


【R】【数据处理】如何用R实现数据透视表的操作?(一)
tips:
缺失值需要处理,不然NA+数值=NA
plyr,一行命令=一个数据透视表操作,最后将数据透视表jion起来
使用PDF转表格容易有格式错误,最好手工检查
【数据集】mtcars
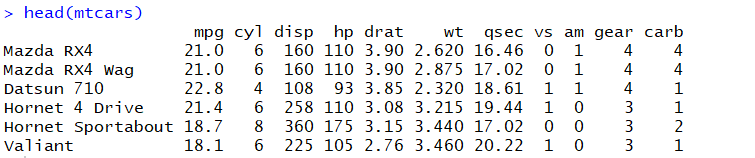
数据来自1974年美国汽车趋势杂志,包括32辆汽车(1973-74款)的油耗和10个方面的汽车设计和性能
A data frame with 32 observations on 11 (numeric) variables.
[, 1] mpg Miles/(US) gallon
[, 2] cyl Number of cylinders
[, 3] disp Displacement (cu.in.)
[, 4] hp Gross horsepower
[, 5] drat Rear axle ratio
[, 6] wt Weight (1000 lbs)
[, 7] qsec 1/4 mile time
[, 8] vs Engine (0 = V-shaped, 1 = straight)
[, 9] am Transmission (0 = automatic, 1 = manual)
[,10] gear Numbemyr of forward gears
[,11] carb Number of carburetors
【管道符】
%>%管道命令,可以将处理好的表格直接进行下一个处理
##分组求和,均值,最小值,最大值 mydata %>% group_by(cyl) %>% summarize(mean_wt= mean(wt), total_wt = sum(wt), median_wt= median(wt), max_wt = max(wt), min_wt = min(wt)) ##分组计数 mydata %>% count(cyl) #新增一个列名为n的字段 mydata %>% count(cyl, name="cnt",sort=T) #分组计数,重命名并降序 mydata %>% group_by(cyl) %>% summarise(cnt=n()) %>% arrange(desc(cnt)) ##去重计数 mydata %>% group_by(cyl) %>% summarise(n=n_distinct(disp)) mydata %>% group_by(cyl) %>% summarise(n=length(unique(disp))) #同上
# 分组查询每个continent的前3
gapminder %>%
group_by(continent) %>%
slice_max(pop, n = 3) %>%
arrange(continent, desc(pop))
# 分组查询每个continent的前3, 使用排序函数 row_number 实现
gapminder %>%
group_by(continent) %>%
mutate(rank_order = row_number(desc(pop))) %>%
filter(rank_order <= 3) %>%
select(-rank_order) %>%
arrange(continent, desc(pop))
【dpylr包】
【filter】--对行筛选,返回所有列
mydata <- mtcars mydata <- mydata %>% filter(cyl == 4) mydata <- mydata %>% filter(cyl < 6) mydata <- mydata %>% filter(cyl < 4 & vs == 0) #两个条件筛选 mydata <- mydata %>% filter(cyl < 6 & !vs == 0) #且,非 mydata <- mydata %>% filter(cyl==6 | !cyl == 8) #或 filter(mydata, cyl == 4) #另一种写法
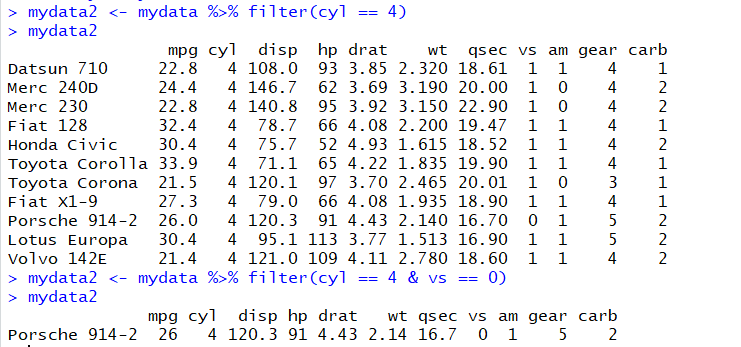
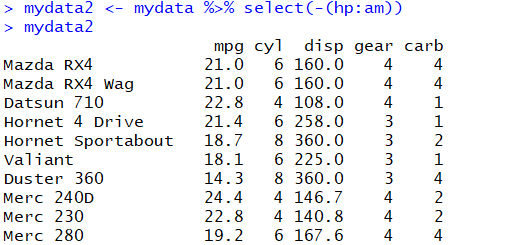
【select】--对列筛选,返回所有符合条件的列
select(mtcars, disp, drat) # 选取disp和drat列
select(mtcars, hp:am) # 选取从hp到am的列
select(mtcars, -(hp:am)) # 删除从hp到am的列
select(mtcars, starts_with('dis')) # 选取以dis开头的变量
select(mtcars, -starts_with('dis')) # 选取开头不为dis的变量
select(mtcars, ends_with('at')) # 选取以at结尾的变量
select(mtcars, -ends_with('at')) # 选取结尾不为at的变量
select(mtcars, contains('s')) # 选取含有s的变量
select(mtcars, -contains('s')) # 选取列名中不含有s的变量
select(mtcars, matches('.s.')) # 选取列名中间含有s的变量
select(mtcars, matches('.s')) # 选取列名中含有s的变量
select(mtcars, matches("(.)\1")) #选择符合正则表达式的变量。这里是任意包含有重复字符的变量
select(mtcars, vs, drat, everything()) # 将变量vs、drat放到前面,更改变量顺序
## 重命名
select(mtcars, Disp = disp) # 将列名disp改为Disp,只返回这一列,少用
rename(mtcars, Disp = disp) # 将列名disp改为Disp,返回所有列
【slice】
##取特定行的数据
mydata %>% slice(10) # 第10行
mydata %>% slice(1000:n()) # 第1000行到最后一行
mydata %>% slice_head(n = 5) # 前5行
mydata %>% slice_tail(n = 5) # 后5行
##查询每组前n个值
# pop 字段最大的3个, 从大到小排序
mydata %>% slice_max(pop, n = 3)
# 按 continent 分组,查询每组 pop 字段最大的3个
gapminder %>%
group_by(continent) %>%
slice_max(pop, n = 3)
# pop 字段最小的3个, 从小到大排序
gapminder %>% slice_min(pop, n = 3)
##抽样
# 按个数抽样
gapminder %>% slice_sample(n = 10)
# 按年份分组抽样, 每年随机抽2个样本
gapminder %>%
group_by(year) %>%
slice_sample(n = 2)
# 按比例抽样
gapminder %>% slice_sample(prop = 0.1)
【mutate】--添加新变量
对已有数据进行计算并添加为新列
mutate(mtcars, disp_1 = disp/100) # 在列尾增加新列disp_1 mutate(mtcars, disp_1 = sqrt(disp), wt_1 = wt*2, a = disp_1*wt_1) # 可以用新列进行计算生成新新列 transmute(mtcars, diap_1 = sqrt(disp)) #只保存新列
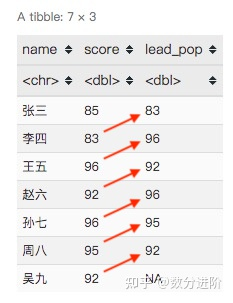
##偏移函数,数据往前或往后错n行,多出来的位置为NA
# 向前偏移, 默认偏移1位,
student_df %>%
mutate(lead_pop = lead(score))
# 向前偏移2位
student_df %>%
mutate(lead_pop = lead(score, n = 2))
# 向后偏移
student_df %>%
mutate(lead_pop = lag(score))
cumsum()累计求和, cumprod()累计内积和, cummin()累计最小值,cummax()累计最大值,summean()累计平均值
【summarize】--数据聚合
对数据框调用函数进行汇总操作
summarise(mtcars, mean(disp)) # 返回disp的均值 summarise(mtcars, mean(disp), max(disp)) # 返回disp均值,最大值 summarise(group_by(mtcars, cyl), mean(disp)) # 返回不同cyl水平下的disp均值 mtcars %>% group_by(cyl) %>% summarise(mean(disp)) # 运用管道符,简化代码,与上面等价
#
【group_by】--分组聚合
一般和其它计算命令一起用
【arrange】--排序
arrange(mydata, cyl, disp) #指定cyl和disp升序排序,默认是升序排序 arrange(mydata, desc(disp)) #降序,NA会被排在最后 arrange(mydata, -disp) #降序,NA会被排在最后 arrange(mydata, hp, desc(disp)) #对hp正序,对disp降序
【rank】--排序
row_number:相同值排序不重复
dense_rank:相同值排序重复,排序连续
min_rank:相同值排序重复,排序不连续
# row_number 排序, 相同值不会重复
mydata %>% mutate(asc_order = row_number(score),
desc_order = row_number(desc(score)))
# dense_rank 排序, 相同值重复且排序连续
mydata %>% mutate(asc_order = dense_rank(score))
# min_rank 排序, 相同值重复且排序不连续
mydata %>% mutate(asc_order = min_rank(score))
【jion】--数据关联
inner_join(x, y, by = "key") #内连接,保留x和y中共同的观测
left_join(x, y, by = "key") #左连接,保留x中所有的观测
right_join(x, y, by = "key") #右连接,保留y中所有的观测
full_join(x, y, by = "key") #全连,保留x和y中所有的观测
semi_join(x, y, by = "key") # 返回能够与y表匹配的x表所有记录
anti_join(x, y, by = "key") # 返回无法与y表匹配的x表的所有记录
# 不指定连接的字段 flights_sub %>% inner_join(airlines_sub) # 指定连接的字段, 且两个数据框的字段名相同 flights_sub %>% inner_join(airlines_sub, by = 'carrier') # 指定连接的字段, 且两个数据框的字段名不同 # 先把 carrier 字段重命名为 carrier_id flights_sub_v2 <- flights_sub %>% rename(carrier_id = carrier) # 通过 flights_sub_v2 的 carrier_id 字段连接 airlines_sub 的 carrier 字段 flights_sub_v2 %>% inner_join(airlines_sub, by = c('carrier_id'= 'carrier'))
【参考】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号