(论文分析) Object Detection-- Discriminatively Trained Part Based Models
Discriminatively Trained Part Based Models 论文及代码分析
代码已经脱离了作者最初的那篇文章(object Detection with discriminatively Trained Part Based Models)所介绍的模型。目前在代码(release 4)中所使用的模型是Grammar Model。我们有必要首先介绍一下什么是Grammar Model(见Object Detection Grammars和Object Detection with Grammar Models)。
Grammar Model最初来自于自然语言理解。给出一句话,我们使用不同的语法规则对语句进行分解,如下图所示:

当然我们要对使用不同的语法规则对语句进行分解进行打分(为什么呢?不同的语法规则体现了一段话的不同语义,只有最合适的语法规则才能体现一句话的真正含义)。
我们怎么将这个来自于NLP的算法模型引入到Object Detection中呢?看看聪明的作者怎么做的吧?
(下面这段话来自于Object Detection with Grammar Models)
让 表示一系列Nonterminal Symbols,
表示一系列Nonterminal Symbols,  表示一系列Terminal Symbols。我们将Terminal 看做是可以在图像中发现的基本构建块。而Nonterminal Symbols被定义成一些虚拟对象,它的出现仅仅是为了表示如何基于Terminal Symbols进行展开。
表示一系列Terminal Symbols。我们将Terminal 看做是可以在图像中发现的基本构建块。而Nonterminal Symbols被定义成一些虚拟对象,它的出现仅仅是为了表示如何基于Terminal Symbols进行展开。
定义 是在一副图像中一个Symbol的所有可能的位置集合。
是在一副图像中一个Symbol的所有可能的位置集合。 为定义在位置
为定义在位置 处的
处的 。这时我们就可以写出语法模型的结构了:
。这时我们就可以写出语法模型的结构了:

其中 。
。
我们可以对一个Nonterminal Symbol进行展开,展开成若干个Terminal Symbol。基于这个模型,我们可以将 的展开构造成一个以
的展开构造成一个以 为根的树
为根的树 。这个树
。这个树 的叶节点是Terminal Symbol,这个树的Interminal 节点是Nonterrminal Symbols。
的叶节点是Terminal Symbol,这个树的Interminal 节点是Nonterrminal Symbols。
这时我们就要问了,由于一个Nonterminal Symbols需要被展开成若干个Terminal Symbols,并且一个Termnial Symbol对应着具体的图像块,这里的展开也就对应着语法规则对语句的解析,那么我们怎么对这种展开打分呢?
我们为每个Symbol(其中包括Nonterminal Symbol 和 Terminal Symbol)附加一个属性"语法规则"。这一属性其实就是一个如何给其对应的展开或对应的图像块打分的计算公式。我们暂且将其称之为rule。
由于整棵树其实就是对一个图像解析,就像是对一句话的语法解析一样。这个图像的解析的分数我们定义成:

其中 就是使用rule对当前Nonterminal Symbol 展开所产生的分数;
就是使用rule对当前Nonterminal Symbol 展开所产生的分数;  就是对当前的Terminal Symbol 所对应的图像块产生的分数。
就是对当前的Terminal Symbol 所对应的图像块产生的分数。
我们可以将这棵树看做是解析一个固定图像内容的模型。得到这个解析树模型就是我们的终极目标。
现在我们可能产生的新问题是如何设计针对于每个Symbol上的rule呢?其实这就是所谓的语法规则。针对不同的Symbol 类型有不同的rule设计。首先来说Terminal Symbol。由于其是针对于具体的图像块的,我们将其定义成一个filter(未知,我们需要学习)与图像块的卷积响应 。针对于Nonterminal Symbol我们又存在两种rule,分别为Structure Scheme和 Deformation Scheme。它们分别又是什么含义呢?对于Structure Scheme,正如其名字所显示,其表示固定的结构(也就是位置固定)。举例来说,一个Noterminal Symbol关联一个Terminal Symbol, 这个关联规则是Structure Shceme(维护着一个固定的anchor量)。这也就是说通过这个规则得到的Nonterminal Symbol展开成Terminal Symbol 的分数,是Terminal Symbol 在位置anchor处所产生的分数。现在说说Deformation Scheme吧!在这里也有一个anchor量,但是Terminal Symbol并不一定在这个anchor位置,而是允许它有一些偏移dx,dy。基于此,我们定义这种展开的分数为在anchor+(dx,dy)位置处的Terminal Symbol的分数加上由于位置偏移带来的惩罚项。
。针对于Nonterminal Symbol我们又存在两种rule,分别为Structure Scheme和 Deformation Scheme。它们分别又是什么含义呢?对于Structure Scheme,正如其名字所显示,其表示固定的结构(也就是位置固定)。举例来说,一个Noterminal Symbol关联一个Terminal Symbol, 这个关联规则是Structure Shceme(维护着一个固定的anchor量)。这也就是说通过这个规则得到的Nonterminal Symbol展开成Terminal Symbol 的分数,是Terminal Symbol 在位置anchor处所产生的分数。现在说说Deformation Scheme吧!在这里也有一个anchor量,但是Terminal Symbol并不一定在这个anchor位置,而是允许它有一些偏移dx,dy。基于此,我们定义这种展开的分数为在anchor+(dx,dy)位置处的Terminal Symbol的分数加上由于位置偏移带来的惩罚项。
至此,文中所使用的Object detection gramma model的基本结构已经出来。就是要建立一个解析树,使其对检测物得到的分数最大,但对其他图像的分数较小。
接下来,我们具体分析一下文中的这种解析树如何建立的(注意考虑镜像,多尺度)。
Structure Schema:
对于每个位置,A Structure Shema 指定了这样一个展开形式:

其中 指定了在feature map pyramid中的常数位置。
指定了在feature map pyramid中的常数位置。
这种Structure Schema 的分数计算方式如下:

Deformation Schema:
定义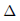 是在一个feature map pyramid中某一尺度下的一系列可能变形偏移的集合。与Structure Schema的差别可以简单理解成,Deformation Schema在计算分数时并不是一个固定位置处,而是在固定位置处有一个偏移的分数再加上一个偏移的惩罚项,通过找到一个最大分数,来作为当前分数。在位置
是在一个feature map pyramid中某一尺度下的一系列可能变形偏移的集合。与Structure Schema的差别可以简单理解成,Deformation Schema在计算分数时并不是一个固定位置处,而是在固定位置处有一个偏移的分数再加上一个偏移的惩罚项,通过找到一个最大分数,来作为当前分数。在位置 和偏移
和偏移 下的展开形式为:
下的展开形式为:

其中 是关于偏移距离的特征向量,
是关于偏移距离的特征向量, 是变形参数(需要学习)。我们使用和
是变形参数(需要学习)。我们使用和 来计算偏移惩罚项。在这种Deformation Schema下的分数计算方式如下:
来计算偏移惩罚项。在这种Deformation Schema下的分数计算方式如下:

对图像块打分规则:
Terminal Symbol直接对应着某个图像块,那么附着在其上的规则应该如何打分呢?引入滤波思想。当然这里的滤波是在这个图像块的特征空间中进行的。具体打分方式如下:

其中 滤波系数,
滤波系数, 是一个在位置
是一个在位置 上的图像块(一个矩形窗口内的图像块)的特征。
上的图像块(一个矩形窗口内的图像块)的特征。
我们利用现在对打分规则的认识,来重述一下给所构建解析树打分的过程(这里仅考虑简单的单尺度情况)。
背景:在图像中检测某一object的位置,我们使用一个矩形检测框box进行指定。
解析树构建:

对这个解析树如何解释呢?Start NonTerminal 是这个解析树的根节点。通过一个Structure Schema rule关联到三个NonTerminal 上,这三个NonTerminal对应三个Fixed anchor。第一个NonTerminal 通过一个Deformation Schema rule 链接一个Root Terminal Symbol(直接与图像关联),由于是由Deformation Schema rule关联的,因而在计算分数时允许存在一个局部的偏移。第二个NonTerminal通过一个Deformation Shcema rule 链接一个Part1 Terminal Symbol(直接与图像关联)。第三个NonTerminal类似。
计算解析树的分数过程形象描述:
首先给Start NonTerminal 一个全局位置 。为了计算Start NonTerminal 的分数
。为了计算Start NonTerminal 的分数 ,我们需要计算
,我们需要计算 ,
, 和
和 。
。
其中 ,
, 和
和 是预先指定的。
是预先指定的。
记住

为了计算,我们需要计算 以及偏移惩罚项
以及偏移惩罚项 。其中,位置
。其中,位置 。大家会问,这里不确定的偏移量
。大家会问,这里不确定的偏移量 怎么办呢?我们选取能够使
怎么办呢?我们选取能够使 达到最大的。
达到最大的。
为了计算,我们需要使用Root Terminal Symbol 所指定的滤波系数 (某一固定长宽的滤波器),以及在
(某一固定长宽的滤波器),以及在 位置处的图像块HOG特征(与滤波器同等长宽)进行点积操作得到的滤波响应值。
位置处的图像块HOG特征(与滤波器同等长宽)进行点积操作得到的滤波响应值。
至此我们进行回推计算,就可以得到 ,这就是这个图像内容解析树模型在位置
,这就是这个图像内容解析树模型在位置 处的分数。
处的分数。
现在有人又要问了,这个root 和 parts模型中anchor怎么指定啊?其实anchor是相对于全局检测位置的一个固定偏移。我们可以采用这种策略,首先我们指定所有 为默认值,然后使用这个模型在图像的所有位置进行打分。这是第一次迭代。然后,挑选出分数最大的一个位置
为默认值,然后使用这个模型在图像的所有位置进行打分。这是第一次迭代。然后,挑选出分数最大的一个位置 。再然后,我们基于这个位置,寻找最佳位置
。再然后,我们基于这个位置,寻找最佳位置 。紧接着,就是最佳偏移位置
。紧接着,就是最佳偏移位置 。
。
现在有人又要问了,这里面还涉及到一些参数呢?如Terminal Symbol中的滤波器参数,它们如何确定呢?这就要涉及学习问题了。在我们得到了,和后,就可以将一些模型参数放入学习框架了(后面详述)。
这里这个模型是相当简单的,为了增加模型效果,文章中增加模型的复杂度。
1. 引入了镜像考虑
在模型中引入镜像节点。
2. 引入多尺度考虑
如何引入多尺度呢?当进行展开时,在高分辨率下进行计算分数。用标准化的式子描述如下:
变量定义: 索引顶层的part,
索引顶层的part, 索引subtype(在这里指的是镜像对象)。
索引subtype(在这里指的是镜像对象)。 指定分辨率索引,
指定分辨率索引, 指定展开part 的索引,它们的取值范围是
指定展开part 的索引,它们的取值范围是 ,其中
,其中 是
是 的subpart的个数。
的subpart的个数。

现在进入代码部分:
上面所涉及的计算模型分数的所有过程均在gdeetect.m文件中实现。
function [dets, boxes, info] = gdetect(pyra, model, thresh, bbox, overlap)
其中pyra是图像的特征金字塔;model是解析树模型;thresh是解析树分数阈值,只有在这一阈值之上的位置,可以作为候选位置;bbox是手工标注的目标位置(原始图像层的坐标系下);overlap,检索框与bbox的重叠度不能低于这个指定的重叠度(overlap)。返回值是什么呢?
dets: 每一个检测位置一行,一共6列。1~4列给出每一个检测bounding box的像素坐标(x1,y1,x2,y2)。5列指定用于检测的model commponent。6列指定每个检测的分数(解析树模型在指定位置的分数)。
bboxes: 每个检测一行。每4列构成一个model filter bounding box的像素坐标。注意,这个序列的索引与model.filters中的索引一致。(每个Terminal Symbol 中包含一个filter,其需要直接操作图像块的特征)
info:关于检测详细信息,包括最佳, 最佳,等信息。
在这个函数中,我们需要首先调用function model = filterresponses(model, pyra, latent, bbox, overlap)
这个函数用来计算所有filters在图像所有有效的特征尺度上每一位置处的响应值。怎么定义有效的图像特征尺度呢?这就需要使用overlap来计算在给定的尺度上的检索框的大小和位置与对应的bbox(手工标注的目标物体位置)之间的重叠度,只有重叠度达到一定阈值我们才能认为这一尺度为有效的尺度。对于所有无效的尺度我们直接对这一层的所有位置的滤波器响应值赋予-inf。
下面详细看看这个函数的实现过程:
|
% gather filters for computing match quality responses i = 1; filters = {}; filter_to_symbol = []; for s = model.symbols if s.type == 'T' filters{i} = model.filters(s.filter).w; filter_to_symbol(i) = s.i; i = i + 1; end end %得到所有滤波器,以及每个滤波器对应的Terminal Symbol |
|
%检测有效层索引 [model, levels] = validatelevels(model, pyra, latent, bbox, overlap);
function [model, levels] = validatelevels(model, pyra, latent, bbox, overlap) % model object model % pyra feature pyramid % latent true => latent positive detection mode % bbox ground truth bbox % overlap overlap threshold
if ~latent levels = 1:length(pyra.feat); else levels = []; for l = model.interval+1:length(pyra.feat) if ~testoverlap(l, model, pyra, bbox, overlap) % no overlap at level l for i = 1:model.numfilters model.symbols(model.filters(i).symbol).score{l} = -inf; model.scoretpt{l} = 0; end else levels = [levels l l-model.interval]; end end end
%我们先不管latent有什么用处(当使用正样本时将其设置成true,当使用负样本时将其设置成false) 我们首先看到初始检测层是model.interval+1,为什么是这一层呢?这一层的尺度为1,也就是原始图像。 最底层图像是原始图像分辨率的二倍。
接下来我们进入函数testoverlap(l, model, pyra, bbox, overlap)
function ok = testoverlap(level, model, pyra, bbox, overlap) % level pyramid level % model object model % pyra feature pyramid % bbox ground truth bbox % overlap overlap threshold
ok = false; scale = model.sbin/pyra.scales(level); for r = 1:length(model.rules{model.start}) detwin = model.rules{model.start}(r).detwindow; o = computeoverlap(bbox, detwin(1), detwin(2), ... size(pyra.feat{level},1), ... size(pyra.feat{level},2), ... scale, pyra); inds = find(o >= overlap); if ~isempty(inds) ok = true; break; end end
在这里我们看到了什么呢?看到了一个奇怪的量 scale = model.sbin/pyra.scales(level); 这个scale什么意思呢?这里我需要指出,我们所建立的金字塔不是图像的金字塔,而是HOG特征金字塔。在建立HOG特征金字塔时,为了消除噪声影响,将基于像素上的方向分布构造成基于cell上的方向分布,一个cell 大小由model.sbin=8进行控制。如果当前的金字塔尺度pyra.scales(level)是1,那么使用这个式子计算出来的scale=8。于是要问了,有什么用呢?我们知道detwin = model.rules{model.start}(r).detwindow;这个量是检测窗口的大小。当我们在特征金字塔不同层上使用这个检测窗口进行检测时,我们需要将对应的这个检测窗口的位置(起始点,长宽)换算到原始图像的坐标系下,因为我们要利用人工标注的目标物体的标注矩形框bbox。我们接下来走入 o = computeoverlap(bbox, fdimy, fdimx, dimy, dimx, scale, pyra)函数看看,进行换算从而得到与标注bbox重叠度的计算的。
function o = computeoverlap(bbox, fdimy, fdimx, dimy, dimx, scale, pyra) % bbox bounding box image coordinates [x1 y1 x2 y2] % fdimy number of rows in filter % fdimx number of cols in filter % dimy number of rows in feature map % dimx number of cols in feature map % scale image scale the feature map was computed at % padx x padding added to feature map % pady y padding added to feature map
padx = pyra.padx; pady = pyra.pady; imsize = pyra.imsize;
%原始图像大小 imarea = imsize(1)*imsize(2);
%手工标注的目标对象区域 bboxarea = (bbox(3)-bbox(1)+1)*(bbox(4)-bbox(2)+1);
% corners for each placement of the filter (in image coordinates) %dimx,dimy是当前检测的特征金字塔层的宽度和高度 %我们需要得到所有位置的重叠度判断,因而使用[1:dimx]方式。乘以scale 表示转换到原始图像的 %坐标系下。 %fdimx, fdimy检测窗口的宽和高。 x1 = ([1:dimx] - padx - 1) * scale + 1; y1 = ([1:dimy] - pady - 1) * scale + 1; x2 = x1 + fdimx*scale - 1; y2 = y1 + fdimy*scale - 1; if bboxarea / imarea < 0.7 % clip detection window to image boundary only if % the bbox is less than 70% of the image area x1 = min(max(x1, 1), imsize(2)); y1 = min(max(y1, 1), imsize(1)); x2 = max(min(x2, imsize(2)), 1); y2 = max(min(y2, imsize(1)), 1); end
% intersection of the filter with the bounding box %得到检测窗口和人工标注窗口的重叠区域 xx1 = max(x1, bbox(1)); yy1 = max(y1, bbox(2)); xx2 = min(x2, bbox(3)); yy2 = min(y2, bbox(4));
% e.g., [x1(:) y1(:)] == every upper-left corner [x1 y1] = meshgrid(x1, y1); [x2 y2] = meshgrid(x2, y2); [xx1 yy1] = meshgrid(xx1, yy1); [xx2 yy2] = meshgrid(xx2, yy2);
% compute width and height of every intersection box %计算重叠区域的宽和高,从而计算所有可能重叠区域的面积inter w = xx2(:)-xx1(:)+1; h = yy2(:)-yy1(:)+1; inter = w.*h;
% a = area of (possibly clipped) detection windows %检测框的面积 a = (x2(:)-x1(:)+1) .* (y2(:)-y1(:)+1);
% b = area of bbox %人工标注的区域面积 b = (bbox(3)-bbox(1)+1) * (bbox(4)-bbox(2)+1);
% intersection over union overlap %重叠率计算公式 o = inter ./ (a+b-inter); % set invalid entries to 0 overlap o(w <= 0) = 0; o(h <= 0) = 0;
一旦在特征金字塔的某一层上存在有效的检测位置(在某个检测位置上,检测框与人工标注区域的重叠率大于指定阈值),那么我们将这一层的序号进行保存到levels变量中(在validatelevels(...)函数中) levels = [levels l l-model.interval];
对于那些无效的特征金子塔层,我们直接定义所有位置对所有滤波器(我们知道滤波器是由Terminal Symbol 进行控制)的分数为 -inf for i = 1:model.numfilters model.symbols(model.filters(i).symbol).score{l} = -inf; model.scoretpt{l} = 0; end
紧接着我们就回到了filterresponses(...)函数中的如下代码块中: for level = levels % compute filter response for all filters at this level r = fconv(pyra.feat{level}, filters, 1, length(filters)); % find max response array size for this level s = [-inf -inf]; for i = 1:length(r) s = max([s; size(r{i})]); end % set filter response as the score for each filter terminal for i = 1:length(r) % normalize response array size so all responses at this % level have the same dimension spady = s(1) - size(r{i},1); spadx = s(2) - size(r{i},2); r{i} = padarray(r{i}, [spady spadx], -inf, 'post'); model.symbols(filter_to_symbol(i)).score{level} = r{i}; end model.scoretpt{level} = zeros(s); end
我们对所有特征金字塔的有效层进行遍历,分别让每一层与所有滤波器进行操作,从而得到这一层在滤波器作用下在所有位置处的响应值,这些值就是控制这个滤波器的Terminal Symbol在每层的每个位置处的分数。 model.symbols(filter_to_symbol(i)).score{level} = r{i}; |
到目前为止,我们已经得到所有Terminal Symbol在所有有效金字塔层上的分数了。利用这些分数我们可以回推,从而得到整个解析树模型在所有有效金字塔层上的每一点处的分数。我们继续往下看吧。
|
% compute parse scores L = model_sort(model); for s = L for r = model.rules{s} model = apply_rule(model, r, pyra.pady, pyra.padx); end model = symbol_score(model, s, latent, pyra, bbox, overlap); end
首先我们需要调用model_sort对模型中的所有Nonterminal Symbol进行排序,排序的结果是从解析树模型的最底层到最高层。从而我们有了一个有效的顺序进行回推计算整个解析树模型的分数。
这两个循环很重要,最外层循环控制着所有NonTerminal Symbol。内层循环,控制着附着在每个Nonterminal Symbol上的规则。我们首先得到每个规则下的得分,然后再搜集起当前的NonTerminal Symbol的所有规则的分数,从而形成这个NonTerminal Symbol的分数。
现在我们进入每个函数进行细看。首先进入 % compute score pyramid for rule r function model = apply_rule(model, r, pady, padx) % model object model % r structural|deformation rule % pady number of rows of feature map padding % padx number of cols of feature map padding
if r.type == 'S' model = apply_structural_rule(model, r, pady, padx); else model = apply_deformation_rule(model, r); end
当然了,作用在NonTerminal Symbol上的规则有两种,一个是Structure rule, 一个是Deformation rule。 我们先看 Deformation rule吧! function model = apply_deformation_rule(model, r) % model object model % r deformation rule
% deformation rule -> apply distance transform def = r.def.w; score = model.symbols(r.rhs(1)).score; for i = 1:length(score) % Note: dt has been changed so that we no longer have to pass in -score{i} [score{i}, Ix{i}, Iy{i}] = dt(score{i}, def(1), def(2), def(3), def(4)); score{i} = score{i} + r.offset.w; end model.rules{r.lhs}(r.i).score = score; model.rules{r.lhs}(r.i).Ix = Ix; model.rules{r.lhs}(r.i).Iy = Iy;
作者默认,一个Deformation rule 只能关联一个Symbol,这一点与作者对Structure rule的设计不同。但是我认为可以将Structure rule设计成同样的风格,更易于进行理解,其实内部实现的方式是一样的。可以自己理解,为什么我这么说。 %得到这个变形规则的变形参数(论文中的 def = r.def.w;
遍历特征金字塔所有层,在每个位置处检索一个最佳偏移,然后得到更新后的分数(记住需要靠偏移惩罚项啊) [score{i}, Ix{i}, Iy{i}] = dt(score{i}, def(1), def(2), def(3), def(4)); score{i} = score{i} + r.offset.w;
r.offset.w是什么呢?偏移权重,它需要被学习。
接下来,我们将计算得到的规则分数保存 model.rules{r.lhs}(r.i).score = score; model.rules{r.lhs}(r.i).Ix = Ix; model.rules{r.lhs}(r.i).Iy = Iy;
纠结与细节的朋友就会问r.i是什么?表明规则自身在规则池中的序号。
好了我们现在可以看看apply_structural_rule了!
function model = apply_structural_rule(model, r, pady, padx) % model object model % r structural rule % pady number of rows of feature map padding % padx number of cols of feature map padding
% structural rule -> shift and sum scores from rhs symbols % prepare score for this rule score = model.scoretpt;
特征金子塔的每一层给出分数偏移权重,这一权重需要被学习得到。 for i = 1:length(score) score{i}(:) = r.offset.w; end
% sum scores from rhs (with appropriate shift and down sample) %由于设计思想与Deformation rule不一致,导致一个Structure rule可以关联多个右节点。 %好吧,我们对所有关联的右节点进行遍历 %记住我们的最终目标是要计算这个规则的左节点在特征金字塔的每一层的每个位置处进行展开的分数。 %这个函数只是计算当前这个规则对这个目标的贡献。 %我们对左节点在每一层每一位置展开时,对展开后的右节点计算分数时不一定是在与左节点同等的特征层 %上,在哪个特征层由anchor决定。
for j = 1:length(r.rhs) 得到anchor,注意这个anchor 是预先指定的,每个右节点有不同的位置。 ax = r.anchor{j}(1); ay = r.anchor{j}(2); ds = r.anchor{j}(3); % step size for down sampling
注意ds的取值方式,如果我们想要在与当前的Nonterminal Symbol同等分辨率下(同等特征层)计算展开后的Symbol的分数我们需要设定ds=0,这时step=1。如果我们想要在2倍分辨率下进行展开,则需要设定ds=1,这是step=2。我想说到这里,应该已经知道step的意思了吧。对于Nonterminal Symbol(左节点)的当前分辨率(特征金字塔的某层)下的每个位置,在做展开后(由于在不同的分辨率下展开,论文中使用2倍分辨率下展开)位置不是连续的,有一个间隔step。
step = 2^ds; % amount of (virtual) padding to halucinate
得到新的填充边界 virtpady = (step-1)*pady; virtpadx = (step-1)*padx; % starting points (simulates additional padding at finer scales)
得到展开的开始位置 starty = 1+ay-virtpady; startx = 1+ax-virtpadx;
% starting level 得到检测开始层(这个层序号是指当前的做节点,做展开的那个节点所在层) startlevel = model.interval*ds + 1;
% score table to shift and down sample s = model.symbols(r.rhs(j)).score; for i = startlevel:length(s)
得到展开后的节点的层(i - model.interval*ds就可以得到在若干倍分辨率下的层序号) level = i - model.interval*ds;
% ending points 得到展开的结束位置(使用min只是为了得到有效的结束位置) endy = min(size(s{level},1), starty+step*(size(score{i},1)-1)); endx = min(size(s{level},2), startx+step*(size(score{i},2)-1));
% y sample points 为了对应到左侧节点的位置,我们需要间隔step进行采样 iy = starty:step:endy; oy = sum(iy < 1); iy = iy(iy >= 1); % x sample points ix = startx:step:endx; ox = sum(ix < 1); ix = ix(ix >= 1); % sample scores
我们得到在这些位置处的分数 sp = s{level}(iy, ix); sz = size(sp);
% sum with correct offset stmp = -inf(size(score{i})); stmp(oy+1:oy+sz(1), ox+1:ox+sz(2)) = sp;
累计所有右节点得到的分数 score{i} = score{i} + stmp; end end
赋予当前规则分数 model.rules{r.lhs}(r.i).score = score;
现在我们得到了与每个Nonterminal Symbol的rule的分数了,那么现在就应该整合分数从而得到这个Nonterminal Symbol的分数(在特征金子塔每一层每一位置)。我们进入函数 function model = symbol_score(model, s, latent, pyra, bbox, overlap) % model object model % s grammar symbol
if latent && s == model.start % mark detection window locations that do not yield % sufficient overlap with score = -inf for i = 1:length(model.rules{model.start}) detwin = model.rules{model.start}(i).detwindow; for level = model.interval+1:length(model.rules{model.start}(i).score) scoresz = size(model.rules{model.start}(i).score{level}); scale = model.sbin/pyra.scales(level); o = computeoverlap(bbox, detwin(1), detwin(2), ... scoresz(1), scoresz(2), ... scale, pyra); inds = find(o < overlap); model.rules{model.start}(i).score{level}(inds) = -inf; end end end
% take pointwise max over scores for each rule with s as the lhs rules = model.rules{s}; score = rules(1).score;
for r = rules(2:end) for i = 1:length(r.score) score{i} = max(score{i}, r.score{i}); end end model.symbols(s).score = score;
其实就是在每一层的每一位置处在不同规则下的最大响应值,从而就得到了这个Nonterminal 在每一层每一位置上的响应分数。 |
 )
)
现在我们就回到了gdetect函数了。继续往下运行
|
% find scores above threshold X = zeros(0, 'int32'); Y = zeros(0, 'int32'); I = zeros(0, 'int32'); L = zeros(0, 'int32'); S = []; for level = model.interval+1:length(pyra.scales) score = model.symbols(model.start).score{level}; tmpI = find(score > thresh); [tmpY, tmpX] = ind2sub(size(score), tmpI); X = [X; tmpX]; Y = [Y; tmpY]; I = [I; tmpI]; L = [L; level*ones(length(tmpI), 1)]; S = [S; score(tmpI)]; end
[ign, ord] = sort(S, 'descend'); % only return the highest scoring example in latent mode % (the overlap requirement has already been enforced) if latent && ~isempty(ord) ord = ord(1); end X = X(ord); Y = Y(ord); I = I(ord); L = L(ord); S = S(ord);
找到候选全局位置 |

接下来我们将要更新模型中的一些变量如anchor, deformation 。调用函数
|
[dets, boxes, info] = getdetections(model, pyra.padx, pyra.pady, ... pyra.scales, X, Y, L, S);
|
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
下面进入学习部分:
这里,我们只是说明如何建立权重和特征序列,然后将其放入学习算法当中,学习算法如何实现的稍后详述。
我们直接进入函数
function [boxes, count] = gdetectwrite(pyra, model, boxes, info, label, ...
fid, id, maxsize, maxnum)
|
参数描述 % pyra feature pyramid % model object model % boxes detection boxes % info detection info from gdetect.m % label +1 / -1 binary class label % fid cache's file descriptor from fopen() % id id for use in long label (e.g., image number the detection is from) % maxsize max cache size in bytes % maxnum max number of feature vectors to write
count = writefeatures(pyra, model, info, label, fid, id, maxsize);
function count = writefeatures(pyra, model, info, label, fid, id, maxsize) % pyra feature pyramid % model object model % info detection info from gdetect.m % label +1 / -1 binary class label % fid cache's file descriptor from fopen() % id id for use in long label (e.g., image number the detection is from) % maxsize max cache size in bytes
% indexes into info from getdetections.cc DET_USE = 1; % current symbol is used DET_IND = 2; % rule index DET_X = 3; % x coord (filter and deformation) DET_Y = 4; % y coord (filter and deformation) DET_L = 5; % level (filter) DET_DS = 6; % # of 2x scalings relative to the start symbol location DET_PX = 7; % x coord of "probe" (deformation) DET_PY = 8; % y coord of "probe" (deformation) DET_VAL = 9; % score of current symbol DET_SZ = 10; % <count number of constants above>
count = 0; for i = 1:size(info,3) r = info(DET_IND, model.start, i); x = info(DET_X, model.start, i); y = info(DET_Y, model.start, i); l = info(DET_L, model.start, i); ex = []; ex.fid = fid; ex.maxsize = maxsize; ex.header = [label id l x y 0 0]; ex.blocks(model.numblocks).w = [];
for j = 1:model.numsymbols % skip unused symbols if info(DET_USE, j, i) == 0 continue; end
if model.symbols(j).type == 'T' ex = addfilterfeat(model, ex, ... info(DET_X, j, i), ... info(DET_Y, j, i), ... pyra.padx, pyra.pady, ... info(DET_DS, j, i), ... model.symbols(j).filter, ... pyra.feat{info(DET_L, j, i)}); else ruleind = info(DET_IND, j, i); if model.rules{j}(ruleind).type == 'D' bl = model.rules{j}(ruleind).def.blocklabel; dx = info(DET_PX, j, i) - info(DET_X, j, i); dy = info(DET_PY, j, i) - info(DET_Y, j, i); def = [-(dx^2); -dx; -(dy^2); -dy]; if model.rules{j}.def.flip def(2) = -def(2); end if isempty(ex.blocks(bl).w) ex.blocks(bl).w = def; else ex.blocks(bl).w = ex.blocks(bl).w + def; end end bl = model.rules{j}(ruleind).offset.blocklabel; ex.blocks(bl).w = 1; end end status = exwrite(ex); count = count + 1; if ~status break end end
首先按照Symbol的顺序排列,针对于每个Symbol,首先判断它是Terminal Symbol还是Nonterminal Symbol。如果是Terminal Symbol,调用: ex = addfilterfeat(model, ex, ... info(DET_X, j, i), ... info(DET_Y, j, i), ... pyra.padx, pyra.pady, ... info(DET_DS, j, i), ... model.symbols(j).filter, ... pyra.feat{info(DET_L, j, i)});
function ex = addfilterfeat(model, ex, x, y, padx, pady, ds, fi, feat) % model object model % ex example that is being extracted from the feature pyramid % x, y location of filter in feat (with virtual padding) % padx number of cols of padding % pady number of rows of padding % ds number of 2x scalings (0 => root level, 1 => first part level, ...) % fi filter index % feat padded feature map
fsz = model.filters(fi).size; % remove virtual padding fy = y - pady*(2^ds-1); fx = x - padx*(2^ds-1); f = feat(fy:fy+fsz(1)-1, fx:fx+fsz(2)-1, :);
% flipped filter if model.filters(fi).symmetric == 'M' && model.filters(fi).flip f = flipfeat(f); end
% accumulate features bl = model.filters(fi).blocklabel; if isempty(ex.blocks(bl).w) ex.blocks(bl).w = f(:); else ex.blocks(bl).w = ex.blocks(bl).w + f(:); end
我们针对filter 的大小,得到对应的feature,并将其保存到ex.blocks(bl).w中。
如果当前的Symbol是Nonterminal Symbol,那么我们还需要考虑是Structure rule 还是 Deformation rule。如果是Deformation rule,我们需要得到最佳偏移def = [-(dx^2); -dx; -(dy^2); -dy];然后是权重偏移ex.blocks(bl).w = 1; 如果是Structure rule,那么只有ex.blocks(bl).w = 1; 我们依靠blocklabel的顺序将它们写入到文件中。
当有了这些量之后,必然还要有w啊!它们也需要根据bolcklabel的顺序写入文件中。
接下来就可以调用学习算法了。 |
参考文献:
1. Object Detection with discriminatively Trained Part Based Models
2. Object Detection with Grammar Models
3. Cascade Object Detection with Deformable Part Models
4. Object Detection Grammars

 浙公网安备 33010602011771号
浙公网安备 33010602011771号