


【项目分析】kaggle入门:泰坦尼克号生存预测分析
【目录】
kaggle介绍
项目练手:泰坦尼克号
收获分享
一、kaggle介绍
kaggle是一个数据科学竞赛平台,创立于2010年,主要为开发商和数据科学家提供举办机器学习竞赛、托管数据库、编写和分享代码的平台。kaggle官方表示,该社区目前在全世界范围内已有超过80万注册用户。
以上是官方介绍,我们换个角度来理解kaggle:
kaggle是为了解决什么问题而被创造出来的?
对企业来说,
在做数据分析的时候,同一个项目往往用多种模型解决,最直接的思路就是研究者一个个去试,直到找到表现最好的模型停止。这样会带来另一个问题:时间成本和人力成本大大增加。
所以研究者往往会在试到性能优于一定阈值的时候,就停下来,选择当前最优模型。
对于数据量小的项目时,不同模型间的复杂度和时间可以忽略不记。
但对于数据量大的项目时,不同复杂度的模型的效率就可以是天差地别了。
而对于瞬息万变的市场来说,时间就是金钱,谁有时间等你模型跑完了再变化。
所以,如果我们团队现在遇到一个问题,我把它放到网上,被很多人看到了:有围观的路人、有想练手的小白、有下凡的大神等,其中有10个人给出了这个问题的解决方法和答案,这样我就可以在最短的时间尝试最多的解决方法,然后用这10个答案中最好的3个进行进一步地优化,大大提升了效率。
这也是为什么有很多企业喜欢在kaggle上发布数据和问题,并提供丰厚的奖金来吸引能人义士。
对个人来说,
每个人都有同样的机会去接触、并尝试解决同一个项目,取最优解。这就创造了一种全新的劳动市场——不以学历和工作经验作为唯一的人才评判标准,而是着眼于个人技能,为顶尖人才和公司之间搭建了一座桥梁。
今天看到的arXiv将 170万篇arXiv论文集成为一个格式机器可读的数据库,并将该数据库托管到了Kaggle上供用户免费使用。数据库包括论文标题、作者、类别、摘要、全文pdf等论文相关信息。kaggle的用户可以直接利用该平台上丰富的数据探索工具,轻松地与他人共享相关论文文本和输出。

二、项目练手
1、问题提出
2、收集数据
3、数据预处理(缺失值处理、归一化、z_score
4、不同变量跟生存情况的关系分析
5、建立模型并预测
1、科学问题
1912年泰坦尼克号邮轮在其处女启航时触礁冰山而沉没,2224名船员和乘客中有1502人遇难。
什么样的人在泰坦尼克号中更容易存活?
2、收集数据
2.1 收集数据
数据下载:https://www.kaggle.com/c/titanic
网站一共提供了三个excel文件:
gender_submission.csv文件中包括passengerID和survived数据,是test数据集的真实标签。
test.csv和train.csv文件中包括:
passengerId:样本编号
survived:存活情况(标签)
Pclass:乘客乘坐舱位情况(1/2/3等)
Name:姓名
sex:性别
age:年龄
SibSp:堂兄弟/妹个数/ 不同代直系亲属人数
Parch:父母与小孩个数/ 同代直系亲属人数
ticket:船票信息
fare:票价
cabin:客舱
embarked:登船港口(出发地点:S=英国南安普顿Southampton;途径地点1:C=法国 瑟堡市Cherbourg;途径地点2:Q=爱尔兰 昆士敦Queenstown)
共11个特征,1个标签,数据量小,可能存在过拟合现象。
2.2 导入并合并数据集
import os os.chdir("C:\\Users\\liuji\\Desktop\\titanic") import numpy as np import pandas as pd #导入数据 train = pd.read_csv("./train.csv") test = pd.read_csv("./test.csv") #数据行列数 print("train",train.shape,"test:",test.shape) #合并数据集,方便同时对两个数据集进行清洗 full = train.append( test , ignore_index = True ) print ('合并后的数据集:',full.shape)
full.head() #查看前5行的数据 full.describe() #查看数据类型的描述统计信息,对字符串类型(如名字)数据不显示 full.info() #查看每一行的数据类型和数据总数
注:没有字符串类型数据
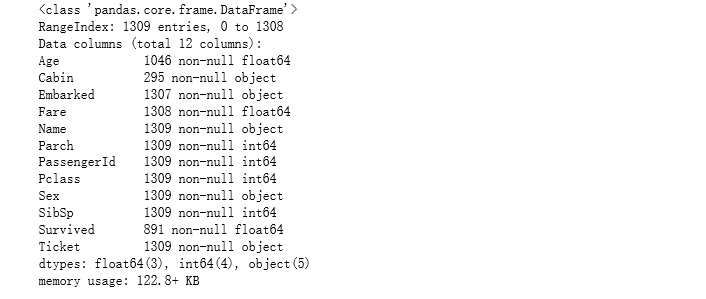
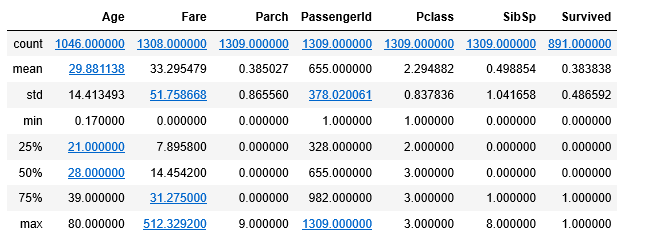
由上述结果可以看出,共有1309行数据:891(train)+481(test)
其中:
数据类型列:
1)年龄(Age)里面数据总数是1046条,缺失了1309-1046=263,缺失率263/1309=20%
2)船票价格(Fare)里面数据总数是1308条,缺失了1条数据
1)登船港口(Embarked)里面数据总数是1307,只缺失了2条数据,缺失比较少
2)船舱号(Cabin)里面数据总数是295,缺失了1309-295=1014,缺失率=1014/1309=77.5%,缺失比较大
接下来的任务就是对缺失数据进行处理。
3、数据预处理
3.1 缺失值处理
- 数值型数据
- 缺失少:用均值填补缺失值:age, fare
- 缺失多:删除、模型预测
- 分类型数据
- 缺失少:用最常见的类别(众数)填补缺失值,embarked
- 缺失多:将缺失值填补为NA,表示缺失,cabin
- 对数值型和分类数据都可以做的处理
- 删除
- 直接删除此特征(缺损数据太多的情况,防止引入噪声)
- 直接删除缺损数据的样本(只用于训练数据集,且样本量较大,缺损数据样本较少的情况)
- 模型预测缺失值,如KNN、随机森林(实现复杂,但准确率会较高,对一些重要的特征可以考虑该方法
- 删除
数据处理可以根据后续的分析反馈进行调整。
age、fare用均值填补缺失值(简单)
import matplotlib.pyplot as plt plt.subplot(2,2,1) full['Age'].hist(bins=10, grid=False, density=True, figsize=(10,6)) #plt.title('AGE before fillna') plt.subplot(222) full['Fare'].hist(bins=10, grid=False, density=True, figsize=(10,6)) #plt.title('Fare before fillna') #年龄(Age) full['Age']=full['Age'].fillna( full['Age'].mean() ) #船票价格(Fare) full['Fare'] = full['Fare'].fillna( full['Fare'].mean() ) plt.subplot(223) full['Age'].hist(bins=10, grid=False, density=True, figsize=(10,6)) #plt.title("AGE after fillna") plt.subplot(224) full['Fare'].hist(bins=10, grid=False, density=True, figsize=(10,6)) #plt.title("Fare after fillna") plt.show()
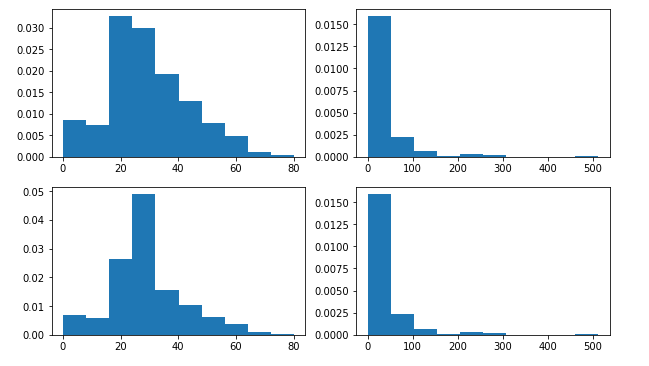
在年龄的缺失值处理过程中,20~30年龄段的数据分布占比较填充前有明显变化,25 ~ 30岁的人数占比增多,其余年龄段的分布与之前基本相同。
在船票的缺失值处理结果比较,其分布与之前基本相同。
embark登船港口用众数填补:
full['Embarked'].value_counts()
output:

从结果来看,S类别最常见。所以我们将缺失值填充为最频繁出现的值
#填补前 plt.subplot(1,2,1) full['Embarked'].hist(bins=10, grid=False, density=True) #填补后 full['Embarked'] = full['Embarked'].fillna( 'S' ) plt.subplot(1,2,2) full['Embarked'].hist(bins=10, grid=False, density=True,color="orange")
填补前后数据分布没有太大的变化
cabin船舱将缺失值分为NA类别
#船舱号(Cabin):查看里面数据长啥样 full['Cabin'].head() full['Cabin'].value_counts()

full['Cabin'] = full['Cabin'].fillna('U') full['Cabin'].head() #检查
full['Cabin'].value_counts()

检查缺失值的处理情况
full.info()

3.2 其它数据处理
异常值处理:z_socre转换
scaling
正则化处理
因为时间因素就不展开了,而且在没有进行进一步的数据处理的情况下,模型效果的score>0.80,算是可以接受的结果。
4、特征提取
4.1 数据分类
将数据分为三类:
1.数值类型:
乘客编号(PassengerId),年龄(Age),船票价格(Fare),同代直系亲属人数(SibSp),不同代直系亲属人数(Parch)
2.时间序列:无
3.分类数据:
1)有直接类别的——用数值代替类别,并进行One-hot编码
乘客性别(Sex):男性male,女性female
登船港口(Embarked):出发地点S=英国南安普顿Southampton,途径地点1:C=法国 瑟堡市Cherbourg,出发地点2:Q=爱尔兰 昆士敦Queenstown
客舱等级(Pclass):1=1等舱,2=2等舱,3=3等舱
2)字符串类型:可能从这里面提取出特征来,也归到分类数据中
乘客姓名(Name)
客舱号(Cabin)
船票编号(Ticket)
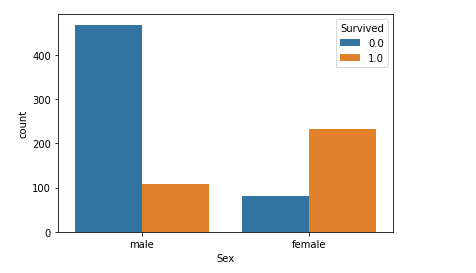
性别
从图中可发现,女性的存活率远高于男性。
将性别映射为数值,male对应数值1,female对应数值0。
import seaborn as sns sns.countplot(x='Sex',hue='Survived',data=full)
sex_mapDict={'male':1, 'female':0} #map函数:对Series每个数据应用自定义的函数计算 full['Sex']=full['Sex'].map(sex_mapDict)
embarked(登船港口
登船港口(Embarked)的值是:
出发地点:S=英国南安普顿Southampton
途径地点1:C=法国 瑟堡市Cherbourg
途径地点2:Q=爱尔兰 昆士敦Queenstown
从图上看,从法国和爱尔兰上船的死亡率比较低,不知为何。
full['Embarked'].head() sns.countplot(x='Embarked',hue='Survived',data=full)
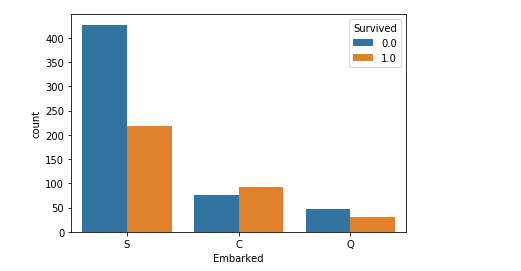
使用get_dummies进行one-hot编码,产生虚拟变量(dummy variables),列名前缀是Embarked
并将变量添加进数据集full
embarkedDf = pd.DataFrame() embarkedDf = pd.get_dummies( full['Embarked'] , prefix='Embarked' ) embarkedDf.head() full = pd.concat([full,embarkedDf],axis=1) full.drop('Embarked',axis=1,inplace=True) full.head()
船舱等级
客舱等级(Pclass):
1=1等舱,2=2等舱,3=3等舱
从图中看出,船舱等级越高,生存率越高
(我也想成为有钱人
sns.countplot(x='Pclass',hue='Survived',data=full)
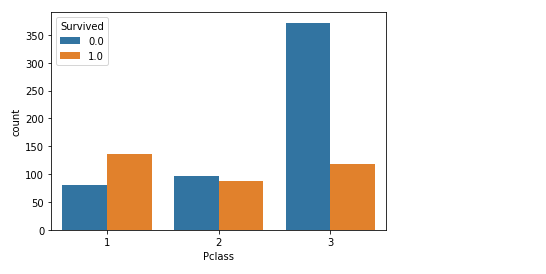
使用get_dummies进行one-hot编码,列名前缀是Pclass,并将其添加进数据集full
pclassDf = pd.DataFrame() pclassDf = pd.get_dummies( full['Pclass'] , prefix='Pclass' ) pclassDf.head() full = pd.concat([full,pclassDf],axis=1) full.drop('Pclass',axis=1,inplace=True) #删除原来的信息
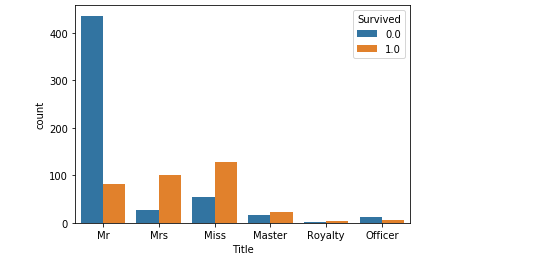
乘客姓名
(一开始我不知道怎么处理,打算直接删除,后来看了大神博客分享,发现
(乘客头衔中每个名字都包含了具体的称谓或是头衔(Mr. Miss. Mrs. 等),可以将这部信息提出出来作为特征
定义以下几种头衔类别:
Officer政府官员
Royalty王室(皇室)
Mr已婚男士
Mrs已婚妇女
Miss年轻未婚女子
Master有技能的人/教师
从称谓和存活率的分布图可以看出,女性的存活率会高于男性,而这个特征可能与sex有共线性。
#获取称谓的函数 def getTitle(name): str1=name.split( ',' )[1] #返回Mr. Owen Harris str2=str1.split( '.' )[0]#返回Mr str3=str2.strip() #strip() 方法用于移除字符串头尾指定的字符(默认为空格),注意这里有空格要去除!不然会影响后续处理! return str3 titleDf = pd.DataFrame() titleDf['Title'] = full['Name'].map(getTitle)#map函数:对Series每个数据应用自定义的函数计算 #姓名中头衔字符串与定义头衔类别的映射关系 title_mapDict = { "Capt": "Officer", "Col": "Officer", "Major": "Officer", "Jonkheer": "Royalty", "Don": "Royalty", "Sir" : "Royalty", "Dr": "Officer", "Rev": "Officer", "the Countess":"Royalty", "Dona": "Royalty", "Mme": "Mrs", "Mlle": "Miss", "Ms": "Mrs", "Mr" : "Mr", "Mrs" : "Mrs", "Miss" : "Miss", "Master" : "Master", "Lady" : "Royalty" } titleDf['Title'] = titleDf['Title'].map(title_mapDict) full = pd.concat([full,titleDf],axis=1) sns.countplot(x='Title',hue='Survived',data=full) full.drop('Title',axis=1,inplace=True) #使用get_dummies进行one-hot编码 titleDf = pd.get_dummies(titleDf['Title']) full = pd.concat([full,titleDf],axis=1) full.drop('Name',axis=1,inplace=True) #删掉姓名这一列
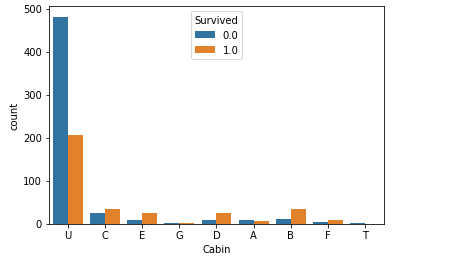
cabin(客舱号
客舱号每个数据的首字母代表不同级别的客舱,如
C85 代表在C等级的客舱
所以需要先将客舱级别整理出来
再进行one-hot编码
好像除了Unknown类别,其它已知的类别客舱存活率都能过半,但数据缺失太多,可靠性低。
full[ 'Cabin' ] = full[ 'Cabin' ].map( lambda c : c[0] ) cabinDf = pd.DataFrame() cabinDf = pd.get_dummies( full['Cabin'] , prefix = 'Cabin' ) full = pd.concat([full,cabinDf],axis=1) sns.countplot(x='Cabin',hue='Survived',data=full) full.drop('Cabin',axis=1,inplace=True)
SibSp和Parch(家族人数
这两个特征的分布规律相似,
可以看出,有兄弟姐妹或父母孩子的比单独旅行的幸存率的确要高,所以以后遇到危险情况,
我上有八十老母,下有三岁小儿嗷嗷待哺,请大慈大悲放我一条生路吧,
这套贯口还是有用的哈哈哈。
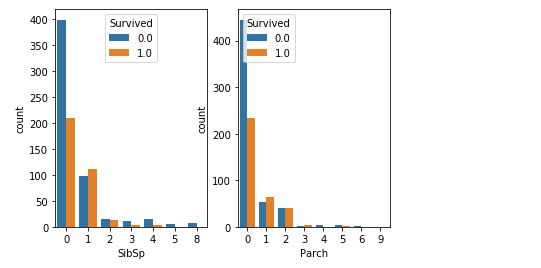
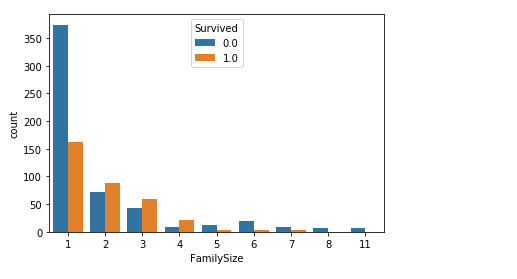
将这两个特征合并整理为 家庭人数,并整理为三类
家庭人数=同代直系亲属数(Parch)+不同代直系亲属数(SibSp)+乘客自己
(因为乘客自己也是家庭成员的一个,所以记得要加1!!!
家庭类别:
小家庭Family_Single:家庭人数=1
中等家庭Family_Small: 2<=家庭人数<=4
大家庭Family_Large: 家庭人数>=5
从图中可以看出,家庭人数在2-4的范围的人,生存率还是较高的,而独自一个人的生存率较低。(这就是生无可恋吗
familyDf = pd.DataFrame() familyDf[ 'FamilySize' ] = full[ 'Parch' ] + full[ 'SibSp' ] + 1 #if 条件为真的时候返回if前面内容,否则返回0 familyDf[ 'Family_Single' ] = familyDf[ 'FamilySize' ].map( lambda s : 1 if s == 1 else 0 ) familyDf[ 'Family_Small' ] = familyDf[ 'FamilySize' ].map( lambda s : 1 if 2 <= s <= 4 else 0 ) familyDf[ 'Family_Large' ] = familyDf[ 'FamilySize' ].map( lambda s : 1 if 5 <= s else 0 ) full = pd.concat([full,familyDf],axis=1) sns.countplot(x='FamilySize', hue="Survived", data=full)
ticket (船票
ticket的类别较多,发现有些人的票号是一样的,可能对应的是朋友、家人一起出行的情况(可能会与家庭人数有一点共线性),所以根据是否与他人票号重复为条件,将ticket的数据分为两组:

def getNum(num): str4 = num.split()[-1] return str4 NumDf = pd.DataFrame() NumDf['Ticket_num'] = full['Ticket'].map(getNum) NumDf.info() NumDf.head() #检查 NumDf['Ticket_repeat'] = NumDf['Ticket_num'].duplicated() #根据是否重复返回True或False num_mapDict={True:1, False:0} NumDf['Ticket_repeat']=NumDf['Ticket_repeat'].map(num_mapDict) NumDf.head() full = pd.concat([full,NumDf],axis=1) full.drop('Ticket',axis=1,inplace=True) sns.countplot(x='Ticket_repeat', hue="Survived", data=full)
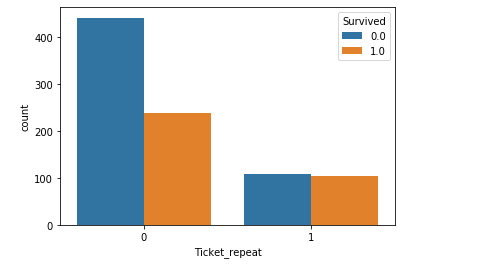
票号有重复的人的生存率较高呀。(好累<(_ _)>
age
将年龄分为三组,old、adult、young
ageDf = pd.DataFrame() ageDf['Age_old'] = full['Age'].map(lambda s: 1 if s>39 else 0) ageDf['Age_adult'] = full['Age'].map(lambda s: 1 if s<=39 and s>=21 else 0) ageDf['Age_young'] = full['Age'].map(lambda s: 1 if s<21 else 0) full = pd.concat([full,ageDf],axis=1) plt.subplot(2,2,1) sns.countplot(x='Age_old', hue="Survived", data=full) plt.subplot(2,2,2) sns.countplot(x='Age_adult', hue="Survived", data=full) plt.subplot(2,2,3) sns.countplot(x='Age_young', hue="Survived", data=full)
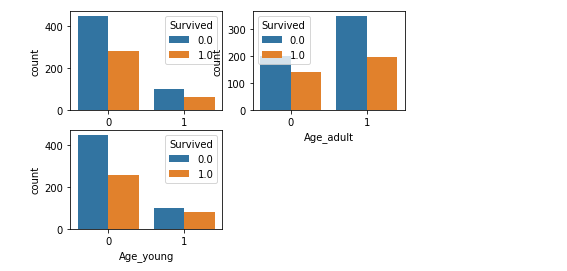
年轻人的牺牲率比较高啊,不容易啊,年轻人~
Fare
将票价分为三组,low、middle、high
fareDf = pd.DataFrame() fareDf['Fare_high'] = full['Fare'].map(lambda s: 1 if s>31 else 0) fareDf['Fare_middle'] = full['Fare'].map(lambda s: 1 if s<=31 and s>=7 else 0) fareDf['Fare_low'] = full['Fare'].map(lambda s: 1 if s<7 else 0) full = pd.concat([full,fareDf],axis=1) plt.subplot(2,2,1) sns.countplot(x='Fare_high', hue="Survived", data=full) plt.subplot(2,2,2) sns.countplot(x='Fare_middle', hue="Survived", data=full) plt.subplot(2,2,3) sns.countplot(x='Fare_low', hue="Survived", data=full)
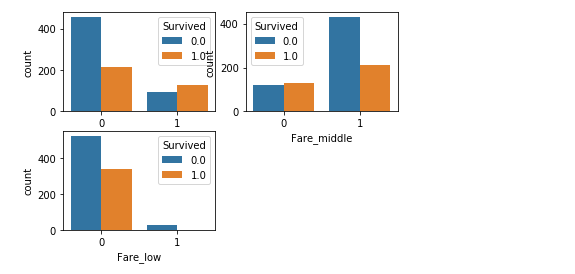
票价高的survived多。
4.2 特征选择
用相关系数法计算各个特征的相关系数
#相关性矩阵 corrDf = full.corr() sns.heatmap(corrDf) corrDf
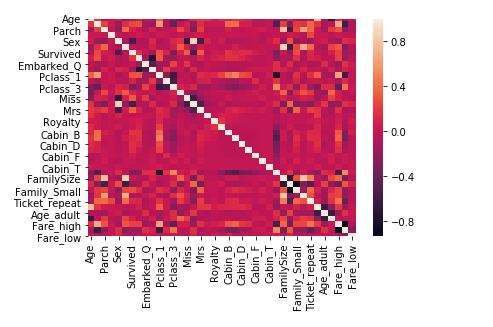
查看各个特征与survived的相关系数,并进行排序
corrDf['Survived'].sort_values(ascending =False)
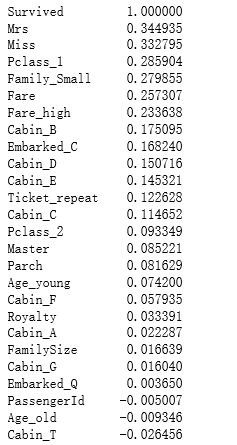
根据各个特征与生成情况(Survived)的相关系数大小,我们选择了这几个特征作为模型的输入:
头衔(前面所在的数据集titleDf)、客舱等级(pclassDf)、家庭大小(familyDf)、船票价格(Fare)、船舱号(cabinDf)、登船港口(embarkedDf)、性别(Sex)
(我也尝试加过full['Age']、full['Ticket_repeat']这两个特征,相当于用上所有给的信息,但score分数却下降了,
#特征选择 full_X = pd.concat( [titleDf,#头衔 pclassDf,#客舱等级 familyDf,#家庭大小 full['Fare'],#船票价格 cabinDf,#船舱号 embarkedDf,#登船港口 full['Sex'] ] , axis=1 ) full_X.head()
5、构建模型
5.1 建立训练数据集和测试数据集
(吃完饭的我又充满能量了!!
从train中拆除20%的数据作为验证集,80%的数据作为测试集,test是用训练好的模型直接预测,作为最终的结果。
sourceRow=891 #train数据集 source_X = full_X.loc[0:sourceRow-1,:] #原始数据集:特征 source_y = full.loc[0:sourceRow-1,'Survived'] #原始数据集:标签 pred_X = full_X.loc[sourceRow:,:] #预测数据集:特征 print('train数据集行数:',source_X.shape[0]) print('test数据集行数:',pred_X.shape[0])
#from sklearn.cross_validation import train_test_split from sklearn.model_selection import train_test_split #建立模型用的训练数据集和测试数据集 train_X, test_X, train_y, test_y = train_test_split(source_X , source_y, train_size=.8) #输出数据集大小 print ('原始数据集特征:',source_X.shape, '训练数据集特征:',train_X.shape , '测试数据集特征:',test_X.shape) print ('原始数据集标签:',source_y.shape, '训练数据集标签:',train_y.shape , '测试数据集标签:',test_y.shape)
原始数据集特征: (891, 27) 训练数据集特征: (712, 27) 测试数据集特征: (179, 27)
原始数据集标签: (891,) 训练数据集标签: (712,) 测试数据集标签: (179,)
5.2 选择机器学习算法
#第1步:导入算法 from sklearn.linear_model import LogisticRegression #第2步:创建模型:逻辑回归(logisic regression) model = LogisticRegression() #随机森林Random Forests Model #from sklearn.ensemble import RandomForestClassifier #model = RandomForestClassifier(n_estimators=100) #支持向量机Support Vector Machines #from sklearn.svm import SVC, LinearSVC #model = SVC() #Gradient Boosting Classifier #from sklearn.ensemble import GradientBoostingClassifier #model = GradientBoostingClassifier()
5.3 训练模型
#第3步:训练模型 model.fit( train_X , train_y )
6、评估模型
# 分类问题,score得到的是模型的正确率 model.score(test_X , test_y )
7、数据预测
对test数据集的数据进行预测
注意,这里生成的预测值是浮点数(0.0,1.0
但Kaggle要求提交的是整数型(0,1
所以记得对数据类型进行转换!!!!
pred_Y = model.predict(pred_X) pred_Y=pred_Y.astype(int) passenger_id = full.loc[sourceRow:,'PassengerId'] #乘客id predDf = pd.DataFrame( #数据框:乘客id,预测生存情况的值 { 'PassengerId': passenger_id , 'Survived': pred_Y } ) predDf.shape predDf.head() predDf.to_csv( 'titanic_pred.csv' , index = False )
三、感受
不足:
训练模型如果用随机森林等其它模型,需要进行调参等一系列分析,还有待学习。
收获:
感受了项目处理的整体流程。
数据预处理是最最重要的,一定要认真做,不然越到后面越难做,还得重新来一遍。
数据信息提取和特征选择很考验对信息的敏感性,像这次从姓名中提取身份信息就很好,还是需要多看项目、多实践。
虽然和我课题没关系,但整体思路还是很相像的。
思考:如果是我来设计数据收集,我还会使用什么指标?
性格:冷静/冲动 研究表明,70%的受伤者是由于海上事故发生时惊慌失措导致的,15%的乘客举止反常,而只有15%的乘客在事发时保持冷静和警觉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号