大数据入门第二十五天——elasticsearch入门
一、概述
推荐路神的ES权威指南翻译:https://es.xiaoleilu.com/010_Intro/00_README.html
官网:https://www.elastic.co/cn/products/elasticsearch
精品博文:https://blog.csdn.net/laoyang360/article/details/52244917
1.es是什么
官网的中文介绍:
Elasticsearch 是一个分布式的 RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
权威指南的入门介绍:
Elasticsearch是一个实时分布式搜索和分析引擎。它让你以前所未有的速度处理大数据成为可能。
它用于全文搜索、结构化搜索、分析以及将这三者混合使用
2.特征
查询、分析、速度、可拓展性、弹性、灵活
// 更多详细特征介绍,参考官网
二、安装
安装es需要先安装JDK,这里我们安装es5.6,提请安装一下JDK8
1.下载
https://www.elastic.co/cn/downloads/elasticsearch
选择一个合适的版本,下载即可
2.解压
#es启动时需要使用非root用户!如果非要使用,另行配置,这里暂不展开
[hadoop@mini1 ~]$ tar -zxvf elasticsearch-5.6.9.tar.gz -C /es
// 相应的目录需要有权限
3.修改配置
[hadoop@mini1 config]$ vim elasticsearch.yml
主要需要修改的项如下:
#集群名称,通过组播的方式通信,通过名称判断属于哪个集群
cluster.name: es
#节点名称,要唯一
node.name: es-1
#数据存放位置
path.data: /es/data
#日志存放位置
path.logs: /es/log
#es绑定的ip地址
network.host: 192.168.137.128
#初始化时可进行选举的节点
discovery.zen.ping.unicast.hosts: ["mini1", "mini2", "mini3"]
4.拷贝到其他节点
[hadoop@mini1 es]$ scp -r elasticsearch-5.6.9/ mini2:/es/
[hadoop@mini1 es]$ scp -r elasticsearch-5.6.9/ mini3:/es/
5.修改其他节点配置
需要修改的有node.name和network.host
6.启动
bin/elasticsearch -h查看帮助文档)
bin/elasticsearch -d
启动时会报:Cannot allocate memory,原因是内存不足,ES默认JVM内存为2G
解决方案参考自:https://blog.csdn.net/qq942477618/article/details/53414983
其他也会有一些启动问题,根据日志与博文排查即可:https://blog.csdn.net/feinifi/article/details/73633235?utm_source=itdadao&utm_medium=referral
7.验证
根据以上两篇博文排查完问题后就可以启动了,启动后访问默认的9200端口即可:mini1:9200
{
"name" : "es-1",
"cluster_name" : "es",
"cluster_uuid" : "qO0_NjifRiOnPUnWA-9W-Q",
"version" : {
"number" : "5.6.9",
"build_hash" : "877a590",
"build_date" : "2018-04-12T16:25:14.838Z",
"build_snapshot" : false,
"lucene_version" : "6.6.1"
},
"tagline" : "You Know, for Search"
}
8.停止
可以通过jps查看到其PID,也可以直接使用kill一步到位:
kill `ps -ef | grep Elasticsearch | grep -v grep | awk '{print $2}'`
当然,通过Jps也是可以轻松找出es的pid的:
jps | grep Elasticsearch | awk '{print $1}'
那停止命令也可以长这样:
kill -9 `jps | grep Elasticsearch | awk '{print $1}'`
9.一键启动脚本
如果要编写一个一键启动脚本,那一个简单的示例如下:
#!/bin/bash
SERVERS="192.168.137.128 192.168.137.138 192.168.137.148"
echo "start es..."
for SERVER in $SERVERS
do
ssh $SERVER "source /etc/profile&&/es/elasticsearch-5.6.9/bin/elasticsearch -d"
done
chmod +x以后就可以启动了
10.安装head管理插件
在线安装:
bin/plugin install mobz/elasticsearch-head
离线安装需要先去github下载
./plugin install file:///home/bigdata/elasticsearch-head-master.zip
这里通过查看es-head的github,发现已经不支持5.x了:
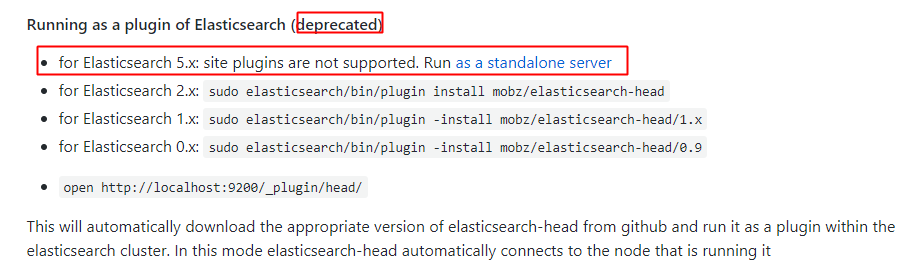
独立server安装方式,参考:https://blog.csdn.net/xgjianstart/article/details/78780176
三、基本概念
和之前的lucene是比较类似的,主要概念如下:
node/cluster:Node是集群的节点,cluster表示集群;
Index:数据管理的顶层单位叫index(索引),概念上类似数据库;
Document:数据库中的记录就叫Document,一条条document组成了一个index;
Type:Document的逻辑虚拟分组,概念上类似表,主要用来过滤Document;
完整参考:http://www.ruanyifeng.com/blog/2017/08/elasticsearch.html
四、基本操作
es提供RESTful形式的操作,基本形式如下:
http://localhost:9200/<index>/<type>/[<id>]
// 其中[]为可选,<>为必选
1.新建与删除index
使用linux的curl来完成,新增index:
[hadoop@mini1 elasticsearch-5.6.9]$ curl -X PUT '192.168.137.128:9200/weather'
删除同样简单,换成DELETE请求即可
[hadoop@mini1 elasticsearch-5.6.9]$ curl -X DELETE '192.168.137.128:9200/weather'
2.安装IK中文分词器
https://github.com/medcl/elasticsearch-analysis-ik
使用在线安装即可(安装博文参考:http://www.ruanyifeng.com/blog/2017/08/elasticsearch.html)
###更多操作,待更新

 浙公网安备 33010602011771号
浙公网安备 33010602011771号