mysql 聚集和非聚集索引 解析
一、聚集索引(聚簇索引)
1. 什么是聚集索引?
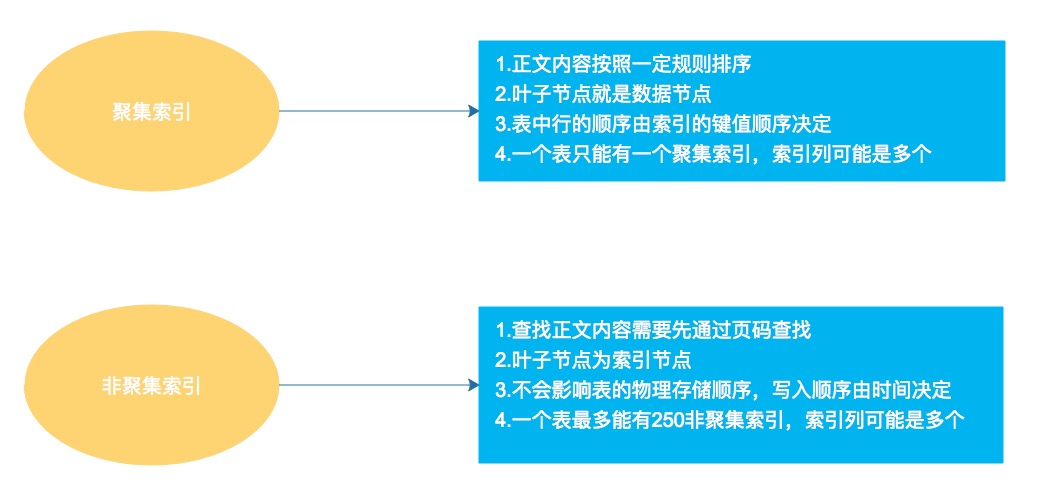
比如要查找'hello',则直接找内容为hello的行,我们把这种正文内容本身就是一种按照一定规则排列的目录称为“聚集索引”。
聚集索引的叶子节点就是数据节点,key为主键的值,value为其余列数据以及rowid、rollback pointer、trx id等信息。
聚集索引的条件:
a.首先选择显示定义的主键为聚集索引;
b.如果没有则选择第一个非NULL的唯一索引;
c.以上都不满足就选择ROWID。
聚集索引表现:
a.索引的键值顺序决定了表中相应行的物理顺序,即表中行的存储顺序由聚集索引的键值顺序决定;
b.一个表只能有一个聚集索引;
c.索引列可能是多个(复合索引)。
2. 适用场景(只针对innodb存储引擎,myisam不存在这说法)
a.主键列,该列在where子句中使用并且插入是随机的。
b.按范围存取的列,如pri_order > 100 and pri_order < 200。
c.在group by或order by中使用的列。
d.不经常修改的列,不能建立在自增列上。
e.在连接操作中使用的列。
二、非聚集索引
1.比如要寻找一个繁体字,得先找到它对应的前一个和后一个字的页码,通过页码来找到对应内容,把这种通过页码来寻找的方式称为非聚集索引。
非聚集索引的叶子节点为索引节点,但是有一个指针指向数据节点。
非聚集索引就是普通索引,仅仅是对表创建索引不会影响表的物理存储顺序,非聚集索引的写入顺序由时间顺序决定。
2.对更新频繁的表来说,表上的非聚簇索引比聚集索引和根本没有索引需要更多的额外开销。对移到新页的每一行而言,指向该数据的每个非聚簇索引的页级行也必须更新,有时可能还需要索引页的分理。
3.适用场景
a.常用于计算函数如sum/count的列;
b.常用于join/order by/group by的列;
c.查寻出的数据不超过表中数据量的20%。
三、总结
四、索引优化
1、缺省情况下建立的索引是非聚簇索引,但有时它并不是最佳的。在非群集索引下,数据在物理上随机存放在数据页上。合理的索引设计要建立在对各种查询的分析和预测上。一般来说:
a.有大量重复值、且经常有范围查询( > ,< ,> =,< =)和order by、group by发生的列,可考
虑建立聚集索引;
b.经常同时存取多列,且每列都含有重复值可考虑建立组合索引;
c.组合索引要尽量使关键查询形成索引覆盖,其前导列一定是使用最频繁的列。索引虽有助于提高性能但不是索引越多越好,恰好相反过多的索引会导致系统低效。用户在表中每加进一个索引,维护索引集合就要做相应的更新工作。
2、ORDER BY和GROPU BY使用ORDER BY和GROUP BY短语,任何一种索引都有助于SELECT的性能提高。
3、多表操作在被实际执行前,查询优化器会根据连接条件,列出几组可能的连接方案并从中找出系统开销最小的最佳方案。连接条件要充份考虑带有索引的表、行数多的表;内外表的选择可由公式:外层表中的匹配行数*内层表中每一次查找的次数确定,乘积最小为最佳方案。
4、任何对列的操作都将导致表扫描,它包括数据库函数、计算表达式等等,查询时要尽可能将操作移至等号右边。
5、IN、OR子句常会使用工作表,使索引失效。如果不产生大量重复值,可以考虑把子句拆开。拆开的子句中应该包含索引。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号