TiDB Server 组件介绍
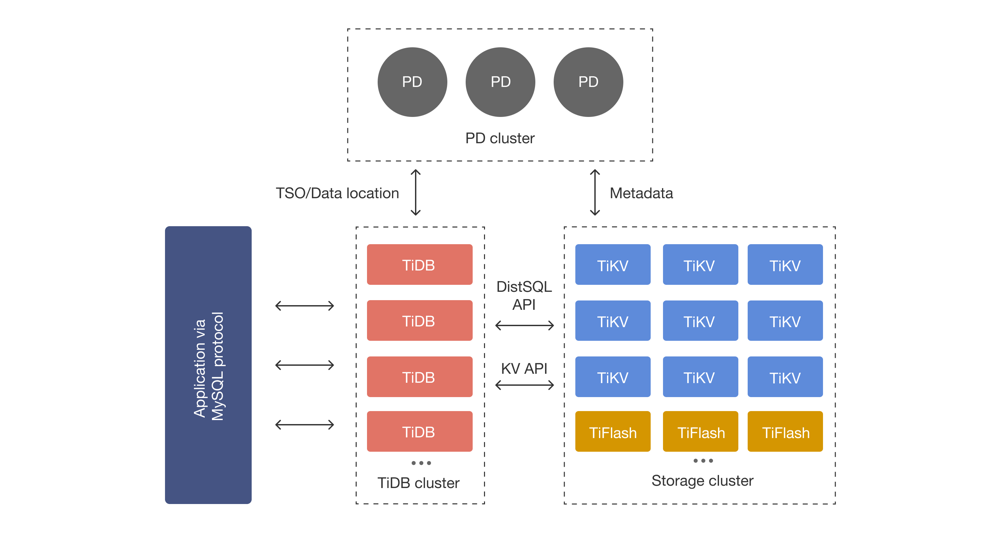
TiDB集群由SQL层(TiDB Server)、存储层(TiKV/TiFlash)和元数据管理层(PD)组成 。TiDB Server作为无状态的SQL计算层,对外提供MySQL协议接口,接受客户端连接并执行SQL处理,但自身不存储 数据 。TiDB Server负责将SQL语句解析、优化并生成分布式执行计划,再通过TiKV/TiFlash存储层完成 实际的数据读写 。整体而言,TiDB Server内部分为多个模块协作:协议层、解析器、编译器/优化器、执行 器、事务管理、计划缓存、统计信息、PD/TiKV客户端等,各模块各司其职、协同工作
模块功能与职责
• 协议层(Connection Manager): 负责 TCP 连接和 MySQL 协议的握手认证,为每个客户端连接创建会话(Session) 。它解析 MySQL 报文,提取 SQL 语句和参数,维护会话状态及会话级变量。如处理 COM_QUERY 、 COM_PREPARE 等命令并将内容交给解析模块。协议层同时负责安全管理(权限校验、TLS 加密等)和资源控制(连接数限制、超时断开等)
• SQL解析器(Parser): 将客户端发送的 SQL 文本进行词法和语法分析,生成抽象语法树(AST) 。解析器首先通过词法分析(lex)将 SQL 拆分为 Token,再通过语法分析(YACC)构造出 AST。这一步检测 SQL 的基本语法合法性(如关键字、标识符合法性)。解析后的 AST 作为后续编译器/ 优化器的输入
• 编译/优化器(Compiler/Optimizer): 接收 AST 后进行语义检查和优化 。首先,优化器根据元数据(系统表)校验对象是否存在、类型是否匹配等合法性;然后进行逻辑优化,例如谓词下推、视图合并、等价转换等 SQL 改写;接着结合统计信息进行物理优化,估算每种访问方式(全表扫描、索引扫描 等)的成本,选择最优索引和连接算法 。优化器最终生成一个逻辑执行计划,再转换为分布式执行计划(物理计划),描述在 TiKV 节点执行的具体算子和流向。优化器是基于成本模型(CBO),其代价估算严格依赖于统计信息的准确性
• 执行计划缓存: TiDB 支持将优化器生成的执行计划缓存起来,以便下次相同或相似查询时跳过编译步骤。对于预处理语句(Prepare/Execute),TiDB 会在 Prepare 时将参数化的 AST 和执行计划存入 LRU 缓 存,下次 Execute 可直接重用计划 。开启后,TiDB 也可对普通 SQL 启用非预处理计划缓存:通过统 一将常量参数化后查询,并在缓存中查找可用计划 。如果命中缓存,执行器直接使用旧计划,否则重新生成并保存。计划缓存限于当前会话(session-level),并对特定类型的查询才生效 。这 样可以显著减少 CPU 开销,提高重复查询的性能
• 统计信息模块: 负责维护表的统计数据供优化器使用。TiDB 通过执行 ANALYZE TABLE 命令收集表的行数、列分布(直方图、TopN等)并存储在TiKV中 。此外,针对 DML 操作,TiDB会自动更新表的总行数和修改行数,并在适当时机触发自动统计(可配置是否开启) 。统计信息被加载到内存 中,供优化器做基数估算。为了节省内存,TiDB内部使用双层缓存:一个 LFU(近似LRU)缓存加载完整统计数据,另一个 resultKeySet 缓存仅保存简要信息(行数、版本等) 。优化器根据这些统计信息对每一步操作(如过滤、连接)的输出行数进行估算,从而计算代价选择最优方案
• 执行器(Executor): 负责执行优化器生成的物理执行计划,并最终返回结果给客户端。执行器分为两种模式:点查询模式(PointGet)和分布式执行(DistSQL) 。如果执行计划仅需要单行数据 (如按照主键或唯一索引查找1行),执行器将采用点查优化路径:直接通过 TiKV Client 向 TiKV 节点发出单个 Get 请求,快速返回结果 。若查询较为复杂(如多表 JOIN、大范围扫描等),执行器会使用分布式执行引擎 DistSQL 模块:将计划拆分成多个 Subplan,向多个 TiKV Region 并行发起 Coproc 请求, 充分利用存储层的并行计算能力 。执行过程中,各算子(如TableScan、 IndexScan、Selection、Join、Aggregate)可利用TiKV 协同处理器下推运算(过滤、部分聚合等), 减少网络传输。最终,各节点返回部分结果后,执行器在TiDB层按照计划合并、排序、聚合等,生成最终输出
• 事务管理模块(Transaction): 负责处理分布式事务的生命周期。TiDB采用类似 Google Percolator 的两阶段提交(2PC)事务模型,并支持乐观和悲观事务模式。执行器在处理包含 DML 的语句时,会将更新操作先缓存至事务模块,事务模块在用户提交时才真正提交数据 。具体流程为:事务开始时,TiDB 通过 PD Client 向 PD 获取全局唯一的时间戳(start_ts) ;事务执行过程中,会对写入键加锁并进行预写(Prewrite);在提交阶段,再次通过PD获取 commit_ts,并进行提交写入(Commit) 及解锁。事务模块还负责锁管理:若发生冲突或需要回滚,可根据锁中记录的主键信息(Primary lock)判断事务状态 。所有读写最终还是通过 TiKV Client 向TiKV节点执行:事务模块协调完 2PC 流程后,调用 TiKV Client 将数据同步到存储层
• PD/TiKV客户端模块: TiDB 内部提供 PD Client 和 TiKV Client 用于与 PD 和 TiKV 交互 。PD Client 负责与 PD 集群通信,获取元数据信息和全局唯一值,如 Region 分布信息、TSO 时间戳、全局 ID 等 。TiKV Client 封装了对 TiKV 的 RPC 调用,包括K/V 读写、Region 路由、Coproc 请求等 。在执行读写请求前,TiKV Client 首先通过 PD Client 查询对应 Key 所在的 Region以及该 Region 的 Leader 位置 (查询结果会缓存在客户端的 Region Cache 中以减少 PD 交互)。然后 TiKV Client 将请求发送给 指定 TiKV 节点的 Leader ,TiKV 节点执行具体的存储或计算操作,并将结果返回 TiDB
• 在线DDL与GC模块: TiDB 支持在线 DDL,在不阻塞服务的情况下变更表结构。Online DDL 模块由三个子模块组成:Start Job、Workers 和 Schema Load 。其中,Start Job 模块接收 DDL 请求并将 DDL 任务写入 TiKV 的全局 DDL 队列;Workers 模块负责轮询并执行队列中的 DDL 任务(每次只有一个 TiDB 实例为 Owner 角色实际执行);Schema Load 模块定期加载最新的数据库/表结构版本,保证所有 TiDB 实例能够及时使用更新的元数据。GC 模块负责多版本并发控制(MVCC)下的过期数据清理:集群中会选举 一个 TiDB 实例作为 GC Leader,其 GC Worker 周期性扫描所有 Region,按照给定的安全点 (SafePoint)清理过期锁和旧版本数据 。这些模块保证了事务与DDL的正常运行以及历史数据的回收
SQL 查询执行流程
TiDB Server 中,各模块紧密协作完成 SQL 的执行,一个典型查询生命周期包括以下步骤 :
- SQL 解析:客户端发送 SQL 请求后,协议层将报文送交解析器,解析器将文本转换为 AST 并进行语义分析
- 生成逻辑计划:优化器根据 AST 进行逻辑优化,生成逻辑执行计划(Logical Plan)
- 生成物理计划:优化器结合统计信息对逻辑计划进行物理优化(代价估算),选取索引、连接算法等, 生成物理执行计划
- 执行计划执行:执行器拿到物理计划后,分两种情形执行
a. 简单点查:若查询通过主键/唯一索引返回单行,执行器直接调用 TiKV Client 做 PointGet,跳过分布式流程
b. 复杂查询:对于多表 JOIN、大范围扫描等复杂场景,执行器进入 DistSQL 模式,将计划分片并发发送到 多个 TiKV Region 。各 TiKV 节点并行执行扫描、过滤、部分聚合等算子, 再将结果返回 TiDB 节点汇总计算(例如对COUNT(*)汇总各节点结果) - 事务提交:若 SQL 涉及事务操作,执行器将更新内容暂存,在用户提交时触发两阶段提交 。事务模块首先通过 PD Client 获取全局启动时间戳(start_ts),进行预写(Prewrite);完成后再获取 commit_ts 并提交(Commit),在 TiKV 层完成数据写入和锁释放
在分布式执行中,TiDB Server 会将查询算子下推到存储层并行计算,从而减少网络开销和加速聚合操作 。整个执行流程从解析到最终结果返回,实现了 TiDB Server 内部模块间的紧密协作
与TiKV/PD的交互
TiDB Server 自身不存储数据,所有数据读取和写入都通过与 TiKV、PD 的交互完成 。主要交互如下:
• TiKV访问: 执行器执行计划时,通过 TiKV Client 模块向 TiKV 发送请求 。在查询前,TiKV Client 通过 PD Client 获取目标 Key所在的 Region 和对应的 Leader 节点 。然后 TiKV Client 将 Key-Value 请求或分布式任务(计算任务以 DAG 方式)发到对应的 TiKV 节点。TiKV 节点执行数据扫描、过滤、聚合等,返回结果给 TiDB 。所有数据交互均使用 TiKV 的 RPC 接口(如 gRPC)完成。为了提高效率,TiKV Client 会缓存 Region 位置信息,避免频繁询问 PD
• PD交互: PD 是 TiDB 的“集群大脑”,提供元数据服务和全局时间戳等功能 。TiDB 通过 PD Client 向 PD 集群获取
• Region元数据: 包括每个 Region 的起始键范围和所在 TiKV 节点,用于路由请求
• 事务TSO: 每次事务启动或提交时,TiDB 向 PD 申请一个全局唯一的 Timestamp(start_ts和 commit_ts)
• 全局ID分配: 如表 ID、索引 ID等全局唯一标识由 PD 管理
• 集群拓扑和调度: PD 存储集群各节点信息、Region 分布,并进行负载均衡决策
TiDB 与 PD/TiKV 的交互保证了数据读写的正确定位和事务一致性。TiDB Server 将 SQL 计划转换为 TiKV API 调用,并依赖 PD 提供的元数据来指导这些调用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号