

Redis Cluster
三高架构:高并发,高性能,高可用
Replication(主从复制)
主从复制:将 master 中的数据即时、有效的复制到 slave 中。一个 master 可以拥有多个 slave,一个 slave 只对应一个 master
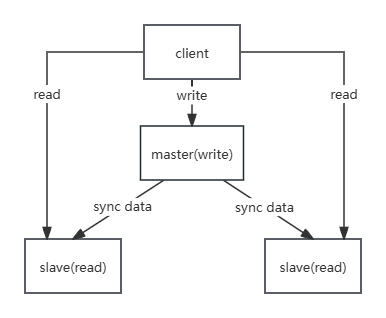
使用 TCP 长连接,默认端口 6379
全量同步:主节点(bgsave) fork 子进程生成 RDB,通过 socket 传输
增量同步:通过复制积压缓冲区(repl_backlog)发送差异数据
心跳检测:REPLCONF ACK 间隔 1 秒(可配置)
命令传播
Sentinel(主从复制+哨兵)
哨兵(分布式系统):对主从结构中的每台服务器进行监控(不断检查 master 和 slave),当出现故障时通过投票机制选择新的 master 并将所有 slave 连接到新的 master
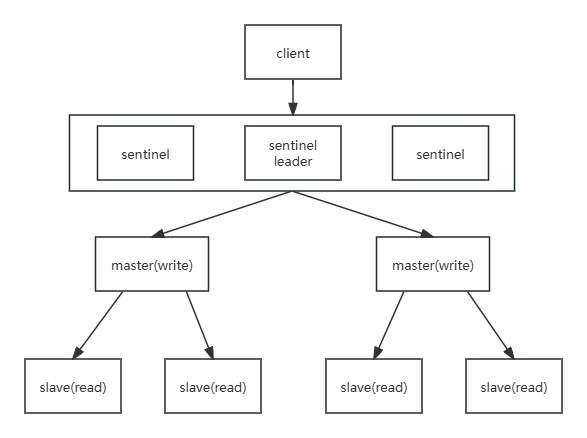
使用专用命令连接,默认端口 26379
发布订阅频道:sentinel:hello
故障判定:通过 SENTINEL is-master-down-by-addr 命令交换状态
使用 epoch 机制保证状态一致性
Scale(多主从复制+分片)
将多个主从连接在一起,实现可扩展性和负载均衡。
Redis 集群通过 key 计算(CRC16 再 %16384,does not use consistent hashing)保存的位置(将所有存储空间分为 16384 个槽位,每个主节点负责其中一些槽位)。
每个节点都知道其它节点槽的范围,当增加节点时,现有的节点会转移一部分槽到新节点,对应槽中的数据也会过去。所以增减节点只是改变槽的位置。
当要查找 key 不在当前节点时,会告诉客户端(重定向)去连接正确的节点查询 key,而不是充当中转的角色。即最多两次就能命中要查找的数据。
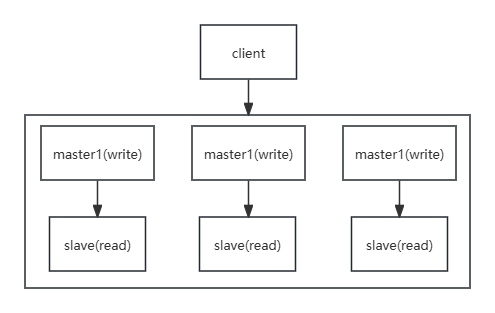
Gossip 协议实现
数据重定向机制
专用集群总线端口,客户端端口+10000,如 6379 + 10000 = 16379
消息头结构(clusterMsg)
使用 CRC16 校验确保数据完整性
故障检测:通过 PING/PONG 超时(默认 15 秒)判断节点下线
解决方案
主要是避免大量请求到业务系统,都可用限流降级处理
缓存预热
系统启动前,提前将相关的缓存数据直接加载到缓存系统。避免用户请求时查数据库再缓存
缓存雪崩
同一时间,大量缓存过期,导致有大量请求查询数据库。过期时间随机化,或使用多级缓存
缓存击穿
某个热点缓存过期时,导致有大量请求查询数据库。查数据库时加锁,或手动维护过期功能(每次查询时比对过期时间)
缓存穿透
频繁查询缓存和数据库都没有的数据,导致有大量请求查询数据库。这时就把空数据也缓存,或使用布隆过滤器
https://redis.io/topics/replication & https://github.com/redis/redis/blob/unstable/src/replication.c
https://redis.io/topics/sentinel & https://github.com/redis/redis/blob/unstable/src/sentinel.c
https://redis.io/topics/cluster-tutorial & https://github.com/redis/redis/blob/unstable/src/cluster.c

 浙公网安备 33010602011771号
浙公网安备 33010602011771号