招商银行 2020FinTech 精英训练营数据赛道(信用风险评分)方案分享(B榜0.78422)
招商银行 2020FinTech 精英训练营数据赛道(信用风险评分)方案分享(B榜0.78422)
写在前面:半个月时间参加了招行今年的FinTech训练营数据赛道,最终成绩B榜0.78422。排名10(极限卡边,运气真好),本文主要分享自己的方案,基本也是数据挖掘中比较常规的思路和操作。建议刚入门数据挖掘类竞赛的小白仔细看一下,如果不想看我啰嗦的可以直接阅读总结部分,欢迎大佬拍砖指正。
一、 赛题任务
主办方提供了两个数据集(训练数据集和评分数据集),包含用户标签数据、过去60天的交易行为数据、过去30天的APP行为数据。希望参赛选手基于训练数据集,通过有效的特征提取,构建信用违约预测模型,并将模型应用在评分数据集上,输出评分数据集中每个用户的违约概率。评分指标为AUC:
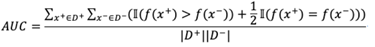
二、 总览

三、 方案介绍
1. 探索性数据分析EDA
此部分主要通过可视化工具和统计方法对数据集进行直观分析,对数据集有整体认识,为后续操作做好基础,主要分析内容:
- 样本数量;
- Label分布;
- 数据字段类型;
- 数据字段分布;
- 数据字段的异常值、缺失值;
- 训练集和测试集的分布差异;
- 字段和label的分布关系;
- 字段相关性分析;
- 有时间特征的可以按不同时间窗口划分观察;
- ……
具体的过程就不赘述了,大家自己看吧,这里说几点做EDA后的重要结论,对后续方案影响比较大:
- 测试集较小,在A榜阶段,模型不应该过多注意线上成绩,否则太容易过拟合B榜成绩可能不好,线下验证非常重要。
- 交易行为数据trd和APP行为数据beh两个表中用户id较少,不能基本覆盖tag中的所有用户,做出的特征缺失值会较多,所以这两个表不一定是必需使用的数据。
- 某些字段存在缺失值的同时有“\N”、“~”等值,和其他的值类型不同,在预处理时填充缺失值需要特殊考虑分析。
2. 数据预处理
预处理部分主要是两个操作:填充缺失值和字段变量转换。
1)缺失值填充:只有tag表中有缺失值,针对tag填充
开始猜想“\N”是缺失值,直接用“\N”填充,后分析发现在多个字段中“\N”数量基本相同(做过的应该知道,那五百多个用户),若全部用“\N”填充,则改变了字段值的比例分布,所以最终填充规则为:
- deg_cd:“~”填充
- edu_deg_cd:“~”填充
- acdm_deg_cd:“\N”填充
- atdd_type:“\N”填充
2)字段变量转换
- 对于类别类字段,如学历、学位、性别、标识等,使用labelencoder编码方式;
- 对于等级代码和连续型字段,如持卡天数、张书、承受风险级别等,将“\N”转化为0或-1(具体选哪个和填缺失值的思路一样,保证转化后那五百多个用户所占比例不变),字段类型转为整型。
3)其他
- 将atdd_type中的0和0.0统一为0,1和1.0统一为1。
- trd表和beh表将时间字段整理,提取出年月日、小时、星期、是否周末等字段,方便后续按时间维度提取用户特征。
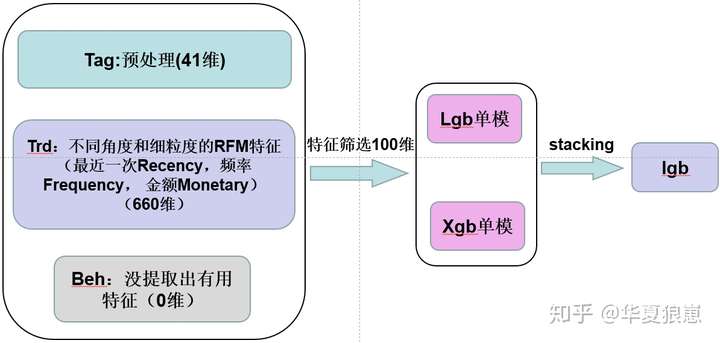
3. 特征工程与特征筛选
在竞赛期间,尝试了很多类型特征,如tag中的类别变量组合特征,连续变量排序特征,trd和beh中提取tfidf和word2vec特征,交易聚集度特征等,最终经过调优和筛选保留下来的主要为通过RFM模型思想构建出的特征。
RFM模型是衡量客户价值和客户创利能力的重要工具和手段,客户主要包含三个重要属性:最近一次消费 (Recency), 消费频率 (Frequency), 消费金额 (Monetary)。(其实基本和常规特征思路一样,只是恰好在这次竞赛期间查到了更专业的说法0.0,所以做比赛要多问谷歌和百度呀)
在本题中,也可以借鉴RFM思想,通过各种维度在不同细粒度等级从trd和beh中提取用户最后一次交易行为或使用APP行为,交易行为和使用APP频率,交易金额,以这些特征更好的对用户进行画像。
经过模型筛选,trd表中提取的最近一次交易R、交易频率F和交易金额M类特征是非常有效的,主要包括:
- 粗粒度刻画:每个id最后一次交易时间、最后一次交易时间是否晚于平均值、交易总次数、多少天有交易行为、交易的总金额、平均每天交易次数、平均每天交易金额、平均每次交易金额;
- 进一步细粒度刻画:按照不同交易方向,不同交易方式,以及不同的一级二级交易分类分别聚合分组,计算每个id的最后一次交易时间、最后一次交易时间是否晚于平均值、交易总次数、平均每天交易次数、总金额数、平均每天金额、平均每次金额;
- 再进一步细粒度:trd中包含5月和6月两个月用户交易行为,单独考虑信贷用户每月的行为还是很重要的,所以分别对每个月做1) 2)中所述特征统计。
这三类特征加tag表中的原始字段一共为701维特征。
在尝试了多种特征筛选方法后,最终使用两种方式进行特征筛选:
1)删除99.9%的值集中在同一个值的特征;
2)树模型选择:使用lightgbm模型训练经过1)删除的特征,通过五折交叉验证筛选出重要性TOP100的特征。
所以最终得到了100维特征。
这里多说一句,赛后看到群里挺多选手在说按线性相关性筛选特征,但没有什么效果,由于大家基本用的都是基于树的模型,其实特征的多重共线性对于树模型的预测能力没有影响的,当一个特征被使用之后,模型再选择和其相似的特征,不会增加新的有效信息或增加很少,所以树模型不需要删除共线性强的特征。(但是得到特征重要性有影响)
除了上述的特征外,其他尝试过的一些特征(这些最后都没用上):
Tag中:
- cate类交叉,num类分桶(等频、等宽、卡方)
- 重要的cate类特征做count和转化率特征(注意不要标签泄露)
- cate类特征计算评分卡模型中的WOE值,num类卡方分箱后计算WOE
Trd中:
- 每个id最大金额、最小金额、金额方差,每个交易方向、交易方式、一级二级代码、分别计最大金额、最小金额、金额方差
- 每个id交易时间间隔,最早最晚时间差
- 进一步细粒度统计每个id的RFM特征,(如时间窗口为15天、10天、7天,按星期几、是否周末统计,按hour分段[0 6 12 18 24]等)
- 聚集度特征:用户的交易行为集中于某一天、两天、三天的比例
- 统计交易稳定性,用两个月分别统计的交易次数、交易金额等相除
Beh中:没做出任何有用的特征,因为id太少,不管怎么做最终都会有很多缺失值,不知道是不是我姿势不对
- 类似于trd中,做R F特征,统计每个id使用APP总次数、总天数、平均每天次数,按page_no和时间窗口再细粒度统计等等
- 根据page_no做count, tfidf:线下降低;
- 每个用户记录按时间排序,根据page_no序列训练word2vec,再平均后作为id特征
4. 模型训练与优化
模型训练采用五折交叉验证的方式,结果比较有参考性。尝试了多种类型的模型,如线性模型、贝叶斯、树模型、神经网络等,综合考虑样本数量和优化结果,最终选择了lightgbm和xgboost两个模型,单模的线下最好成绩分别为:
- Lightgbm: 0.7621267972573647
- Xgboost:0.7602776
这一步操作更多是在A榜期间完成的,实际这并不是A榜线上最好成绩,但考虑到A榜数据量较少,应更多关注线下验证集的提升,否则容易过拟合,最终B榜的成绩也说明了这一点。
5. 模型融合
最终使用stacking融合方式,将lightgbm和xgboost的预测结果作为特征,与tag的原始字段一同输入另一个lightgbm模型,使用十折交叉验证得到最终结果。
最终线下成绩为:0.7651210756398077,线上B榜成绩为0.78422
四、 总结
- 数据量小,并且提交次数有限制,B榜提交次数非常少,为保证在最后的B榜成绩较好,必须更加关注线下验证结果,而不是针对A榜过拟合调参和挑选特征。
- 换B榜后,A榜最高的方案在B榜表现不佳,考虑到A榜最高的方案也并不是线下验证的最好方案,可能会过拟合了,直接替换之前线下有效的方案。(所以要做好版本控制呀,尤其注意线下稳定提升,A榜没提升的策略,比如增加R类特征线下提升,而A榜几乎变化,B榜提升,融合catboost线下降低,A榜提升,但B榜下降。在我的大多数测试方案里,线下和B榜变化趋势更一致些)
- 如上所述,线下验证集的构造非常重要,由于数据量不大,对计算资源要求不高,使用K折交叉验证方式相比hold out的测试结果更为准确。
- App使用行为记录beh表在本方案中没有使用,调优中得到的特征都是负优化,分析原因为beh中记录的用户太少,导致做出特征缺失值太多,对模型训练不利。
- 细致的数据预处理对于结果提升也有帮助(缺失值的处理),尤其本题大家分数比较集中,任何细节的提高都是很重要的。
- 使用特征筛选不仅可以提高训练速度,降低内存空间消耗,更可以去除冗余特征,提高模型预测精度。
- 模型融合选择单模成绩较好、并且有差异性的模型,融合得到的模型才能表现更好。
- 这题数据量比较小,大家成绩都挺接近的,接近的基本在万分位的差距,运气成分肯定有,种子大赛难免0.0,但是一直不太相信自己的脸,没怎么去调参,后来的主要思路放在各种姿势的模型融合和特征工程上了。
写在后面:能力有限,水平不足,欢迎交流,一起学习。
代码见git(注释少,有点乱,大家凑合看。顺便求个star):
https://github.com/wolfkin-hth/FinTech2020github.com
学习路漫漫,狼崽在路上~
Q&A
-
想问大佬,样本不均衡的问题咋处理的呢?过采样还是欠采样更科学呢?
我最终的模型没采样,我简单的试过 过采样和欠采样,包括EasyEnsemble方式,在我的模型里都不如不处理表现好,没有多尝试。其实AUC这个指标和准确率不一样,它受到样本不均衡的影响很小,对正负比例不敏感,具体你可以去深层次了解一下AUC指标。包括我之前参加的一些比赛,只要是AUC做评价指标的,基本都不需要考虑正负样本比例的问题。
-
大佬,还有就是原始数据集里面好多特征里都很多-1,上万都是-1的那种,这种不算异常值吗?可不可以把整列特征都删掉呢?
没必要,通过验证可以看出上万是-1那些特征也是有有效信息的,我只把99.9%的值一样的特征列删掉了。
-
请问大佬,在融合模型里,将第一步的预测结果和tag融合是为什么?为什么只选tag而不是其他更重要特征的?为什么不用全部特征?谢谢解答[大笑]
你说的这几种我都试过,还是结果导向,合理的选择线下验证方式,关注线下验证集表现,选择最好的方案。
-
想请教一下,为什么把训练数据集分成训练集和验证集,训练集auc可达到0.85,验证集auc可以达到0.8,但是到了真实的验证集就只有0.74呢
这次B榜的数据比较友好,大家普遍B榜比线下成绩更高。如果线下表现很好,线上不行,首先考虑特征是否存在泄露(有没有把标签信息泄漏到特征里,做特征是否用到了flag),然后就是如果使用hold out验证方式,看一下验证集划分是否合理,比如验证集大小,标签比例问题,还有是否打乱后划分,hold out也有可能存在正好划分出一部分比较容易预测的数据做验证集的可能,所以线下成绩很好线上不行。建议在计算资源允许的情况下,最好还是用K折交叉验证,这样线下验证结果更有参考价值,可以避免验证集的特殊性。
-
在融合模型里面,将第一步的预测结果放入下一个模型的操作,算不算标签信息泄露?这种情况下如何防止过拟合?
做stacking融合时,注意两点就能很大程序避免信息泄露:一是前一层基模型用K折交叉验证,每一折数据的预测结果都由其他K-1折训练结果得到,再将这些拼接。二是不同的基模型K折交叉验证要使用完全相同的划分方式。这样每一折数据都不含自己标签的信息,很大程度的避免了信息泄露,过拟合程度很小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号