业务领域建模Domain Modeling
一 领域模型的定义
从领域模型开始,我们就开始了面向对象的分析和设计过程,可以说,领域模型是完成从需求分析到面向对象设计的一座桥梁。
顾名思义,就是显示最重要的业务概念和它们之间关系,是真实世界各个事物的表示(现实世界的可视化抽象字典)而不是软件中各构件的表示。领域模型是描述业务领域(业务实体)的静态结构。
二 领域模型的特点
领域驱动设计告诉我们,在通过软件实现一个业务系统时,建立一个领域模型是非常重要和必要的,因为领域模型具有以下特点:
1. 领域模型是对具有某个边界的领域的一个抽象,反映了领域内用户业务需求的本质;领域模型是有边界的,只反应了我们在领域内所关注的部分;
2. 领域模型只反映业务,和任何技术实现无关;领域模型不仅能反映领域中的一些实体概念,如货物、书本、应聘记录、地址等;还能反映领域中的一些过程概念,如资金转账,等;
3. 领域模型确保了我们的软件的业务逻辑都在一个模型中,都在一个地方;这样对提高软件的可维护性,业务可理解性以及可重用性方面都有很好的帮助;
4. 领域模型能够帮助开发人员相对平滑地将领域知识转化为软件构造;
5. 领域模型贯穿软件分析、设计,以及开发的整个过程;领域专家、设计人员、开发人员通过领域模型进行交流,彼此共享知识与信息;因为大家面向的都是同一个模型,所以可以防止需求走样,可以让软件设计开发人员做出来的软件真正满足需求;
6. 要建立正确的领域模型并不简单,需要领域专家、设计、开发人员积极沟通共同努力,然后才能使大家对领域的认识不断深入,从而不断细化和完善领域模型;
7. 为了让领域模型看的见,我们需要用一些方法来表示它;图是表达领域模型最常用的方式,但不是唯一的表达方式,代码或文字描述也能表达领域模型;
8. 领域模型是整个软件的核心,是软件中最有价值和最具竞争力的部分;设计足够精良且符合业务需求的领域模型能够更快速的响应需求变化。
三 领域建模的重要性
首先,建模的重要性在所有工程实践中都已经得到了广泛的认同。建模是一种抽象和分解的方法,它可以将复杂的问题拆解成一个个抽象,代表了特定的一块密集而内聚的信息。从上世纪80年代开始,人们对于面向对象建模产生了许多思考和方法,其中最流行的就是面向对象分析与设计。面向对象分析,强调的是在问题域发现并描述概念,解决的问题是做正确的事情。面向对象设计,强调的是定义软件对象,解决的问题是正确的做事情。领域模型就是面向对象分析的主要产物,它表达了对现实问题的描述和抽象。大多数人可能可能会有质疑:不做分析和设计,我也可以直接去做代码实现(甚至使用面向过程的编程语言),一样可以完成软件的功能需求,何必花心思去做建模呢?但实际上,这样做会有以下弊端:首先,如果不做设计直接实现,俗称走一步看一步。很大可能在开发过程中发现思维局限,开发进度推倒重来。其次,如果不做分析直接设计,看起来没什么问题。遗憾的是,通过这种方式构造的代码,并没有和现实世界连接起来,当我们的软件和需求稍加修改,这份代码就可能变得异常混乱和难以维护。而通过领域建模的,自上而下的设计,可以保证代码实现的层次结构和模块划分是科学的、稳定的。
四 业务领域建模的方法
1.关注现实世界(问题领域)对象。
2.使用泛化(is-a)和聚合(has-a)关系来显示对象如何相互关联。
3.将您的初始域建模工作限制在几个小时。
4.围绕问题领域的“关键抽象”来组织您的类。
5.不要将您的领域模型误认为数据模型。
6.不要将一个对象(代表单个实例)与数据库表(其中包含事物的集合)混淆。
7.使用领域模型作为项目词汇表。
8.在您编写用例之前,先做一些初始域模型,以避免使用名称歧义。
9.不要指望您的最终类图精确匹配您的领域模型,但他们之间应该有一些相似之处。
10.不要在您的域模型上放置屏幕(screens)和其他GUI特定的类。
工程实践业务建模
我的工程实践内容是“手写中文字体的识别”,下面是以我的工程实践为例来进行业务建模。
一 收集应用领域信息
关注功能要求:拍照文档、 支票、 表单表格、 证件、 邮政信封、 票据、 手稿文书等光学字符识别 (Optical character recognition, OCR) 图像识别系统以及手写文字输入设备中的广泛应用 ,手写汉字识别 (Handwritten Chinese character recognition, HCCR) 一直是模式识别的一个重要研究领域 ,主要方向为脱机 (Offline) 手写体汉字识别 。
二 头脑风暴
列出重要的应用程序域概念:
深度学习:深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。 深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。列出它们之间的关系:
数据集----训练----损失函数----收敛----模型三 对领域概念进行分类
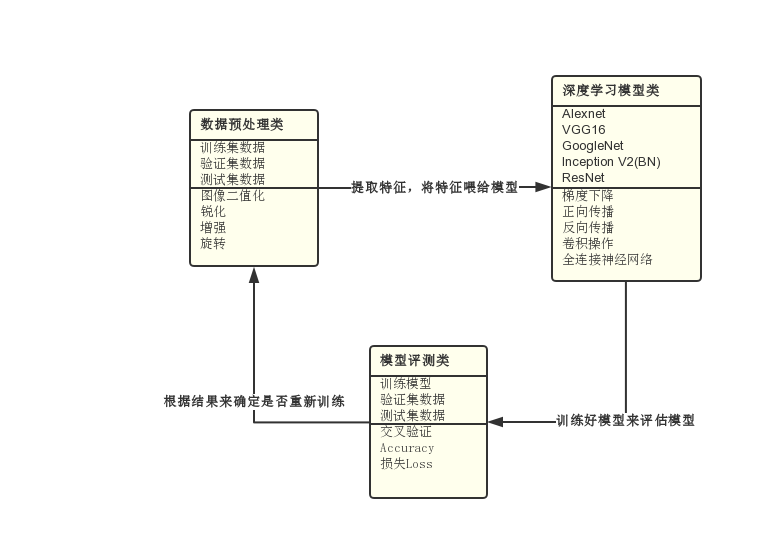
数据预处理类
属性:训练集数据、验证集数据、测试集数据
方法:图像二值化、锐化、增强、旋转
深度学习模型类
属性:Alexnet、VGG16、GoogleNet、Inception V2(BN)、ResNet
方法:梯度下降、正向传播、反向传播、卷积操作、全连接神经网络
模型评测类:
属性:训练模型、验证集数据、测试集数据
方法:交叉验证、Accuracy、损失Loss
四 使用UML类图记录结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号