DateField中有两个参数,一个是auto_now:表示每一次修改数据都会将时间保存跟新, 7 另一个是auto_now_add,表示只添加开始创建的时间,后面不会改变 8 ''' 9 # publish_time = models.DateTimeField() 表示添加的时间是年月日时分秒(带有time)
-
通过python mange.py makemigrations和python mange.py migration执行数据库迁移命令
-
设置如何在Django中单独测试某一个py文件
1 # 将manage.py文件中的前四行代码(添加环境变量用的)拷贝到test.py(任意一个test.py文件都可以),然后再在test.py文件中写上下面两句代码即可 2 import django、 3 django.setup() 4 5 from app01 import models 6 models.Movie.objects.all 7 8 # 这样在test文件中直接运行py文件就可以执行并看到效果 9 10 11 # 整体设置代码如下 12 import os 13 if __name__ == "__main__": os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day53.settings") 14 import django 15 django.setup() 16 17 from app01 import models 18 models.Movie.objects.all()
2)单表查询必知必会16条
1.create() 2.all() 3.filter() 4.update() 5.delete() 6.first() 7.last() 8.get() 9.values() 10.values_list() 11.order_by() 12.count() 13.exclude() 14.exists() 15.reverse() 16.distinct()
补充:
1 # 只要是queryset对象就可以无限制的调用queryset对象的方法 2 res = models.User.objects.filter(**kwargs).filter().filter().update()/delete()/values() 3 #只要是queryset对象就可以直接点query查看当前queryset对象内部的sql语句 4 queryset_obj.query 5 #公告的方法 查看所有orm语句内部的sql语句 6 #有一段固定的日志文件配置 拷贝到配置文件中即可 7 LOGGING = { 8 'version': 1, 9 'disable_existing_loggers': False, 10 'handlers': { 11 'console': { 12 'level': 'DEBUG', 13 'class': 'logging.StreamHandler', 14 }, 15 }, 16 'loggers': { 17 'django.db.backends': { 18 'handlers': ['console'], 19 'propagate': True, 20 'level': 'DEBUG', 21 }, 22 } 23 }
1.create()


1 # 1. create() :给数据库表添加内容,注意使用create是有返回值的,返回值就是当前被创建的数据的对象本身 2 # 由于之前设置的时候没有给默认时间,这里可以手动填写时间 3 models.Movie.objects.create(title='西游记', price=666.66, publish_time='2018-1-1') 4 res = models.Movie.objects.create(title='红楼梦', price=555.55, publish_time='2018-1-1') 5 print(res) 6 # 也可以进行修改让其自动添加时间(现在是为了方便) 7 from datetime import date 8 ctime = date.today() 9 models.Movie.objects.create(title='水浒传', price=888.88, publish_time=ctime) 10 models.Movie.objects.create(title='三国演义', price=999.99, publish_time=ctime) 11
2.all()
1 # 2.all()查询数据库所有内容对象返回的是一个queryset 2 # res = models.Movie.objects.all() 3 # print(res)
3.filter()
1 # 3.filter() 指定条件筛选,返回的是queryset对象 <QuerySet [<Movie: Movie object>]>,若不指定条件则查询所有 2 res = models.Movie.objects.filter(id=1) 3 print(res) 4 # pk表示主键 5 res = models.Movie.objects.filter(pk=1) 6 print(res) 7 # 括号内可以传多个条件,条件之间是and关系 8 res = models.Movie.objects.filter(pk=1, title='水浒传') 9 print(res) 10 # 只要是queryset对象 就可以通过 点query 的方式查看到获取到当前对象内部sql语句 11 print(res.query) # SELECT `app01_movie`.`id`, `app01_movie`.`title`, `app01_movie`.`price`, `app01_movie`.`publish_time` FROM `app01_movie` WHERE (`app01_movie`.`id` = 1 AND `app01_movie`.`title` = 水浒传)
4.get()
1 # 4.get() 直接获取条件查询得到的数据的对象本身(和create创建时返回的是一样的) 不推荐使用 当查询条件不存在的时候直接报错 2 res = models.Movie.objects.get(pk=1) 3 print(res) 4 res = models.Movie.objects.get(pk=5) 5 print(res) # 报错信息:app01.models.DoesNotExist: Movie matching query does not exist. 6 res = models.Movie.objects.filter(pk=5) # 而使用filter查询找不到会返回一个空列表 7 print(res)
5.values()
1 # 5.values() 查询指定字段下的所有值,可以多个字段一起查,结果是列表套字典的形式 2 res = models.Movie.objects.values('title', 'price') 3 #查询结果:<QuerySet [{'title': '西游记', 'price': Decimal('666.66')}, {'title': '水浒传', 'price': Decimal('888.88')}, {'title': '三国演义', 'price': Decimal('999.99')}, {'title': '西游记', 'price': Decimal('666.66')}]> 4 print(res) 5 print(res.query) 6 # SELECT `app01_movie`.`title`, `app01_movie`.`price` FROM `app01_movie`
6.values_list()
1 # 6.values_list() 查询指定字段下的所有值,可以多个字段一起查,结果是列表套元组的形式 2 res = models.Movie.objects.values_list('title', 'price') 3 # < QuerySet[('西游记', Decimal('666.66')), ('水浒传', Decimal('888.88')), ('三国演义', Decimal('999.99')), ( 4 # '红楼梦', Decimal('666.66'))] > 5 print(res)
7.first()
1 # # 7.first() 查询所得结果的第一个元素对象,若不给前置条件则默认获得全部数据的第一个数据对象 2 res1 = models.Movie.objects.filter() # <QuerySet [<Movie: Movie object>, <Movie: Movie object>, <Movie: Movie object>, <Movie: Movie object>]> 3 res2 = models.Movie.objects.filter().first() # Movie object 4 res3 = models.Movie.objects.first() 5 6 print(res1) 7 print(res2) 8 print(res3)
8.last()
1 # 8.last() 查询所得结果的最后一个元素对象,若不给前置条件则默认获得全部数据的最后一个数据对象 2 res1 = models.Movie.objects.filter().last() 3 res = models.Movie.objects.last() 4 print(res1) 5 print(res)
9.update()
1 # 9.update() 表示跟新数据,获取指定数据对象后可以进行修改,但不能在未有此数据的情况下添加数据,并且也有返回值,返回值是被影响的行数 2 res = models.Movie.objects.filter(pk=1).update(title='聊斋志异') 3 res2 = models.Movie.objects.filter(pk=5).update(title='西游记', price=777.77, publish_time='2018-10-1') 4 print(res) 5 print(res2)
10.delete()
1 # 10.delete() 删除数据 返回结果(1, {'app01.Movie': 1}) 2 res = models.Movie.objects.filter(pk = 1).delete() 3 # 不用主键为条件可以删除多个同一条件的元素 (3, {'app01.Movie': 3}) 4 res = models.Movie.objects.filter(price = 11).delete() 5 print(res)
11.count()
1 # 11.count() 统计数据条数,返回值是数据条数 2 # 不给条件会查询所有数据条数, 3 res = models.Movie.objects.count() 4 # 会通过条件来查询数据条数 5 res2 = models.Movie.objects.filter(price=100).count() 6 print(res) 7 print(res2)
12.order_by
order_by
13.exclude()
1 # 13.exclude() 将指定筛选条件的数据对象排除之后获取剩下的所有数据对象 2 # 返回结果是一个queryset,<QuerySet [<Movie: 三国演义>, <Movie: 红楼梦>, <Movie: sjal>, <Movie: nqks>, <Movie: skxsl>]> 3 res = models.Movie.objects.exclude(pk=2) 4 print(res) 5 print(res.query) 6 # SELECT `app01_movie`.`id`, `app01_movie`.`title`, `app01_movie`.`price`, `app01_movie`.`publish_time` FROM `app01_movie` WHERE NOT (`app01_movie`.`id` = 2)
14.exists()
1 # 14.exists() 返回的是布尔值 判断指定筛选条件的数据是否存在 2 res = models.Movie.objects.filter(pk=1000).exists() 3 print(res)
15.reverse()
# 15.reverse() 反转, 将升序改为降序,返回的结果是一个queryset对象 res = models.Movie.objects.order_by('price').reverse() print(res) print(res.query) # SELECT `app01_movie`.`id`, `app01_movie`.`title`, `app01_movie`.`price`, `app01_movie`.`publish_time` FROM `app01_movie` ORDER BY `app01_movie`.`price` DESC
16.distinct()
# 16.distinct() 去重:把重复的数据去掉,去重的前提 必须是由完全一样的数据的才可以 #返回的结果是一个queryset res = models.Movie.objects.values('price').distinct() print(res) print(res.query) # SELECT DISTINCT `app01_movie`.`price` FROM `app01_movie`
3)神奇的双下划线查询
1 # 1.__gt:表是大于 2 # 查询价格大于100的电影 3 res = models.Movie.objects.filter(price__gt=100) 4 # 返回的结果是一个queryset数据对象列表 5 print(res) 6 print(res.query) 7 # # SELECT `app01_movie`.`id`, `app01_movie`.`title`, `app01_movie`.`price`, `app01_movie`.`publish_time` FROM `app01_movie` WHERE `app01_movie`.`price` > 100 8 9 # 2.__lt:表示小于 10 # 查询价格小于200的电影 11 res = models.Movie.objects.filter(price__lt=200) 12 # 返回的结果是一个queryset数据对象列表 13 print(res) 14 print(res.query) 15 # SELECT `app01_movie`.`id`, `app01_movie`.`title`, `app01_movie`.`price`, `app01_movie`.`publish_time` FROM `app01_movie` WHERE `app01_movie`.`price` < 200 16 17 # 3.__gte:表示大于等于 18 # 查询价格大于等于888.88的电影 19 res = models.Movie.objects.filter(price__gte=888.88) 20 print(res) 21 print(res.query) 22 # SELECT `app01_movie`.`id`, `app01_movie`.`title`, `app01_movie`.`price`, `app01_movie`.`publish_time` FROM `app01_movie` WHERE `app01_movie`.`price` >= 88.8799999999999954525264911353588104248046875 23 # 4.__lte:表示小于等于 24 # 查询价格小于等于666.66的电影 25 res = models.Movie.objects.filter(price__lte=666.66) 26 print(res) 27 print(res.query) 28 # SELECT `app01_movie`.`id`, `app01_movie`.`title`, `app01_movie`.`price`, `app01_movie`.`publish_time` FROM `app01_movie` WHERE `app01_movie`.`price` <= 666.6599999999999681676854379475116729736328125 29 30 # 5.__in:表示获取一个可迭代对象里面的数据 31 #查询价格是666 或888 或999(注意:由于python解释器的精度问题,查询的时候可能会出现找不到数据的情况) 32 res = models.Movie.objects.filter(price__in=[888.88, 666.66, 999.99]) 33 print(res) 34 # # <QuerySet []> 35 print(res.query) 36 # # #SELECT `app01_movie`.`id`, `app01_movie`.`title`, `app01_movie`.`price`, `app01_movie`.`publish_time` FROM `app01_movie` WHERE `app01_movie`.`price` IN (888.8799999999999954525264911353588104248046875, 666.6599999999999681676854379475116729736328125, 999.990000000000009094947017729282379150390625) 37 res1 = models.Movie.objects.filter(price__in=(888, 666, 999)) 38 # 元组字典都可以,都是返回一个queryset数据对象列表 39 res2 = models.Movie.objects.filter(price__in=[888, 666, 999]) 40 print(res1) 41 print(res2) 42 # # < QuerySet[ < Movie: 水浒传 >, < Movie: 三国演义 >, < Movie: 红楼梦 >] > 43 print(res1.query) 44 # # SELECT `app01_movie`.`id`, `app01_movie`.`title`, `app01_movie`.`price`, `app01_movie`.`publish_time` FROM `app01_movie` WHERE `app01_movie`.`price` IN (888, 666, 999) 45 46 # 6.__range:表示在一个可迭代对象里面循环遍历,顾头顾尾 47 # 查询价格在200到900之间的电影 48 res = models.Movie.objects.filter(price__range=(200,999)) 49 print(res) 50 print(res.query) 51 # <QuerySet [<Movie: 水浒传>, <Movie: 三国演义>, <Movie: 红楼梦>]> 52 # SELECT `app01_movie`.`id`, `app01_movie`.`title`, `app01_movie`.`price`, `app01_movie`.`publish_time` FROM `app01_movie` WHERE `app01_movie`.`price` BETWEEN 200 AND 999 53 54 # 7.__contains:模糊查询,有大小写区别 55 # __icontains:模糊查询,忽略大小写 56 57 # 查询电影名中包含字母s的电影 58 ''' 59 模糊查询: 60 关键字 like 61 关键符号:% _ 62 ''' 63 res1 = models.Movie.objects.filter(title__contains='s') # 默认是区分大小写 64 print(res1) 65 print(res1.query) 66 # <QuerySet [<Movie: sjal>, <Movie: nqks>, <Movie: skxsl>]> 67 # SELECT `app01_movie`.`id`, `app01_movie`.`title`, `app01_movie`.`price`, `app01_movie`.`publish_time` FROM `app01_movie` WHERE `app01_movie`.`title` LIKE BINARY %s% 68 69 res2 = models.Movie.objects.filter(title__icontains='s') # 默认是不区分大小的 70 print(res2) 71 print(res2.query) 72 # <QuerySet [<Movie: sjal>, <Movie: nqks>, <Movie: skxsl>, <Movie: SNAJD>, <Movie: SNAKJK>]> 73 # SELECT `app01_movie`.`id`, `app01_movie`.`title`, `app01_movie`.`price`, `app01_movie`.`publish_time` FROM `app01_movie` WHERE `app01_movie`.`title` LIKE %s% 74 75 # 8.__year:指定年份查询 76 # __month:指定月份查询 77 res = models.Movie.objects.filter(publish_time__year=2019) 78 print(res) 79 print(res.query) 80 # <QuerySet [<Movie: sjal>, <Movie: nqks>]> 81 # SELECT `app01_movie`.`id`, `app01_movie`.`title`, `app01_movie`.`price`, `app01_movie`.`publish_time` FROM `app01_movie` WHERE `app01_movie`.`publish_time` BETWEEN 2019-01-01 AND 2019-12-31 82 83 res = models.Movie.objects.filter(publish_time__month=1) 84 print(res) 85 print(res.query) 86 # <QuerySet [<Movie: 水浒传>, <Movie: 三国演义>, <Movie: 红楼梦>]> 87 # SELECT `app01_movie`.`id`, `app01_movie`.`title`, `app01_movie`.`price`, `app01_movie`.`publish_time` FROM `app01_movie` WHERE EXTRACT(MONTH FROM `app01_movie`.`publish_time`) = 1 88 89 #
4)外键字段的增删改查
1 # 外键字段的增删改查 2 # 一对多 书籍对出版社 3 # 1.增 create 4 # 可以通过直接赋值的方式 5 models.Book.objects.create(title='三国演义', price=123.12,publish_id=2) 6 # 或者通过数据对象(在models类中创建书籍对出版社时建立了一个publish外键字段,这个字段支持传对象给他) 7 publish_obj = models.Publish.objects.get(pk=1) 8 print(publish_obj) 9 # # Publish object 10 models.Book.objects.create(title='水浒传', price=134.12, publish=publish_obj) 11 12 #改 update 13 models.Book.objects.filter(pk=1).update(publish_id=3) 14 15 # 通过get直接拿到主键值为4的出版社数据对象 16 publish_obj = models.Publish.objects.get(pk=4) 17 # 将此对象传给Book里面主键为1的创建时用到的publish虚拟外键字段 18 models.Book.objects.filter(pk=1).update(publish=publish_obj) 19 20 # 删 21 ''' 22 外键字段在1.X版本中默认就是级联更新级联删除的 23 ''' 24 25 # 多对多 26 # 1.给书籍作者绑定关系 add 27 28 # 通过获取书籍对象来对跨表找到作者信息并人为添加一个主键信息 29 book_obj = models.Book.objects.filter(pk=1).first() 30 print(book_obj.authors) # 打印结果app01.Author.None 书籍对象点虚拟字段authors就类似于已经跨到书籍和作者的第三张关系表中 31 book_obj.authors.add(1) #给书籍绑定一个主键为1的作者 32 book_obj.authors.add(2,3) # 也支持同时传多个参数 33 34 35 # 通过方法获取某一条作者信息数据对象,通过add的方法将对象添加进去 36 author_obj = models.Author.objects.get(pk=1) 37 author_obj1 = models.Author.objects.get(pk=3) 38 39 book_obj.authors.add(author_obj) 40 book_obj.authors.add(author_obj1) 41 ''' 42 总结 43 add专门给第三张关系表添加数据 44 括号内即可以传数字也可以传对象 并且都支持传多个 45 ''' 46 # 2 移除书籍与作者的绑定关系 remove 47 book_obj = models.Book.objects.filter(pk=1).first() 48 book_obj.authors.remove(2) 49 book_obj.authors.remove(1,3) 50 author_obj = models.Author.objects.get(pk=2) 51 author_obj1 = models.Author.objects.get(pk=3) 52 book_obj.authors.remove(author_obj) 53 book_obj.authors.remove(author_obj,author_obj1) 54 """ 55 remove专门给第三张关系表移除数据 56 括号内即可以传数字也可以传对象 并且都支持传多个 57 """ 58 # 3 修改书籍与作者的关系 set 59 book_obj = models.Book.objects.filter(pk=1).first() 60 book_obj.authors.set((3,)) 61 book_obj.authors.set((2,3)) 62 author_obj = models.Author.objects.get(pk=2) 63 author_obj1 = models.Author.objects.get(pk=3) 64 book_obj.authors.set((author_obj,)) 65 book_obj.authors.set([author_obj,author_obj1]) 66 67 """ 68 set 修改书籍与作者的关系 69 括号内支持传数字和对象 但是需要是可迭代对象 70 """ 71 # 4 清空书籍与作者关系 72 book_obj = models.Book.objects.filter(pk=1).first() 73 book_obj.authors.clear() # 去第三张表中清空书籍为1的所有数据 74 """ 75 clear() 清空关系 76 不需要任何的参数 77 """
二.跨表查询
1) 跨表查询的方式
1.子查询 将一张表的查询结果当做另外一张表的查询条件
正常解决问题的思路 分步操作
2.链表查询
inner join
left join
right join
union
建议:在写sql语句或者orm语句的时候 千万不要想着一次性将语句写完 一定要写一点查一点再写一点
2)正反向查询
正向
跨表查询的时候 外键字段是否在当前数据对象中 如果在
查询另外一张关系表 叫正向
反向
如果不在叫反向
口诀
正向查询按外键字段
反向查询按表名小写以及视情况添加添加_set.all()
3)基于对象的跨表查询(子查询)
1 # 基于对象的跨表查询(子查询) 2 1.查询书籍pk为1的出版社名称 3 book_obj = models.Book.objects.filter(pk=1).first() 4 print(book_obj.publish) # 结果:Publish object 5 print(book_obj.publish.name) # 西方出版社 6 print(book_obj.publish.addr) # 白宫 7 8 # 2.查询书籍pk为2的所有作者的姓名 9 book_obj = models.Book.objects.filter(pk=1).first() 10 # 正向查询看外键字段 11 print(book_obj.authors) 12 # 结果:app01.Author.None 意味这没有写错 13 print(book_obj.authors.all()) # 因为书籍对应的有多个作者,添加all获取所有, 14 # 结果为:<QuerySet [<Author: Author object>, <Author: Author object>, <Author: Author object>]> 15 author_list = book_obj.authors.all() 16 for author_obj in author_list: 17 print(author_obj.name) 18 19 20 # 3.查询作者pk为1的电话号码 21 author_obj = models.Author.objects.filter(pk=1).first() 22 print(author_obj.author_detail) 23 print(author_obj.author_detail.phone) 24 print(author_obj.author_detail.addr)
总结1:
正向查询的时候 当外键字段对应的数据可以有多个的时候需要加.all(),这样就可以获取所有的对应信息,否则查到的结果为app.表名.None
1 # 4.查询出版社名称为东方出版社出版过的书籍 2 publish_obj = models.Publish.objects.filter(name='东方出版社').first() 3 print(publish_obj.book) # 这样直接小写会报错AttributeError: 'Publish' object has no attribute 'book' 4 改成 5 print(publish_obj.book_set) # app01.Book.None 6 print(publish_obj.book_set.all()) # <QuerySet [<Book: Book object>]> 7 print(publish_obj.book_set.all().first().title) 8 9 # 5.查询作者为李四写过的书 10 author_obj = models.Author.objects.filter(name='李四').first() 11 print(author_obj.book_set) # app01.Book.None 12 print(author_obj.book_set.all()) 13 14 # 6.查询手机号为11234的作者姓名 15 author_detail_obj = models.AuthorDetail.objects.filter(phone=11234).first() 16 print(author_detail_obj.author) # Author object 基于一对一关系不需要_set_all 17 print(author_detail_obj.author.name) 18 print(author_detail_obj.author.age)
总结2:
基于对象的反向查询 表名小写是否需要加_set.all()
一对多和多对多的时候需要加
一对一不需要
4)基于双下划线跨表查询(链表查询)
1 # 基于双下划线跨表查询(链表查询) 2 # 1.查询书籍pk为1的出版社名称 3 # 正向 4 res1 = models.Book.objects.filter(pk=1).values('title') 5 print(res1) 6 # 结果:<QuerySet [{'title': '三国演义'}]> 7 res2 = models.Book.objects.filter(pk=1).values('publish') # 写外键字段 就意味着你已经在外键字段管理的那张表中 8 print(res2) 9 # 结果:<QuerySet [{'publish': 4}]> 10 res3 = models.Book.objects.filter(pk=1).values('publish__name') 11 print(res3) 12 # <QuerySet [{'publish__name': '西方出版社'}]> 13 14 15 # 反向 16 res = models.Publish.objects.filter(book__pk=1) 17 print(res) 18 # 结果:<QuerySet [<Publish: Publish object>]> 19 res1 = models.Publish.objects.filter(book__pk=1).first() 20 print(res1) 21 # 结果: Publish object 后面再加.name就能拿到具体名字 22 res2 = models.Publish.objects.filter(book__pk=1).values('name') 23 print(res2) 24 # 结果:<QuerySet [{'name': '西方出版社'}]> 25 26 # 3.查询作者是李四的年龄和手机号 27 # 正向 28 res = models.Author.objects.filter(name='李四').values('age','author_detail__phone') 29 print(res) 30 # 反向 31 res = models.AuthorDetail.objects.filter(author__name='李四') # 拿到jason的个人详情 32 res = models.AuthorDetail.objects.filter(author__name='李四').values('phone','author__age') 33 print(res) 34 35 # 查询书籍pk为的1的作者的手机号 36 res = models.Book.objects.filter(pk=1).values('authors__author_detail__phone') 37 print(res) 38 39 res = models.AuthorDetail.objects.filter(author__book__pk=1).values('phone') 40 print(res) 41 42 """ 43 只要表之间有关系 你就可以通过正向的外键字段或者反向的表名小写 连续跨表操作 44 """
三.聚合查询
关键字
aggregate
1 from django.db.models import Max,Min,Avg,Count,Sum 2 # 聚合查询要导入的模块 3 # 查询所有书的平均价格 4 res = models.Book.objects.aggregate(avg_num=Avg('price')) 5 print(res) 6 # 查询价格最贵的书 7 res = models.Book.objects.aggregate(max_num=Max('price')) 8 print(res) 9 # 全部使用一遍 10 res = models.Book.objects.aggregate(Avg("price"), Max("price"), Min("price"),Count("pk"),Sum('price')) 11 print(res)
四.分组查询
关键字
annotate
1 # 1.统计每一本书的作者个数 2 res = models.Book.objects.annotate(author_num=Count('authors')).values('title','author_num') 3 print(res) 4 5 # 2.统计出每个出版社卖的最便宜的书的价格 6 res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name','min_price','book__title') 7 print(res) 8 9 # 3.统计不止一个作者的图书 10 res = models.Book.objects.annotate(author_num=Count('authors')).filter(author_num__gt=1).values('title') 11 print(res) 12 13 # 4.查询各个作者出的书的总价格 14 res = models.Author.objects.annotate(price_sum=Sum('book__price')).values('name','price_sum') 15 print(res) 16 17 # 5.如何按照表中的某一个指定字段分组 18 """ 19 res = models.Book.objects.values('price').annotate() 就是以价格分组 20 """
五.F与Q查询
1 from django.db.models import F,Q 2 # 1.查询库存数大于卖出数的书籍 3 res = models.Book.objects.filter(kucun__gt=F('maichu')) 4 print(res) 5 6 # 2.将所有书的价格提高100 7 res = models.Book.objects.update(price=F('price') + 100) 8 """ 9 帮你获取到表中某个字段对应的值 10 """ 11 # Q能够改变查询的条件关系 and or not 12 # 1.查询书的名字是python入门或者价格是1000的书籍 13 res = models.Book.objects.filter(title='python入门',price=1000) # and关系 14 res = models.Book.objects.filter(Q(title='python入门'),Q(price=1000)) # 逗号是and关系 15 res = models.Book.objects.filter(Q(title='python入门')|Q(price=1000)) # |是or关系 16 res = models.Book.objects.filter(~Q(title='python入门')|Q(price=1000)) # ~是not关系 17 print(res.query)
1 高阶用法(了解) 2 应用场景 3 当你写的业务逻辑有组合查询 4 title price 1000 5 查询title中包含1000或者price中包含1000的数据 __icontains 6 参考点:django admin后台管理搜索功能 7 q = Q() 8 q.connector = 'or' # 可以修改查询关系 and or 9 q.children.append(('title',1000)) 10 q.children.append(('price',1000)) 11 res = models.Book.objects.filter(q) # 默认还是and关系 但是可以修改为or

 浙公网安备 33010602011771号
浙公网安备 33010602011771号