
Java HashMap
一些数据结构的操作性能
数组:查找快,新增、删除慢
- 采用一段连续的存储单元来存储数据
- 指定下标的查找,时间复杂度为 O(1)
- 通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n)。当然,对于有序数组,可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为 O(logn)
- 对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度为 O(n)
线性链表:新增、删除快,查找慢
- 对于新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为 O(1)
- 查找操作需要遍历链表,逐一进行比对,复杂度为 O(n)
二叉树:自平衡的话,新增、删除、查找都不快不慢
- 对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为 O(logn)
哈希表:添加,删除,查找等操作都很快 (数组+链表)
- 相比上述几种数据结构,在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为 O(1)
数据结构的物理存储结构只有两种:顺序存储结构和链式存储结构(像栈,队列,树,图等是从逻辑结构去抽象的,映射到内存中,也这两种物理组织形式)
HashMap 结构
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(如 memcached)的核心其实就是在内存中维护一张大的哈希表。
HashMap 包括几个重要的成员变量
/** * JDK_1.7.0_80 * AbstractMap 已经实现了 Map 接口,HashMap 可以不用实现 Map 接口 */ public class HashMap<K, V> extends AbstractMap<K, V> implements Map<K, V>, Cloneable, Serializable { // 支持序列化 private static final long serialVersionUID = 362498820763181265L; // HashMap 的主干数组,一个 Entry 类型数组,而 Entry 实际上就是一个单向链表。哈希表的 key-value 键值对都是存储在 Entry 数组中的 // 初始值为空数组 {},主干数组的长度一定是 2 的次幂,方便 indexFor 高效率的位运算得到最终的下标值 transient Entry<K, V>[] table = (Entry<K, V>[]) EMPTY_TABLE; static final Entry<?, ?>[] EMPTY_TABLE = {}; // HashMap 实际存储的 key-value 键值对的数量 transient int size; // HashMap 的存储阈值,当 HashMap 中存储数据的数量达到 threshold 时,就扩容 HashMap 的容量。 // 当 table == {} 时,该值为初始容量(初始容量默认为 16) // 为 table 分配内存空间后,threshold 一般为 capacity(容量) * loadFactory(加载因子) int threshold; // 负载因子,代表了 table 的填充度有多少,默认是 0.75,既兼顾数组利用率,又考虑链表不要太多 final float loadFactor; // 更改次数,用来实现 fail-fast 机制 // 由于 HashMap 非线程安全,在对 HashMap 进行迭代时,如果期间其它线程导致 HashMap 的结构发生变化了(put,remove 等),需要抛出 ConcurrentModificationException transient int modCount; // 默认最小初始化数组的容量 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 // 最大数组的容量 static final int MAXIMUM_CAPACITY = 1 << 30; // 默认加载因子 static final float DEFAULT_LOAD_FACTOR = 0.75f; transient int hashSeed = 0; static final int ALTERNATIVE_HASHING_THRESHOLD_DEFAULT = Integer.MAX_VALUE; private transient Set<Entry<K, V>> entrySet = null;
哈希表的主干就是数组
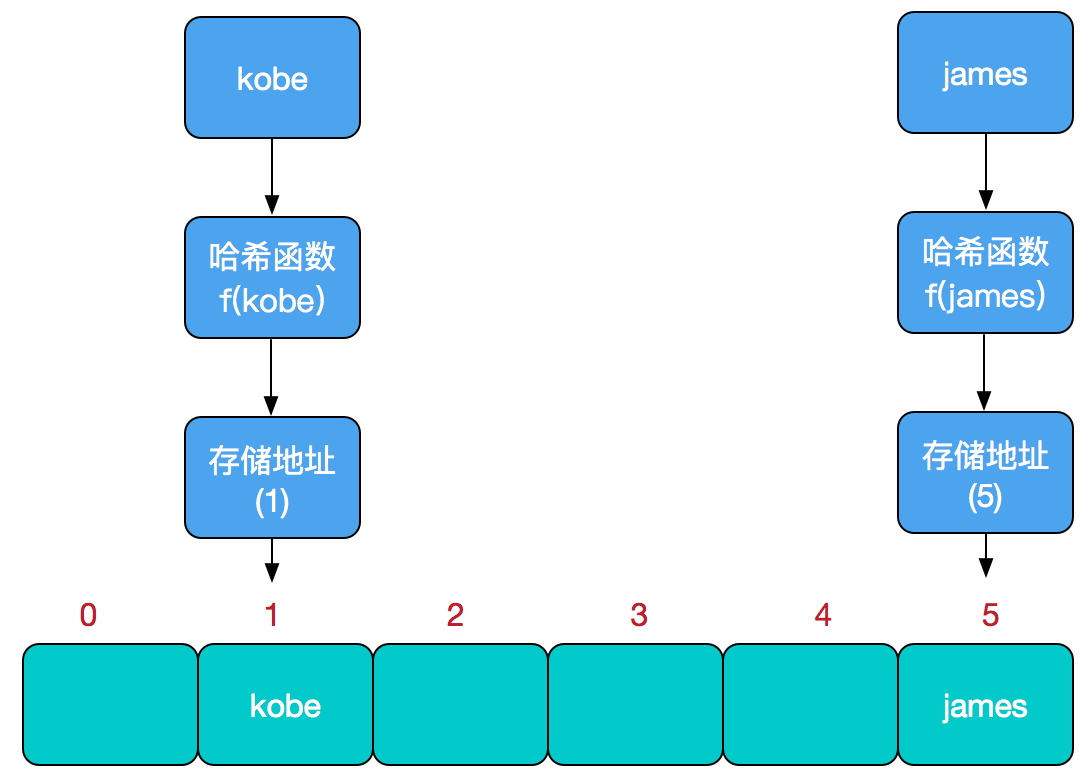
如何找到要插入元素的位置?
- 把当前元素(value)的关键字(key)通过某个函数(hash 算法取模:存储位置 = F(关键字))映射到数组中的某个位置,通过数组下标一次定位就可完成操作。这个函数 F 一般称为哈希函数,这个函数的设计好坏会直接影响到哈希表的优劣。
哈希冲突(哈希碰撞):如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?
- 也就是说,对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,这就哈希冲突,也叫哈希碰撞。
- 哈希函数的设计至关重要,好的哈希函数会尽可能地保证计算简单和散列地址分布均匀,但是,需要清楚的是,数组是一块连续且固定长度的内存空间,再好的哈希函数也不能保证得到的存储地址绝对不发生冲突。
哈希冲突如何解决?
- 哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址)、再散列函数法、链地址法。HashMap 就是采用了链地址法,也就是数组 + 链表的方式。
HashMap 的主干是一个 Entry 数组。Entry 是 HashMap 的基本组成单元,每一个 Entry 包含一个 key-value 键值对。
/** * JDK_1.7.0_80 */ public class HashMap<K, V> extends AbstractMap<K, V> implements Map<K, V>, Cloneable, Serializable { static class Entry<K, V> implements Map.Entry<K, V> { final K key; V value; Entry<K, V> next; // 存储指向下一个 Entry 的引用,单链表结构 int hash; // 对 key 的 hashcode 值进行 hash 运算后得到的值,存储在 Entry,避免重复计算 Entry(int h, K k, V v, Entry<K, V> n) { value = v; next = n; key = k; hash = h; }
综上,HashMap 的整体结构:

简单来说,HashMap 由数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的。
如果定位到的数组位置不含链表(当前 entry 的 next 指向 null),那么对于查找,添加等操作很快,仅需一次寻址即可。
如果定位到的数组包含链表,对于添加操作,其时间复杂度为 O(n),首先遍历链表,存在即覆盖,否则新增。
对于查找操作来讲,仍需遍历链表,然后通过 key 对象的 equals 方法逐一比对查找。所以,性能考虑,HashMap 中的链表出现越少,性能才会越好。
构造器
/** * JDK_1.7.0_80 */ public class HashMap<K, V> extends AbstractMap<K, V> implements Map<K, V>, Cloneable, Serializable { public HashMap() { this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR); } public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); } /** * HashMap 有 4 个构造器,如果用户没有传入 initialCapacity 和 loadFactor 这两个参数,会使用默认值 initialCapacity,默认为 16,loadFactory 默认为 0.75 */ public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; threshold = initialCapacity; init(); } public HashMap(Map<? extends K, ? extends V> m) { this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1, DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR); inflateTable(threshold); putAllForCreate(m); } void init() { }
HashMap 操作
put 添加元素
当发生哈希冲突并且 size 大于阈值的时候,需要进行数组扩容。
扩容时,需要新建一个长度为之前数组 2 倍的新数组,然后将当前的 Entry 数组中的元素全部传输过去。
扩容后的新数组长度为之前的 2 倍,所以扩容相对来说是个耗资源的操作。
/** * JDK_1.7.0_80 */ public class HashMap<K, V> extends AbstractMap<K, V> implements Map<K, V>, Cloneable, Serializable { public V put(K key, V value) { if (table == EMPTY_TABLE) { // 数组为空进行扩容 inflateTable(threshold); } if (key == null) // 判断 key 为 null 的情况,如果为 null,那么 key 的 hash 值为 0,之后返回 null return putForNullKey(value); // null 总是放在数组的第一个链表中 int hash = hash(key); int i = indexFor(hash, table.length); // 找到数组下表 for (Entry<K, V> e = table[i]; e != null; e = e.next) { // 遍历链表 Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { // 如果 key 在链表中已存在,则替换为新 value V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); // 如果 key 在链表中不存在则插入 return null; } private static int roundUpToPowerOf2(int number) { // assert number >= 0 : "number must be non-negative"; return number >= MAXIMUM_CAPACITY ? MAXIMUM_CAPACITY : (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1; } private void inflateTable(int toSize) { // Find a power of 2 >= toSize int capacity = roundUpToPowerOf2(toSize); // 得到大于等于最接近 toSize 的 2 的幂值 threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); // 对 threshold 进行重新赋值 table = new Entry[capacity]; // 创建一个长度为 capacity 的数组 initHashSeedAsNeeded(capacity); // 初始化 Hash 种子,即 rehash } void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { // 当 size 超过临界阈值 threshold,并且即将发生哈希冲突时,进行扩容 resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); // 将元素加入到数组中 }
resize 扩容机制
为了便于理解这里仍然使用 JDK1.7 的代码,本质上区别不大。JDK8 以后引入了红黑树对查询性能进行了优化。当 Hash 桶里面的数量大于 8 且总容量大于 64,就会转为红黑树。
/** * JDK_1.7.0_80 */ public class HashMap<K, V> extends AbstractMap<K, V> implements Map<K, V>, Cloneable, Serializable { void resize(int newCapacity) { // 传入新的容量 Entry[] oldTable = table; // 引用扩容前的 Entry 数组 int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { // 扩容前的数组大小如果已经达到最大(2^30)了 threshold = Integer.MAX_VALUE; // 修改阈值为 int 的最大值(2^31-1),这样以后就不会扩容了 return; } Entry[] newTable = new Entry[newCapacity]; // 初始化一个新的 Entry 数组 transfer(newTable, initHashSeedAsNeeded(newCapacity)); // 将数据转移到新的 Entry 数组里 table = newTable; // HashMap 的 table 属性引用新的 Entry 数组 threshold = (int) Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); // 修改阈值 } void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; for (Entry<K, V> e : table) { // 遍历旧的 Entry 数组 while (null != e) { Entry<K, V> next = e.next; // 取得旧 Entry 数组的每个元素 if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); // 重新计算每个元素在数组中的位置 e.next = newTable[i]; // 标记[i] newTable[i] = e; // 将元素放在数组上 e = next; // 访问下一个 Entry 链上的元素 } } } static int indexFor(int h, int length) { // 在旧数组中同一条 Entry 链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上 return h & (length - 1); }
经过观测可以发现,我们使用的是 2 次幂的扩展(指长度扩为原来 2 倍),所以,经过 rehash 之后,元素的位置要么是在原位置,要么是在原位置再移动 2 次幂的位置。
JDK1.8 对 HashMap 优化
构造器
public class HashMap<K, V> extends AbstractMap<K, V> implements Map<K, V>, Cloneable, Serializable { public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity); // 初始化时就计算 threshold 值,JDK7 是在 put 时 } static final int tableSizeFor(int cap) { // 类似 JDK7 的 roundUpToPowerOf2 方法,返回大于等于最接近 cap 的 2 的冪数 // 例如 12->16,7->8,8->8,17->32 int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }
红黑树
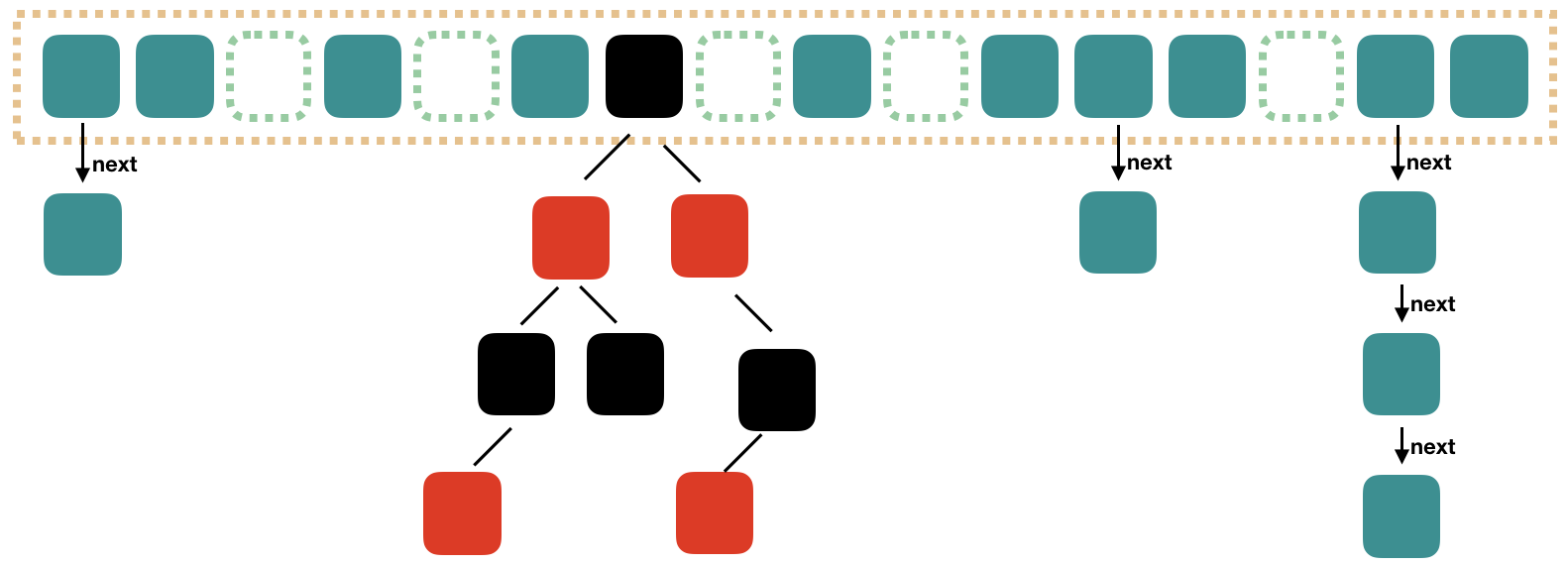
public class HashMap<K, V> extends AbstractMap<K, V> implements Map<K, V>, Cloneable, Serializable { static final int TREEIFY_THRESHOLD = 8; // 由链表转换成树的阈值,值与泊松分布有关,基于空间复杂度和时间复杂度的一个权衡 static final int UNTREEIFY_THRESHOLD = 6; // 由树转换成链表的阈值 // 当哈希表中的容量大于这个值时,表中的桶才能进行树形化,否则桶内元素太多时会 resize 扩容,而不是树形化 // 为了避免进行扩容、树形化选择的冲突,这个值不能小于 4 * TREEIFY_THRESHOLD static final int MIN_TREEIFY_CAPACITY = 64;
Equals 和 HashCode
HashCode 用于寻找当前元素存在数组的那个位置,Equals 用于判断当前元素与要存入位置上的元素是否相等(如果要插入位置正好有元素的话)


public class Test { public static void main(String[] args) { HashMap<Person, String> map = new HashMap<>(); Person person = new Person("jhxxb"); map.put(person, "jhxxb"); // 应该能输出 jhxxb? System.out.println("result: " + map.get(new Person("jhxxb"))); System.out.println(person.hashCode()); System.out.println(new Person("jhxxb").hashCode()); } @AllArgsConstructor // @EqualsAndHashCode private static class Person { String name; @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Person person = (Person) o; return Objects.equals(name, person.name); } // @Override // public int hashCode() { // return Objects.hash(name); // } } }
P3C
【推荐】集合初始化时,指定集合初始值大小。
- 说明:HashMap 使用 HashMap(int initialCapacity) 初始化,如果暂时无法确定集合大小,那么指定默认值(16)即可。
- 正例:initialCapacity = (需要存储的元素个数 / 负载因子) + 1。注意负载因子(即 loader factor)默认为 0.75,如果暂时无法确定初始值大小,请设置为 16(即默认值)。
- 反例: HashMap 需要放置 1024 个元素,由于没有设置容量初始大小,随着元素增加而被迫不断扩容,resize()方法总共会调用 8 次,反复重建哈希表和数据迁移。当放置的集合元素个数达千万级时会影响程序性能。
【推荐】使用 entrySet 遍历 Map 类集合 KV,而不是 keySet 方式进行遍历。
- 说明:keySet 其实是遍历了 2 次,一次是转为 Iterator 对象,另一次是从 hashMap 中取出 key 所对应的 value。而 entrySet 只是遍历了一次就把 key 和 value 都放到了 entry 中,效率更高。如果是 JDK8,使用 Map.forEach 方法。
- 正例:values()返回的是 V 值集合,是一个 list 集合对象;keySet()返回的是 K 值集合,是一个 Set 集合对象;entrySet()返回的是 K-V 值组合集合。
【推荐】高度注意 Map 类集合 K/V 能不能存储 null 值的情况,如下表格:
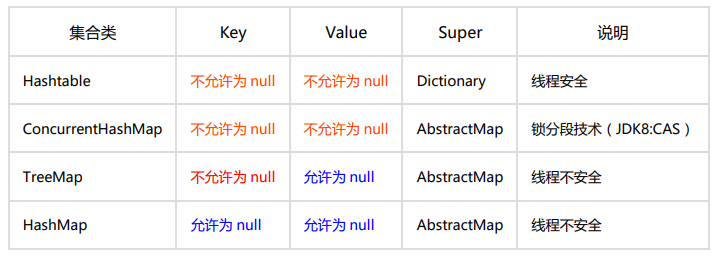
- 反例:由于 HashMap 的干扰,很多人认为 ConcurrentHashMap 是可以置入 null 值,而事实上,存储 null 值时会抛出 NPE 异常。
https://blog.csdn.net/f641385712/article/details/81147941
https://tech.meituan.com/2016/06/24/java-hashmap.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号