EDA(Exploratory Data Analysis)方法总结
EDA(Exploratory Data Analysis)方法总结
本文是为了记录数据初步分析时候的方法。之前在打比赛的时候不了解这方面的内容,全是靠自己想出来的,不仅费时间、效果也一般。这里总结一下网上提供的方法,本文均来源于网络
姊妹篇:数据预处理方法集合:https://www.cnblogs.com/jiading/articles/12902871.html
EDA在Kaggle比赛中非常重要。基本上EDA就是拿了数据以后画画图看看feature有哪些特别之处,我经常看到Kaggle上面很多长篇大论式的Kernel开头导入数据以后就开始EDA, 这些人是不是时间很多闲得慌喜欢画图扯淡闹着玩呢?不是的,认真的EDA说明他们是严肃的数据玩家。比赛和理想情况不太一样,数据虽然是主办方提供的,但是毕竟还是源自真实,很有可能出现missing vlaues, 或者呈现其他的特点(比如重复的feature, 数据集中在某一区间内,等等等等), 挖掘这些数据的特点,选取合适的feature,甚至创造新的(magic) feature, 比直接上来生搬硬套模型有用得多。其次,数据量大的时候,training花费的时间是很多的,能早早发现数据的特点,有的放矢地train,才是高效之道。
-
查看数据行、列数:
print(x_train.shape) -
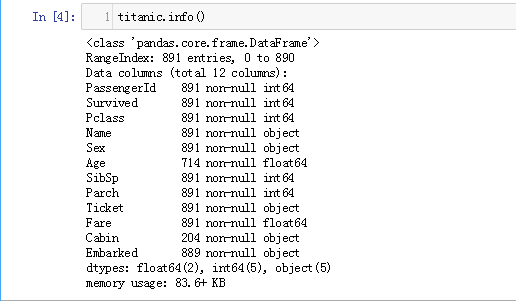
查看数据类型:
x_train.info()![img]()
从这个图中同样能够看出存在缺失值的字段,个数少于891个的特征都是存在缺失的。
-
查看特征的统计量:
![img]()
-
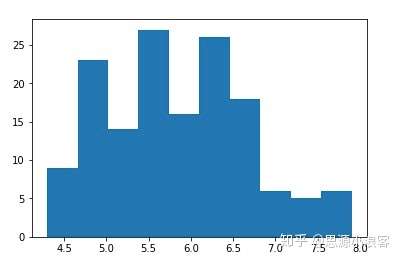
查看单个特征的分布:
plt.hist(df['sepal length (cm)']),使用的是matplotlib的hist函数![img]()
-
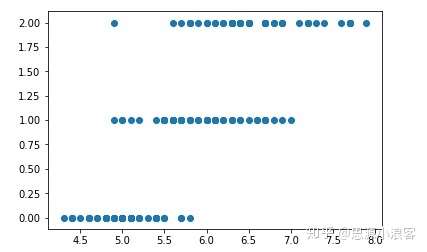
查看单一特征和目标变量之间的关系:
plt.scatter(df.loc[:,'sepal length (cm)'],y),使用的是scatter(散点图)![img]()
-
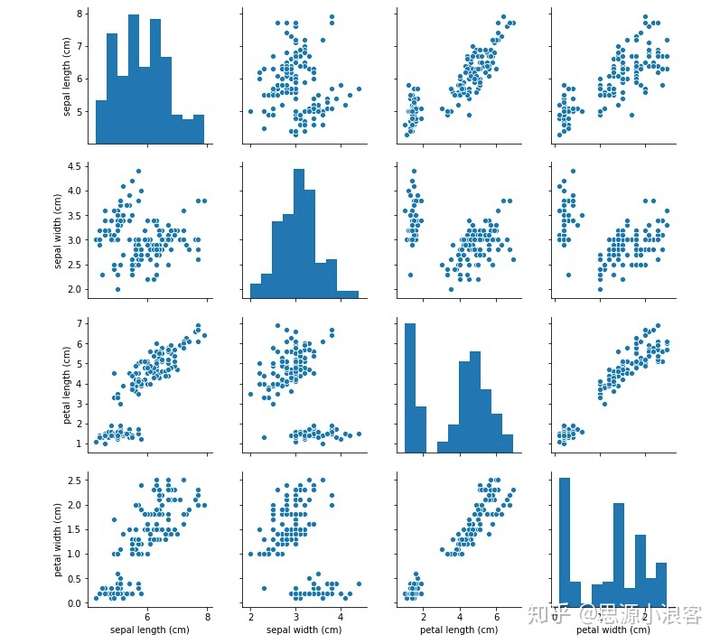
分析特征之间的相关性:使用seaborn的pairplot函数,该函数会针对dataframe中的特征两两绘图,生成一个图片矩阵,反映两个特征的线性相关性。
sns.pairplot(df)![img]()
Seaborn是一种基于matplotlib的图形可视化python libraty。它提供了一种高度交互式界面,便于用户能够做出各种有吸引力的统计图表。
Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn就能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。应该把Seaborn视为matplotlib的补充,而不是替代物。同时它能高度兼容numpy与pandas数据结构以及scipy与statsmodels等统计模式。掌握seaborn能很大程度帮助我们更高效的观察数据与图表,并且更加深入了解它们。
-
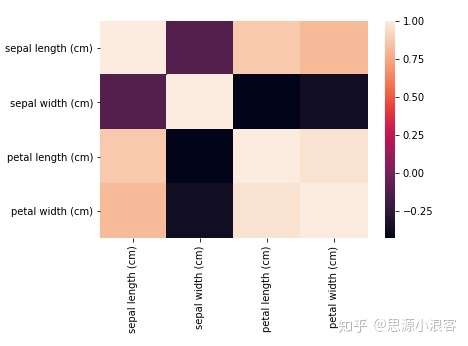
使用热力图来直观反映线性相关程度的强弱
sns.heatmap(df.corr())![img]()
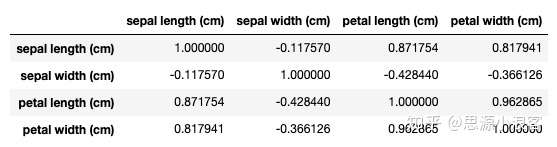
dt.corr()是用来计算皮尔逊相关系数的
![img]()
-
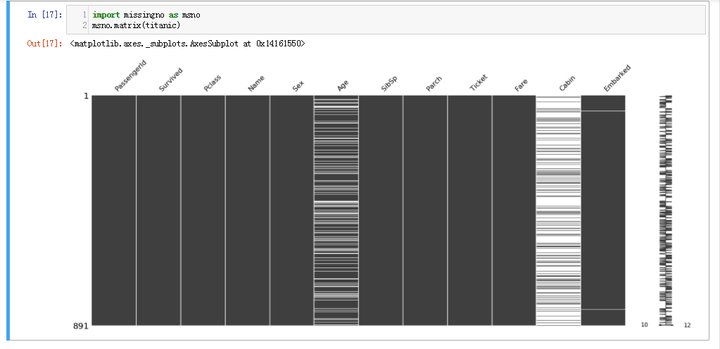
missingno库进行缺失探查:
![img]()
-
缺失数据的进一步分析和处理
见这篇博文:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号