

大规模语言模型Transformer架构
1.1 大规模语言模型的发展可以粗略的分为如下三个阶段:基础模型、能力探索、突破发展。
基础模型阶段主要集中于 2018 年至 2021 年,2017 年 Vaswani 等人提出了 Transformer架构,在机器翻译任务上取得了突破性进展。2018 年 Google 和 Open AI 分别提出了 BERT和GPT1模型,开启了预训练语言模型时代。
能力探索阶段集中于 2019 年至 2022 年,由于大规模语言模型很难针对特定任务进行微调,研究人员们开始探索在不针对单一任务进行微调的情况下如何能够发挥大规模语言模型的能力。
突破发展阶段以 2022 年 11 月 ChatGPT 的发布为起点。ChatGPT 通过一个简单的对话框,利用一个大规模语言模型就可以实现问题回答、文稿撰写、代码生成、数学解题等过去自然语言处理系统需要大量小模型订制开发才能分别实现的能力。
它在开放领域问答、各类自然语言生成式任务以及对话上文理解上所展现出来的能力远超大多数人的想象。2023 年 3 月 GPT-4 发布,相较于ChatGPT 又有了非常明显的进步,并具备了多模态理解能力。GPT-4 在多种基准考试测试上的得分高于88%
的应试者,包括美国律师资格考试(Uniform Bar Exam)、法学院入学考试(Law School6 Admission Test)、学术能力评估(Scholastic Assessment Test,SAT)等。它展现了近乎“通用人工智能(AGI)”的能力。各大公司和研究机构也相继
发布了此类系统,包括 Google 推出的 Bard、百度的文心一言、科大讯飞的星火大模型、智谱 ChatGLM、复旦大学 MOSS 等。
1.2 大规模语言模型构建流程
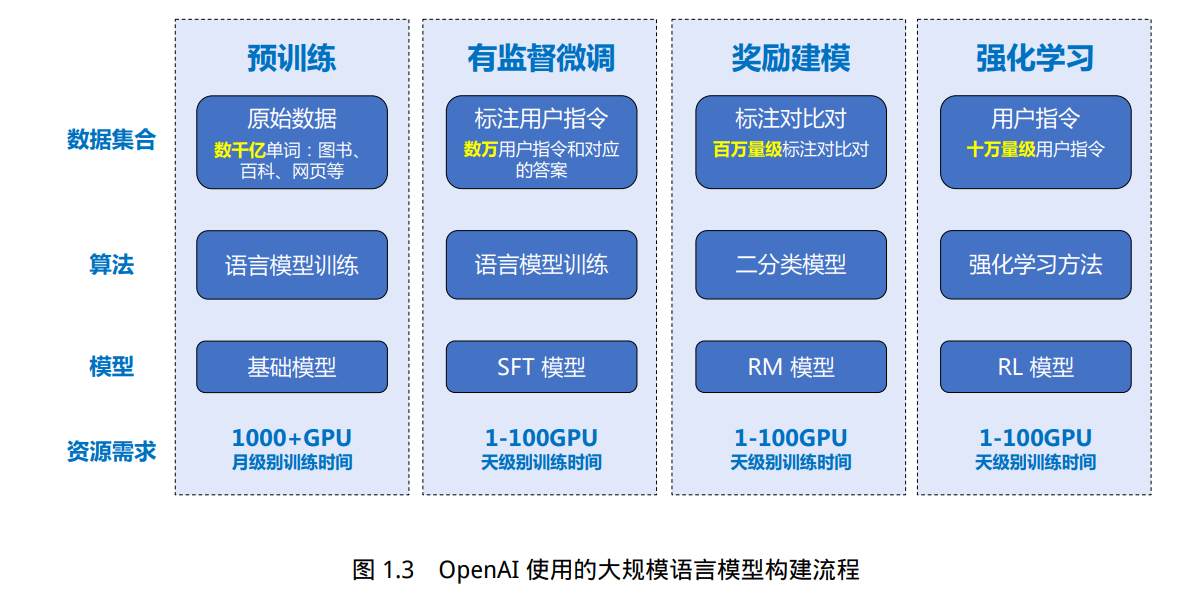
要包含四个阶段:预训练、有监督微调、奖励建模、强化学习。
2.1 Transformer 模型
Transformer 模型是由谷歌在 2017 年提出并首先应用于机器翻译的神经网络模型结构。机器翻译的目标是从源语言(Source Language)转换到目标语言(Target Language)。Transformer 结构完全通过注意力机制完成对源语言序列和目标
语言序列全局依赖的建模。当前几乎全部大语言模型都是基于 Transformer 结构,本节以应用于机器翻译的基于 Transformer 的编码器和解码器介绍该模型。
基于 Transformer 结构的编码器和解码器结构如图2.1所示
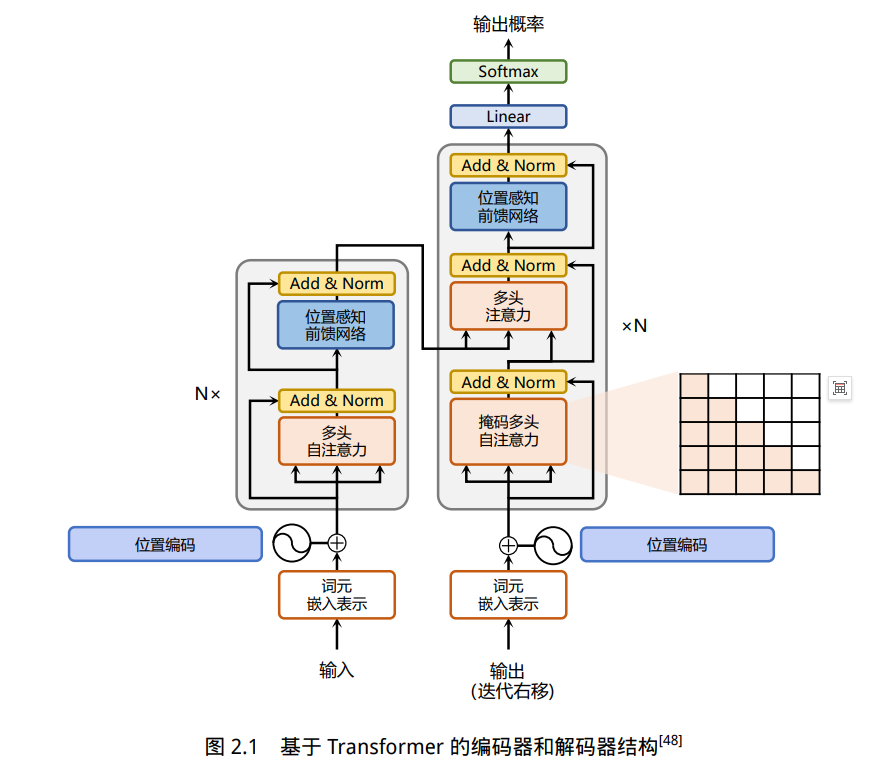
左侧和右侧分别对应着编码器(Encoder)和解码器(Decoder)结构。它们均由若干个基本的Transformer 块(Block)组成(对应着图中的灰色框)。主要涉及到如下几个模块:
• 注意力层:使用多头注意力(Multi-Head Attention)机制整合上下文语义,它使得序列中任意两个单词之间的依赖关系可以直接被建模而不基于传统的循环结构,从而更好地解决文本的长程依赖。
• 位置感知前馈层(Position-wise FFN):通过全连接层对输入文本序列中的每个单词表示进行更复杂的变换。
• 残差连接:对应图中的 Add 部分。它是一条分别作用在上述两个子层当中的直连通路,被用于连接它们的输入与输出。从而使得信息流动更加高效,有利于模型的优化。
• 层归一化:对应图中的 Norm 部分。作用于上述两个子层的输出表示序列中,对表示序列进行层归一化操作,同样起到稳定优化的作用。
2.2 基于 HuggingFace 的预训练语言模型实践
HuggingFace 是一个开源自然语言处理软件库。其的目标是通过提供一套全面的工具、库和模型,使得自然语言处理技术对开发人员和研究人员更加易于使用。HuggingFace 最著名的贡献之一是 Transformer 库,基于此研究人员可以快速部署训
练好的模型以及实现新的网络结构。除此之外,HuggingFace 还提供了 Dataset 库,可以非常方便地下载自然语言处理研究中最常使用的基准数据集。本节中,将以构建 BERT 模型为例,介绍基于 Huggingface 的 BERT 模型构建和使用方法。
2.2.1. 数据集合准备
常见的用于预训练语言模型的大规模数据集都可以在 Dataset 库中直接下载并加载。例如,如果使用维基百科的英文语料集合,可以直接通过如下代码完成数据获取:
点击查看代码
from datasets import concatenate_datasets, load_dataset
bookcorpus = load_dataset("bookcorpus", split="train")
wiki = load_dataset("wikipedia", "20230601.en", split="train")
# 仅保留 'text' 列
wiki = wiki.remove_columns([col for col in wiki.column_names if col != "text"])
dataset = concatenate_datasets([bookcorpus, wiki])
# 将数据集合切分为 90% 用于训练,10% 用于测试
d = dataset.train_test_split(test_size=0.1)
点击查看代码
def dataset_to_text(dataset, output_filename="data.txt"):
"""Utility function to save dataset text to disk,
useful for using the texts to train the tokenizer
(as the tokenizer accepts files)"""
with open(output_filename, "w") as f:
for t in dataset["text"]:
print(t, file=f)
# save the training set to train.txt
dataset_to_text(d["train"], "train.txt")
# save the testing set to test.txt
dataset_to_text(d["test"], "test.txt")
点击查看代码
special_tokens = [
"[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]", "<S>", "<T>"
]
# if you want to train the tokenizer on both sets
# files = ["train.txt", "test.txt"]
# training the tokenizer on the training set
files = ["train.txt"]
# 30,522 vocab is BERT's default vocab size, feel free to tweak
vocab_size = 30_522
# maximum sequence length, lowering will result to faster training (when increasing batch size)
max_length = 512
# whether to truncate
truncate_longer_samples = False
# initialize the WordPiece tokenizer
tokenizer = BertWordPieceTokenizer()
# train the tokenizer
tokenizer.train(files=files, vocab_size=vocab_size, special_tokens=special_tokens)
# enable truncation up to the maximum 512 tokens
tokenizer.enable_truncation(max_length=max_length)
model_path = "pretrained-bert"
# make the directory if not already there
if not os.path.isdir(model_path):
os.mkdir(model_path)
# save the tokenizer
tokenizer.save_model(model_path)
# dumping some of the tokenizer config to config file,
# including special tokens, whether to lower case and the maximum sequence length
with open(os.path.join(model_path, "config.json"), "w") as f:
tokenizer_cfg = {
"do_lower_case": True,
"unk_token": "[UNK]",
"sep_token": "[SEP]",
"pad_token": "[PAD]",
"cls_token": "[CLS]",
"mask_token": "[MASK]",
"model_max_length": max_length,
"max_len": max_length,
}
json.dump(tokenizer_cfg, f)
# when the tokenizer is trained and configured, load it as BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained(model_path)
点击查看代码
def encode_with_truncation(examples):
"""Mapping function to tokenize the sentences passed with truncation"""
return tokenizer(examples["text"], truncation=True, padding="max_length",
max_length=max_length, return_special_tokens_mask=True)
def encode_without_truncation(examples):
"""Mapping function to tokenize the sentences passed without truncation"""
return tokenizer(examples["text"], return_special_tokens_mask=True)
# the encode function will depend on the truncate_longer_samples variable
encode = encode_with_truncation if truncate_longer_samples else encode_without_truncation
# tokenizing the train dataset
train_dataset = d["train"].map(encode, batched=True)
# tokenizing the testing dataset
test_dataset = d["test"].map(encode, batched=True)
if truncate_longer_samples:
# remove other columns and set input_ids and attention_mask as PyTorch tensors
train_dataset.set_format(type="torch", columns=["input_ids", "attention_mask"])
test_dataset.set_format(type="torch", columns=["input_ids", "attention_mask"])
else:
# remove other columns, and remain them as Python lists
test_dataset.set_format(columns=["input_ids", "attention_mask", "special_tokens_mask"])
train_dataset.set_format(columns=["input_ids", "attention_mask", "special_tokens_mask"])
点击查看代码
from itertools import chain
# Main data processing function that will concatenate all texts from our dataset
# and generate chunks of max_seq_length.
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, we could add padding if the model supported it instead of
# this drop, you can customize this part to your needs.
if total_length >= max_length:
total_length = (total_length // max_length) * max_length
# Split by chunks of max_len.
result = {
k: [t[i : i + max_length] for i in range(0, total_length, max_length)]
for k, t in concatenated_examples.items()
}
return result
# Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws
# away a remainder for each of those groups of 1,000 texts. You can adjust that batch_size here but
# a higher value might be slower to preprocess.
#
# To speed up this part, we use multiprocessing. See the documentation of the map method
#for more information:
# https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map
if not truncate_longer_samples:
train_dataset = train_dataset.map(group_texts, batched=True,
desc=f"Grouping texts in chunks of {max_length}")
test_dataset = test_dataset.map(group_texts, batched=True,
desc=f"Grouping texts in chunks of {max_length}")
# convert them from lists to torch tensors
train_dataset.set_format("torch")
test_dataset.set_format("torch")
点击查看代码
# initialize the model with the config
model_config = BertConfig(vocab_size=vocab_size, max_position_embeddings=max_length)
model = BertForMaskedLM(config=model_config)
# initialize the data collator, randomly masking 20% (default is 15%) of the tokens
# for the Masked Language Modeling (MLM) task
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=True, mlm_probability=0.2
)
training_args = TrainingArguments(
output_dir=model_path, # output directory to where save model checkpoint
evaluation_strategy="steps", # evaluate each `logging_steps` steps
overwrite_output_dir=True,
num_train_epochs=10, # number of training epochs, feel free to tweak
per_device_train_batch_size=10, # the training batch size, put it as high as your GPU memory fits
gradient_accumulation_steps=8, # accumulating the gradients before updating the weights
per_device_eval_batch_size=64, # evaluation batch size
logging_steps=1000, # evaluate, log and save model checkpoints every 1000 step
save_steps=1000,
# load_best_model_at_end=True, # whether to load the best model (in terms of loss)
# at the end of training
# save_total_limit=3, # whether you don't have much space so you
# let only 3 model weights saved in the disk
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=test_dataset,
)
# train the model
trainer.train()
点击查看代码
# load the model checkpoint
model = BertForMaskedLM.from_pretrained(os.path.join(model_path, "checkpoint-10000"))
# load the tokenizer
tokenizer = BertTokenizerFast.from_pretrained(model_path)
fill_mask = pipeline("fill-mask", model=model, tokenizer=tokenizer)
# perform predictions
examples = [
"Today's most trending hashtags on [MASK] is Donald Trump",
"The [MASK] was cloudy yesterday, but today it's rainy.",
]
for example in examples:
for prediction in fill_mask(example):
print(f"{prediction['sequence']}, confidence: {prediction['score']}")
print("="*50)
点击查看代码
class MultiQueryAttention(nn.Module):
"""Multi-Query self attention.
Using torch or triton attention implemetation enables user to also use
additive bias.
"""
def __init__(
self,
d_model: int,
n_heads: int,
device: Optional[str] = None,
):
super().__init__()
self.d_model = d_model
self.n_heads = n_heads
self.head_dim = d_model // n_heads
self.Wqkv = nn.Linear( # Multi-Query Attention 创建
d_model,
d_model + 2 * self.head_dim, # 只创建 查询 的 头向量,所以只有 1 个 d_model
device=device, # 而 键 和 值 则共享各自的一个 head_dim 的向量
)
self.attn_fn = scaled_multihead_dot_product_attention
self.out_proj = nn.Linear(
self.d_model,
self.d_model,
device=device
)
self.out_proj._is_residual = True # type: ignore
def forward(
self,
x,
):
qkv = self.Wqkv(x) # (1, 512, 960)
query, key, value = qkv.split( # query -> (1, 512, 768)
[self.d_model, self.head_dim, self.head_dim], # key -> (1, 512, 96)
dim=2 # value -> (1, 512, 96)
)
context, attn_weights, past_key_value = self.attn_fn(
query,
key,
value,
self.n_heads,
multiquery=True,
)
return self.out_proj(context), attn_weights, past_key_value
点击查看代码
# Multi Head Attention
self.Wqkv = nn.Linear( # Multi-Head Attention 的创建方法
self.d_model,
3 * self.d_model, # 查询、键和值 3 个矩阵, 所以是 3 * d_model
device=device
)
query, key, value = qkv.chunk( # 每个 tensor 都是 (1, 512, 768)
3,
dim=2
)
# Multi Query Attention
self.Wqkv = nn.Linear( # Multi-Query Attention 的创建方法
d_model,
d_model + 2 * self.head_dim, # 只创建查询的头向量,所以是 1* d_model
device=device, # 而键和值不再具备单独的头向量
)
query, key, value = qkv.split( # query -> (1, 512, 768)
[self.d_model, self.head_dim, self.head_dim], # key -> (1, 512, 96)
dim=2 # value -> (1, 512, 96)
)
3.1 语言模型训练数据
语言模型训练所需的数据来源大体上可以分为通用数据和专业数据两大类。通用数据(GeneralData)包括网页、图书、新闻、对话文本等内容。通用数据具有规模大、多样性和易获取等特点,因此可以支持大语言模型的构建语言建模和泛化能力。
专业数据(Specialized Data)包括多语言数据、科学数据、代码以及领域特有资料等数据。通过在预训练阶段引入专业数据可以有效提供大语言模型的任务解决能力。
3.1.1 数据处理
数据处理主要包含质量过滤、冗余去除、隐私消除、词元切分等几个步骤。

(1)低质过滤:大语言模型训练中所使用的低质量数据过滤方法可以大致分为两类:基于分类器的方法和基于启发式的方法。
基于分类器的方法目标是训练文本质量判断模型,并利用该模型识别并过滤低质量数据。在实际应用中,还可以通过使用 Pareto 分布对网页进行采样,根据其得分选择合适的阈值,从而选定合适的数据集合。但是,一些研究也发现,基于分类器的
方法可能会删除包含方言或者口语的高质量文本,从而损失一定的多样性。
基于启发式的方法则通过一组精心设计的规则来消除低质量文本,BLOOM 和 Gopher采用了基于启发式的方法。这些启发式规则主要包括:
• 语言过滤:如果一个大语言模型仅关注一种或者几种语言,那么就可以大幅度的过滤掉数据中其他语言的文本。
• 指标过滤:利用评测指标也可以过滤低质量文本。例如,可以使用语言模型对于给定文本的困惑度(Perplexity)进行计算,利用该值可以过滤掉非自然的句子。
• 统计特征过滤:针对文本内容可以计算包括标点符号分布、符号字比(Symbol-to-Word Ratio)、句子长度等等在内的统计特征,利用这些特征过滤低质量数据。
• 关键词过滤:根据特定的关键词集,可以识别和删除文本中的噪声或无用元素,例如,HTML标签、超链接以及冒犯性词语等。
(2)冗余去除:大语言模型训练语料库中的重复数据,会降低语言模型的多样性,并可能导致训练过程不稳定,从而影响模型性能。因此,需要对预训练语料库中的重复进行处理,去除其中的冗余部分。文本冗余发现(Text Duplicate Detection)
也称为文本重复检测,是自然语言处理和信息检索中的基础任务之一,其目标是发现不同粒度上的文本重复,包括句子、段落以及文档等不同级别。冗余去除就是在不同的粒度上进行去除重复内容,包括句子、文档和数据集等粒度的重复。
(3)隐私消除:由于绝大多数预训练数据源于互联网,因此不可避免地会包含涉及敏感或个人信息(PersonallyIdentifiable Information,PII)的用户生成内容,这可能会增加隐私泄露的风险。删除隐私数据最直接的方法是采用基于规则的算法,
BigScience ROOTS Corpus构建过程中就是采用了基于命名实体识别的方法,利用命名实体识别算法检测姓名、地址和电话号码等个人信息内容并进行删除或者替换。该方法使用了基于 Transformer 的模型,并结合机器翻译技术,可以处理超过 100
种语言的文本,消除其中的隐私信息。该算法被集成在 muliwai 类库中。
(4)词元切分:传统的自然语言处理通常以单词为基本处理单元,模型都依赖预先确定的词表 V,在编码输入词序列时,这些词表示模型只能处理词表中存在的词。因此,在使用中,如果遇到不在词表中的未登录词,模型无法为其生成对应的表示,只
能给予这些未登录词(Out-of-vocabulary,OOV)一个默认的通用表示。词元分析(Tokenization)目标是将原始文本分割成由词元(Token)序列的过程。词元切分也是数据预处理中至关重要的一步。
字节对编码(Byte Pair Encoding,BPE)模型是一种常见的子词词元模型。该模型所采用的词表包含最常见的单词以及高频出现的子词。在使用中,常见词通常本身位于 BPE 词表中,而罕见词通常能被分解为若干个包含在 BPE 词表中的词元,从而
大幅度降低未登录词的比例。BPE算法包括两个部分:词元词表的确定;全词切分为词元以及词元合并为全词的方法。
WordPiece也是一种常见的词元分析算法,最初应用于语音搜索系统。此后,该算法做为BERT 的分词器。WordPiece 与 BPE 有非常相似的思想,都是通过迭代地合并连续的词元,但在合并的选择标准上略有不同。为了进行合并,WordPiece 需要首
先训练一个语言模型,并用该语言模型对所有可能的词元对进行评分。在每次合并时,选择使得训练数据似然概率增加最多的词元对。
Unigram 词元分析[101] 是另外一种应用于大语言模型的词元分析方法,T5 和 mBART 采用该方法构建词元分析器。不同于 BPE 和 WordPiece,Unigram 词元分析从一个足够大的可能词元集合开始,然后迭代地从当前列表中删除词元,直到达到预期
的词汇表大小为止。基于训练好的 Unigram语言模型,使用从当前词汇表中删除某个字词后,训练语料库似然性的增加量作为选择标准。为了估计一元语言(Unigram)模型,采用了期望最大化(Expectation–Maximization,EM)算法:每次迭代中,
首先根据旧的语言模型找到当前最佳的单词切分方式,然后重新估计一元语言单元概率以更新语言模型。在这个过程中,使用动态规划算法(如维特比算法)来高效地找到给定语言模型时单词的最佳分解方式。
3.2 开源数据集
3.2.1 Pile 数据集是一个用于大语言模型训练的多样性大规模文本语料库,由 22 个不同的高质量子集构成,包括现有的和新构建的,许多来自学术或专业来源。这些子集包括 Common Crawl、Wikipedia、OpenWebText、ArXiv、PubMed 等。Pile 的
特点是包含了大量多样化的文本,涵盖了不同领域和主题,从而提高了训练数据集的多样性和丰富性。Pile 数据集总计规模大小有 825GB 英文文本,其数据类型组成如图3.12所示,所占面积大小表示数据在整个数据集中所占的规模。
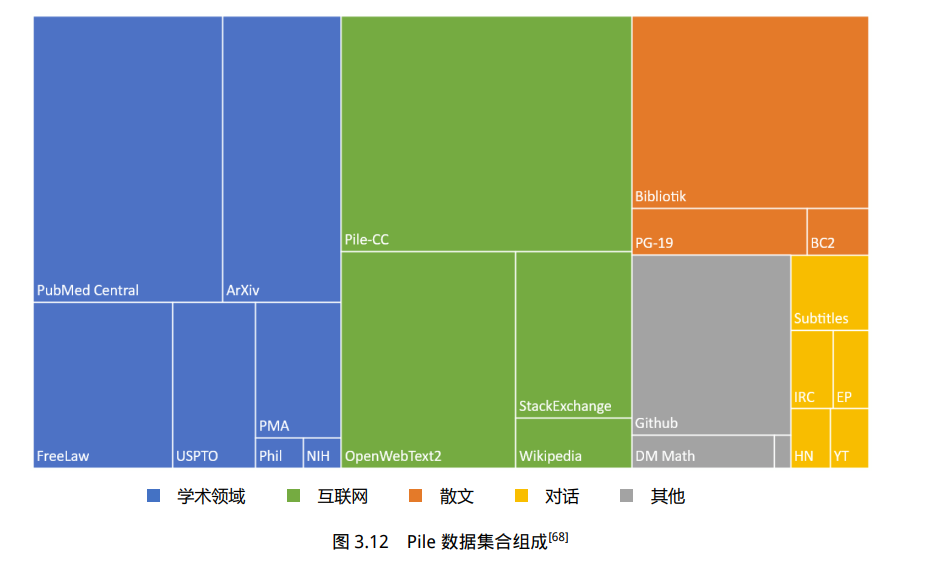
Pile 数据集合所包含的数据由如下 22 个不同子集:
• Pile-CC 是基于 Common Crawl 的数据集,在 Web Archive 文件上使用 jusText的方法进行提取,这比直接使用 WET 文件,产生更高质量的输出。
• PubMed Central(PMC)是由美国国家生物技术信息中心(NCBI)运营的 PubMed 生物医学在线资源库的一个子集,提供对近 500 万份出版物的开放全文访问。
• Books3 是一个图书数据集,来自 Shawn Presser 提供的 Bibliotik。Bibliotik 由小说和非小说类书籍组成,几乎是图书数据集(BookCorpus2)数据量的十倍。
• OpenWebText2 (OWT2)是一个基于 WebText和 OpenWebTextCorpus 的通用数据集。它包括从 Reddit 提交到 2020 年的最新内容、来自多种语言的内容、文档元数据、多个数据集版本和开源复制代码。
• ArXiv 是一个自 1991 年开始运营的研究论文预印版本发布服务,论文主要集中在数学、计算机科学和物理领域。ArXiv 上的论文是用 LaTeX 编写的,对于公式、符号、表格等内容的表示非常适合语言模型学习。
• GitHub 是一个大型的开源代码库,对于语言模型完成代码生成、代码补全等任务具有非常重要的作用。
• Free Law 项目是一个在美国注册的非营利组织,为法律领域的学术研究提供访问和分析工具。CourtListener 是 Free Law 项目的一部分,包含美国联邦和州法院的数百万法律意见,并提供批量下载服务。
• Stack Exchange 一个围绕用户提供问题和答案的网站集合。Stack Exchange Data Dump 包含了在 Stack Exchange 网站集合中所有用户贡献的内容的匿名数据集。它是截止到 2023 年 9月为止公开可用的最大的问题-答案对数据集合之一,涵盖了
广泛的主题,从编程到园艺再到艺术等等。
• USPTO Backgrounds 是美国专利商标局授权的专利背景部分的数据集,来源于其公布的批量档案。典型的专利背景展示了发明的一般背景,给出了技术领域的概述,并建立了问题空间的框架。USPTO 背景,包含了大量关于应用主题的技术文章,面向非技术受众。
• Wikipedia (English) 是维基百科的英文部分。维基百科是一部由全球志愿者协作创建和维护的免费在线百科全书,旨在提供各种主题的知识。它是世界上最大的在线百科全书之一,可用于多种语言,包括英语、中文、西班牙语、法语、德语等等。
• PubMed Abstracts 是由 PubMed 的 3000 万份出版物的摘要组成的数据集。PubMed 是由美国国家医学图书馆运营的生物医学文章在线存储库。PubMed 还包含了 MEDLINE,它包含了1946 年至今的生物医学摘要。
• Project Gutenberg 是一个西方经典文学的数据集。这里使用的是 PG-19,是由 1919 年以前的 Project Gutenberg 中的书籍组成[112],它们代表了与更现代的 Book3 和 BookCorpus 不同的风格。
• OpenSubtitles 是由英文电影和电视的字幕组成的数据集。字幕是对话的重要来源,并且可以增强模型对虚构格式的理解。也可能会对创造性写作任务(如剧本写作、演讲写作、交互式故事讲述等)有一定作用。
• DeepMind Mathematics 数据集包含代数、算术、微积分、数论和概率等一系列数学问题组成,并且以自然语言提示的形式给出[114]。大语言模型在数学任务上的表现较差,这可能部分是由于训练集中缺乏数学问题。因此,Pile 数据集中专门增加了数学问题数
据集,期望增强通过 Pile 数据集训练的语言模型的数学能力。
• BookCorpus2 数据集是原始 BookCorpus的扩展版本,广泛应用于语言建模,甚至包括由“尚未发表”书籍。BookCorpus 与 Project Gutenbergu 以及 Books3 几乎没有重叠。
• Ubuntu IRC 数据集是从 Freenode IRC 聊天服务器上所有与 Ubuntu 相关的频道的公开聊天记录中提取的。聊天记录数据提供了语言模型建模人类交互的可能。
• EuroParl是一个多语言平行语料库,最初是为机器翻译任务构建。但也在自然语言处理的其他几个领域中得到了广泛应用。Pile 数据集中所使用的版本包括 1996 年至 2012年欧洲议会的 21 种欧洲语言的议事录。
• YouTube Subtitles 数据集是从 YouTube 上人工生成的字幕中收集的文本平行语料库。该数据集除了提供了多语言数据之外,还是教育内容、流行文化和自然对话的来源。
• PhilPapers 数据集由 University of Western Ontario 数字哲学中心(Center for Digital Philosophy)维护的国际数据库中的哲学出版物组成。它涵盖了广泛的抽象、概念性的话语,其文本写作质量也非常高。
• NIH Grant Abstracts: ExPORTER 数据集包含 1985 年至今,所有获得美国 NIH 资助的项目申请摘要,是非常高质量的科学写作实例。
• Hacker News 数据集是由初创企业孵化器和投资基金 Y Combinator 运营的链接聚合器。其目标是希望用户提交“任何满足一个人的知识好奇心的内容”,但文章往往聚焦于计算机科学和创业主题。其中包含了一些小众话题的高质量对话和辩论。
• Enron Emails 数据集是由文献 [120] 提出的,用于电子邮件使用模式研究的数据集。该数据集的加入可以帮助语言模型建模电子邮件通信的特性。
3.2.2 ROOTS :Responsible Open-science Open-collaboration Text Sources(ROOTS)数据集合是 BigScience项目在训练具有 1760 亿参数的 BLOOM 大语言模型所使用的数据集合。该数据集合包含 46 种自然语言和 13 种编程语言,
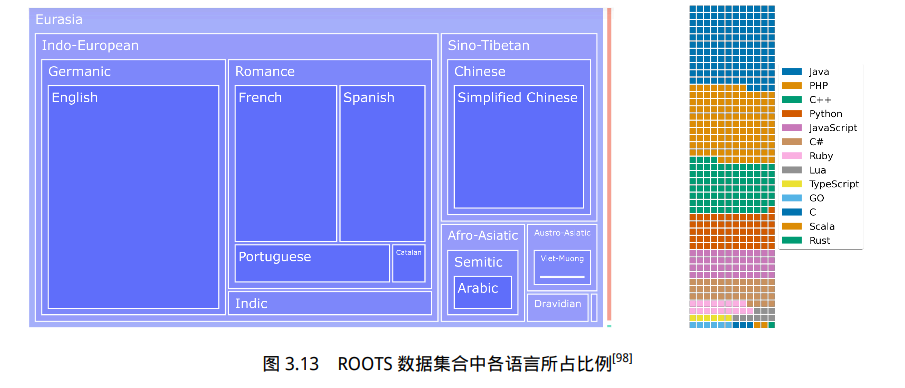
总计 59 种语言,整个数据集的大小约 1.6TB。ROOTS 数据集合中各语言所占比例如图3.13所示。图中左侧是以语言家族的字节数为单位表示的自然语言占比树状图。其中欧亚大陆语言占据了绝大部分(1321.89 GB)。橙色矩形对应是的印度尼西
亚语(18GB),是巴布尼西亚大区唯一的代表。而绿色矩形对应于 0.4GB 的非洲语言。图中右侧是以文件数量为单位的编程语言分布的华夫饼图(Waffle Plot),一个正方形大约对应 3 万个文件。
ROOTS 数据主要来源于四个方面:公开语料、虚拟抓取、GitHub 代码、网页数据。在公开语料方面,BigScience Data Sourcing 工作组目标是收集尽可能多的收集各类型数据,包括自然语言处理数据集以及各类型文档数据集合。为此,还设计了
BigScience Catalogue用于管理和分享大型科学数据集,以及 Masader repository 用于收集阿拉伯语言和文化资源的开放数据存储库。在收集原始数据集的基础上,进一步从语言和统一表示方面对收集的文档进行规范化处理。识别数据集所属语
言并分类存储,并将所有数据都按照统一的文本和元数据结构进行表示。由于数据种类繁多,ROOTS 数据集并没有公开其所包含数据集合情况,但是提供了 Corpus Map 以及 CorpusDescription 工具,可以方便地查询各类数据集占比和数据情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号