

Python之编码
Python2编码
str和unicode
str和unicode都是basestring的子类。严格意义上说,str其实是字节串,它是unicode经过编码后的字节组成的序列。对UTF-8编码的str'苑'使用len()函数时,结果是3,因为utf8编码的'苑' == '\xe8\x8b\x91'。
而unicode是一个字符串,str是unicode这个字符串经过编码(utf8,gbk等)后的字节组成的序列。如上面utf8编码的字符串'汉'。
unicode才是真正意义上的字符串,对字节串str使用正确的字符编码进行解码后获得,并且len(u'苑') == 1。
在Py2里,'你好'真正的存储的数据类型是bytes类型的数据, u'你好'存储的是unicode类型的数据。
py2编码的最大特点是Python 2 将会自动的将bytes数据解码成 unicode 字符串
所以在2里我们可以将字节与字符串拼接。
#coding:utf8 print '苑昊' # 苑昊 print repr('苑昊')#'\xe8\x8b\x91\xe6\x98\x8a' print (u"hello"+"yuan") # helloyuan print (u'苑昊'+'最帅') #UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 in position 0: ordinal not in range(128)
两个问题:
1 print '苑昊' :本来存的是'\xe8\x8b\x91\xe6\x98\x8a',为什么显示了 苑昊 的明文?
2 字节串和字符串可以拼接?
这就是那些可恶的 UnicodeError 。你的代码中包含了 unicode 和 byte 字符串,只要数据全部是 ASCII 的话,所有的转换都是正确的,一旦一个非 ASCII 字符偷偷进入你的程序,那么默认的解码将会失效,从而造成 UnicodeDecodeError 的错误。
Python 2 悄悄掩盖掉了 byte 到 unicode 的转换,让程序在处理 ASCII 的时候更加简单。你复出的代价就是在处理非 ASCII 的时候将会失败。
再来看看encode()和decode()两个basestring的实例方法,理解了str和unicode的区别后,这两个方法就不会再混淆了:
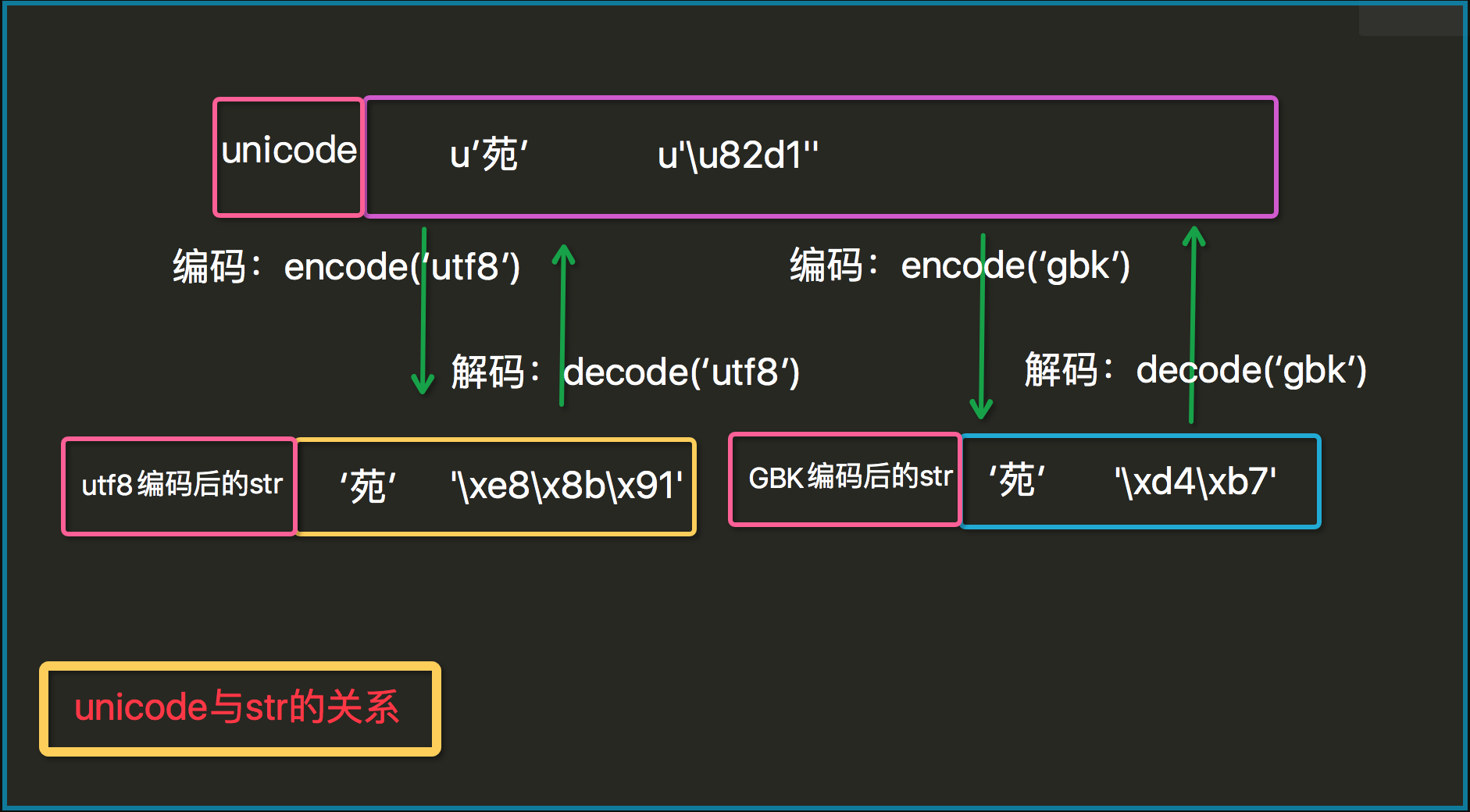
#coding:utf8 u = u'苑' print repr(u) # u'\u82d1' # print str(u) #UnicodeEncodeError s = u.encode('utf8') print repr(s) #'\xe8\x8b\x91' print str(s) # 苑 u2 = s.decode('utf8') print repr(u2) # u'\u82d1'
在python3中:
encode: 将某个字符串按照某种编码方式编成字节码bytes
decode: 将某段字节码bytes按照某种解码方式解码成字符串

 浙公网安备 33010602011771号
浙公网安备 33010602011771号