
爬虫介绍
爬虫介绍
引入
之前授课过程当中,好多同学都问过我同一样的一个问题:
-
为什么要学习爬虫、学习爬虫能够对我们以后未来有什么发展带来那些好处?
- 其实学习爬虫的原因和我们以后发展带来的好处显而易见的,无论是从实际的应用还是从就业。
- 我们都知道,当前我们所处的时代大数据时代、大数据时代,要进行数据分析,首先要有数据,而学习爬虫、可以让我们获取更多的数据,并且这些数据源可以按我们需求进行采集。
- 优酷推出的火星情报局就是基于爬虫的数据分析制作完成的。其中每期节目话题都是从相关热门互动平台中进行相关数据的爬取,然后对爬取的数据进行分析而得来的,另一方面,优酷根据用户实时观看视频的前进,后退行为数据,能够推测计算观众的兴趣爱好点,这样有助于节目的剪辑后期的节目方案编写,
- 今日头条作为一新闻推荐的应用,其内部新闻数据都是通过爬虫程序在各个新闻网站进行数据的爬取,然后通过相应的处理和运算将用户感兴趣的新闻话题推送到用户手机上
- 从就业角度上来说,爬虫工程师目前来说属于紧缺人才,并且薪资待遇普遍较高所以,深层次的掌握这门技术,对于就业来说,是非常有利的,有些人学习爬虫就是为了就业或者跳槽。从这个角度来说,爬虫工程师是不错的选择之一,随着大数据的时代来临,爬虫技术的应用将越来越广泛,在未来会拥有更好的发展空间。
今日概要
- 爬虫简介
- 爬虫分类
- robots协议
- 反扒机制
- 反反扒机制
今日详情
-
什么是爬虫
- 爬虫其实就是通过编写程序模拟浏览器,然后让去互联网上抓取数据过程
-
哪些语言可以实现爬虫
1.php:可以实现爬虫。php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆卖瓜的意思),但是php在实现爬虫中支持多线程和多进程方面做的不好。
2.java:可以实现爬虫。java可以非常好的处理和实现爬虫,是唯一可以与python并驾齐驱且是python的头号劲敌。但是java实现爬虫代码较为臃肿,重构成本较大。
3.c、c++:可以实现爬虫。但是使用这种方式实现爬虫纯粹是是某些人(大佬们)能力的体现,却不是明智和合理的选择。
4.python:可以实现爬虫。python实现和处理爬虫语法简单,代码优美,支持的模块繁多,学习成本低,具有非常强大的框架(scrapy等)且一句难以言表的好!没有但是!
-
爬虫的分类
-
通用爬虫 :通常指搜索引擎的爬虫(https://www.baidu.com)
- 通用爬虫就是通过搜索引擎(百度,谷歌,yahoo)、等抓取重要的内容、主要的目的是将互联网上的网页下载到本地,形成一个 内容备份。简单的来讲是尽可能的;把 互联网上的网页下载下来,存储到本地服务器,形成备份,在对这些网页做相应的处理(提取关键字,去除广告),最后提供 一个用户检索接口。
- 搜索引擎如何抓取互联网上的网站数据?
- 门户网站主动向搜索引擎公司提供其网站链接(url)
- 搜索引擎公司与dns服务商合作,获取网站的url
- 门户网站主动挂靠在一些知名网站的友情链接中
- 缺点
- 通过搜索引擎有一定的局限性 返回的结果 90%的内容都是没用的
- 通过搜索引擎 返回的结果 也会出现大量的 视频 音频 图片 对这些文件 都是无能为力、不能很好的发现获取
- 关键字 信息 不准确 不能真正分析出人类的语义
-
聚焦爬虫 :针对特定网站的爬虫
- 指定对网页的内容进行处理 筛选,尽可能保证 是我们想要的数据。;例如:我就想获取豆瓣上电影名称和影评
-
增量式爬虫
- 概念
- 通过爬虫程序检测网站数据更新,以便可以爬取到该网站近更新出来的数据
- 概念
-
-
robots.txt协议
-
如果我们自己的门户网站指定的页面不想让爬虫程序爬取到的话,那么则可以通过编写一个robots.txt的协议文件来约束爬虫程序的数据爬取。
-
robots.txt协议的编写格式可以观察淘宝网的robots(www.taobao.com)
-
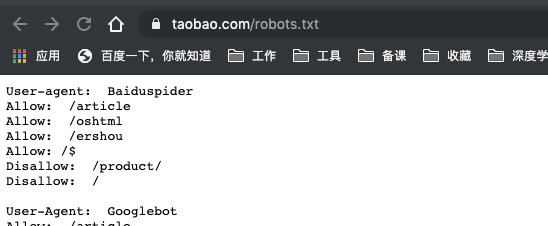
-
注意⚠️该协议只是相当于一个口头协议,防的了君子,不防小人
-
在我们学习爬虫阶段可以先忽略robots协议
-
反爬虫
- 可以是门户网站通过相应的策略和技术手段,防止爬虫程序进行网站数据爬取
-
反反爬虫
- 爬虫程序通过相应的策略和技术手段,破解门户网站的反爬虫手段,从而爬取到相应的数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号