TiKV 组件介绍
数据存储结构
• RocksDB 与列族(Column Family): TiKV 在每个 Store 实例内部使用两个独立的 RocksDB 引擎实例 一个 raftdb 存储 Raft 日志,一个 kvdb 存储用户数据与 MVCC 信息 。kvdb 内部包含四个列族: raft (Region 元信息,仅占少量空间)、 lock (悲观锁和预写阶段的锁信息)、 write (存储实际写入数 据的元信息:commit_ts 和 start_ts)和 default (存储超过255字节的较大值) 。这种设计利用 LSM 树顺序写特性,将多个 Region 的写入合并以提高吞吐
• 多副本机制: 每个 Region 的多个副本(Peer)分布在不同的 TiKV 节点上,通过 Raft 协议保证强一致性和容错。写入操作只能在 Leader 上进行,并需要写入超过半数副本(默认3副本时需至少2个确认)才算成功 。当某个 TiKV 节点故障时,Raft 算法会自动通过选举产生新 Leader,保证数据不丢失且可用 性不受单点故障影响
• Region 与 Peer: Region 是 TiKV 存储数据的基本单位,每个 Region 对应一个连续的 Key 区间 。在 PD 中记录了每个 Region 的 ID 、范围、当前 Leader 所在 Store 等元信息 。一个 Region 的每个副本称为一个 Peer,所有 Peer 组成该 Region 的 Raft 组。客户端(TiKV Client)通过查询 PD 获取 Region 元信息,从而将请求路由到该 Region 当前的 Leader 节点 。Region 在不同副本之间自动复制,确保数据的高可用性和一致性
一致性协议与容错机制(Raft协议)
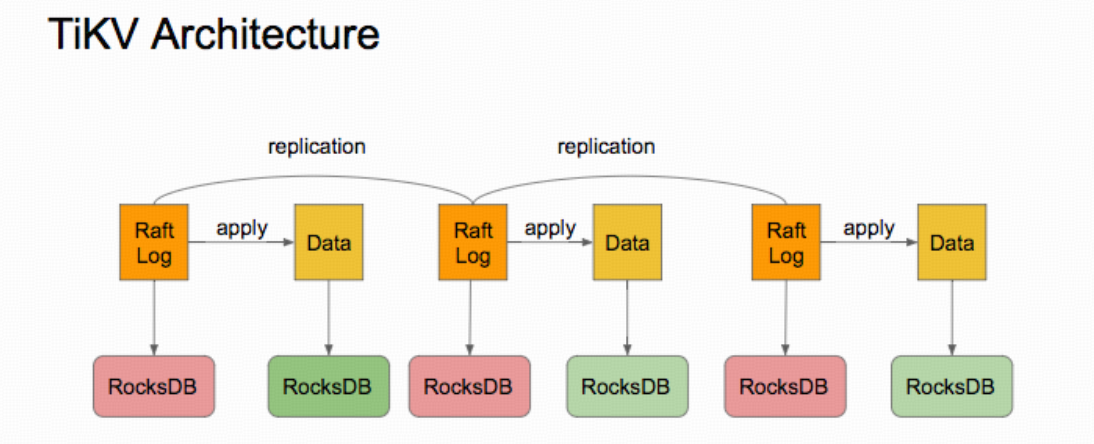
三节点 TiKV 集群中 Raft 日志复制与应用示意图(左侧为 Leader 节点的 Raft 日志,右侧为各副本上的数据; 横向箭头表示AppendEntries 复制,竖向箭头表示日志应用到状态机)。 TiKV 使用 Raft 一致性算法管理 Region 副本之间的数据同步和 Leader 选举 。在每个 Region 的 Raft 组中,Leader 负责接受客户端写请求,将请求封装为新的日志条目并追加到本地日志(raftdb),随后通过 AppendEntries RPC 并行复制到所有 Follower;Follower 收到并持久化日志后会返回确认消息 。一旦 Leader 收到超过半数副本的确认,就提交该日志条目,将之应用到本地状态机(kvdb),并将写成功的结果返回客户端 。该机制保证了在多数 副本存活时数据不丢失。Raft 算法还规定了日志匹配和任期机制:如果某 Follower 日志滞后,Leader 会发送所 缺失的日志进行修复,从而保证所有节点日志前缀一致
当 Leader 节点失效或网络分区时,Raft 算法会通过选举机制恢复可用性:若 Follower 在超时时间内未收到 Leader 心跳,将自身转为Candidate、增加任期号并向其他节点请求投票 。获得多数投票的 Candidate 成为新的 Leader,并继续接管日志复制工作 。这种机制保证了在单节点故障时系统能自动选出新的 Leader。在 此过程中,PD 也会实时感知 TiKV 节点和 Region 的健康状况:TiKV 节点定期向 PD 汇报存储状态和 Region 状态信 息,便于 PD 进行调度和故障恢复
Region 的分裂、合并与调度
TiKV 为保持 Region 大小适中和负载均衡,实现了自动分裂(Split)和合并(Merge)机制。当某 Region 的数据量超过默认阈值(约384 MiB)时,TiKV 会自动将该 Region 按 Key 范围切分成两个或多个更小的 Region;反之,当相邻的两个 Region 因删除等操作而过小时,TiKV会将它们合并成一个 Region 。分裂和合并使得 Region 大小大致均匀(目标约 256MiB),有助于PD做出更合理的调度决策
• PD 调度: PD 基于收集的元数据信息负责自动调度 Region 副本,实现负载均衡和容灾。PD 的基本调度操作包括 添加副本(AddReplica)、删除副本(RemoveReplica)和转移 Leader(TransferLeader) 。例如,若需要将一个 Region 的副本从 TiKV 节点A 迁移到节点 B,PD 会先在节点 B 上增加该 Region 的 Learner 副本(同步数据但不参与投票),待其数据进度追上 Leader后,再将其升级为 Follower,最后移除节点 A 上的旧 Follower 。Leader 迁移类似:待目标节点的 Learner 变为 Follower 后,PD 发起一次转移 Leader 操作(TransferLeader),令新的 Follower 成为 Leader,然后再删除原 Leader 的副本。通过这些操作,PD 可以动态地重新分布 Region 副本和 Leader,以确保所有节点的存储容量和负载趋于均衡
分布式事务实现
TiKV 原生支持分布式事务,主要基于 MVCC 和两阶段提交 (2PC) 实现 Google Percolator 模型的事务处理。具体 要点包括:
• MVCC(多版本并发控制): TiKV 对每行数据保留多个历史版本,以支持快照隔离。每次事务写入时, 新版本不会覆盖旧版本,而是插入带有 start_ts/commit_ts 的记录。写入数据和版本信息存储在 RocksDB 的 write 列族中(主键+commit_ts对应start_ts),而行值(若>255B)存储在 default 列族 。 lock 列族存储加锁信息(如悲观锁或预写阶段的锁)。这样,在读操作时,TiKV 根据事务的 start_ts 在 write 列族中找出该 Key 上 commit_ts ≤ start_ts 的最大版本,然后从相应的列族取出对应的值,实现事务隔离
• 两阶段提交 (2PC): TiKV 的分布式事务采用类似 Google Percolator 的 2PC 算法 。在第一阶段 (prewrite),客户端将事务涉及的所有 Key 和相应的锁信息写入到各 Key 所在 Region 的 TiKV 节点的 default 和 lock 列族中 。其中,事务选择一个 Key 作为主键(primary key)加主锁,其他 Key 加副锁。预写阶段会检查冲突:若目标 Key 已被其他事务锁定或有更新在本事务开始之后提交,则预写失败 (会触发回滚)。当所有 Region 的预写操作成功后,客户端进入第二阶段(commit)。客户端先向主 键所在 Region 的 Leader 节点发送提交请求,获取一个 commit_ts ,并在该 Region 的 TiKV 上向 write 列 族写入提交记录并删除对应的锁 ;待主键提交成功后,客户端并行地向其他 Key 所在 Region 的 Leader 提交,执行相同的写入 commit 记录和删除锁操作 。这些写入操作在 RocksDB 中是原子性的(涉及多个列族的写入要么全成功要么全失败)。若任何阶段失败(如超时或冲突),则会触发锁清理和回滚逻辑,保证原子性。TiKV 最后提交一个事务时才真正将数据写入 write 列族并移除 lock 列 族的锁标记
• 事务隔离与模型: TiKV 提供了快照隔离(SI)级别的事务。每个事务在开始时获取一个全局递增的时间戳 ( start_ts ),只能看到该时间戳之前已提交的写入 。TiDB实现了两种事务模式
• 乐观事务: TiDB Server 端首先在本地缓存所有写操作(不立即写入TiKV),并执行读-写冲突检查;仅在提交阶段进行冲突检测和锁定 。若冲突(已有其他事务提交了冲突版本)则报错并重试,否 则执行2PC提交
• 悲观事务: 在执行 DML 或 SELECT FOR UPDATE 语句时,TiDB 会立即向 TiKV 调用 PessimisticLock 接口,在 lock 列族上对目标Key加悲观锁 。如果锁被其他事务占用,当前操作将被阻塞等待;完 成锁定后,这些锁将在事务提交时在Prewrite阶段转换为正常的 2PC 锁,再按通常 2PC 流程提交 。因 此,悲观事务模式下读写会产生锁等待,但减少了事务提交时的冲突概率
协处理器与 SQL 下推
TiKV 的协处理器(Coprocessor)模块负责执行 TiDB 下推到存储层的计算任务,以减少网络传输和提升查询性能 。当 TiDB 执行 SQL 查询时,解析生成的执行计划会被分解为在 TiKV 上执行的子计划(例如表扫描、过滤、 聚合等)。TiDB 将这些下推算子构成的 DAG 计划以Protobuf格式发送给 TiKV 指定的 Region(gRPC调用),查 询任务标记为 cop[tikv] 。TiKV接收到计划后,在本地存储引擎(Row-Based RocksDB)上按Key范 围扫描数据,并在内存中以列式Chunk格式运行各种算子(如按需过滤、聚合) 。最后,TiKV将部分聚 合结果或过滤后的行批量返回给 TiDB,TiDB 在需要时再做全局聚合或排序。下推计算使得大量数据预先在存储 层过滤和聚合,显著降低了TiDB和TiKV之间的数据传输量
TiKV与TiDB/PD的接口通信
• TiDB ↔ TiKV: TiDB 通过预定义的 gRPC 协议(kvproto)与 TiKV 通信,执行 KV 读写和 Coprocessor 请求。TiDB 执行计划中涉及的每个 KV 操作都会被封装成 RPC 请求(指定 Key 范围、读取模式等),并发送相应 Region 的 TiKV Leader 节点 。TiKV 节点对 RPC 请求进行处理后,将结果返回给 TiDB。下推的 Coprocessor 任务也是通过类似的 RPC 机制传输执行计划和返回数据
• TiKV ↔ PD: TiKV 节点通过定期心跳与 PD 通信。每个 TiKV Store 定期向 PD 发送 StoreHeartbeat (上报 磁盘总量、可用空间、当前 Region 数、读写流量等)和 RegionHeartbeat(上报所属Region范围、副 本分布、数据量、读写统计等) 。PD 收集这些信息进行调度决策:在发现副本不平衡或节点故 障时自动下发调度指令(例如AddReplica/RemoveReplica/TransferLeader)。PD 还将调度结果 以 Raft 命令的形式下发给相关 TiKV 节点,TiKV 根据指令增删副本或转移 Leader。通过这种双向通信,PD 对集群“全局视图”进行管理,实现负载均衡和故障恢复

 浙公网安备 33010602011771号
浙公网安备 33010602011771号