BFS和DFS的Java实现
BFS和DFS的Java实现
BFS
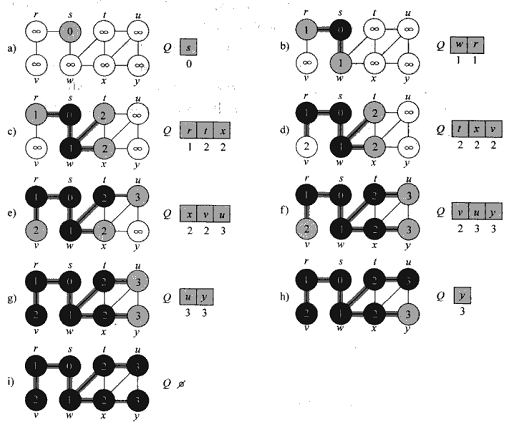
本文将着重介绍遍历图的两种最常用的方法,分别为广度优先遍历和深度优先遍历,后面会具体介绍为什么这么命名。首先来看广度优先遍历 BFS(Breadth First Search),其主要思想是从起始点开始,将其邻近的所有顶点都加到一个队列(FIFO)中去,然后标记下这些顶点离起始顶点的距离为 1. 最后将起始顶点标记为已访问,今后就不会再访问。然后再从队列中取出最先进队的顶点 A,也取出其周边邻近节点,加入队列末尾,将这些顶点的距离相对 A 再加 1,最后离开这个顶点 A。依次下去,直到队列为空为止。从上面描述的过程我们知道每个顶点被访问的次数最多一次(已访问的节点不会再访问),而对于连通图来说,每个顶点都会被访问。加上每个顶点的邻接链表都会被遍历,因此 BFS 的时间复杂度是Θ(V+E),其中 V 是顶点个数,E 是边数,也就是所有邻接表中的元素个数。为了更好的说明这个过程,下图列出了对一个图的 BFS 的过程
[ ](javascript:void(0)😉
](javascript:void(0)😉
private static void bfs(HashMap<Character, LinkedList<Character>> graph,HashMap<Character, Integer> dist,char start)
{
Queue<Character> q=new LinkedList<>();
q.add(start);//将s作为起始顶点加入队列
dist.put(start, 0);
int i=0;
while(!q.isEmpty())
{
char top=q.poll();//取出队首元素
i++;
System.out.println("The "+i+"th element:"+top+" Distance from s is:"+dist.get(top));
int d=dist.get(top)+1;//得出其周边还未被访问的节点的距离
for (Character c : graph.get(top)) {
if(!dist.containsKey(c))//如果dist中还没有该元素说明还没有被访问
{
dist.put(c, d);
q.add(c);
}
}
}
}
[](javascript:void(0)😉
运行结果:

从运行结果我们也可以看到,w r 作为距离为 1 的顶点先被访问,x t v 其后,最后访问 y u。上面的代码使用了一个小的 trick,用 dist 这个 hash 表来记录每个顶点离 s 的距离,如果 dist 中没有这个元素则说明还未被访问,这时将距离写入 dist 中。BFS 访问得到的每个节点与起始顶点的距离是起始顶点到达该顶点的最短距离。从感性认识上来说,BFS 向外扩散的方式得到的距离就是最短距离。详细的证明过程请参考 CLRS 上的相应章节
递归版本:
public static <V> void bfs(List<TreeNode<V>> children, int depth) {
List<TreeNode<V>> thisChildren, allChildren = new ArrayList<>();
for (TreeNode<V> child: children) {
//打印节点值以及深度
System.out.println(child.getValue().toString() + ", " + depth);
thisChildren = child.getChildList();
if (thisChildren != null && thisChildren.size() > 0) {
allChildren.addAll(thisChildren);
}
}
if (allChildren.size() > 0) {
bfs(allChildren, depth + 1);
}
}
DFS
DFS(Depth First Search)深度优先搜索是从起始顶点开始,递归访问其所有邻近节点,比如 A 节点是其第一个邻近节点,而 B 节点又是 A 的一个邻近节点,则 DFS 访问 A 节点后再访问 B 节点,如果 B 节点有未访问的邻近节点的话将继续访问其邻近节点,否则继续访问 A 的未访问邻近节点,当所有从 A 节点出去的路径都访问完之后,继续递归访问除 A 以外未被访问的邻近节点。因为是递归过程,所以我们用过程图看一下也许会更直观一些。

如下是 DFS 的代码及运行结果
[](javascript:void(0)😉
int count=0;
private void dfs(HashMap<Character , LinkedList<Character>> graph,HashMap<Character, Boolean> visited)
{
visit(graph, visited, 'u');//为了和图中的顺序一样,我认为控制了DFS先访问u节点
visit(graph,visited,'w');
}
private void visit(HashMap<Character , LinkedList<Character>> graph,HashMap<Character, Boolean> visited,char start)
{
if(!visited.containsKey(start))
{
count++;
System.out.println("The time into element "+start+":"+count);//记录进入该节点的时间
visited.put(start, true);
for (char c : graph.get(start))
{
if(!visited.containsKey(c))
{
visit(graph,visited,c);//递归访问其邻近节点
}
}
count++;
System.out.println("The time out element "+start+":"+count);//记录离开该节点的时间
}
}
[](javascript:void(0)😉
运行结果:

我们通过一个全局变量 count 记录了进入每个节点和离开每个节点的时间,我们也可以看到进出元素的时间和过程图中的访问过程是一样的。
这是一个递归的DFS算法,非递归算法如下:
非递归算法每次都把一个节点的所有邻接节点压入栈,然后弹出一个再将它的邻接节点压入
//DFS非递归算法---------------->类似于树的中序遍历
void DFSTraverse(Graph G)
{
for(int i = 0;i < G.vexnum ;i++) //将每个顶点标记未访问
{
visited[i] = false;
}
for(int i = 0;i< G.vexnum;i++) //防止出现不相连的图出现
{
if(visited[i]==false)
DFS(G,i);
}
}
void DFS(Graph G,int v) //非递归DFS算法核心部分
{
InitStack(S); //初始化一个栈,借助栈实现
Push(S,v); //将首个顶点压入栈底
while(!IsEmpty(S)) //栈不空,则一直循环
{
Pop(S,v); //将栈顶弹出
visit(v); //visit()函数用来表示访问顶点
visited[v] = true; //标记顶点已经访问
for(w = FirstNeighbor(G,v);w >= 0; w = NextNeighbor(G,v,w)) //
{
if(!visited[w]) //如果该顶点未被访问
{
Push(S,w); //将该顶点压入栈
visit(w); //访问顶点
visited[w] = true; //标记已访问顶点
}
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号