Spark Deploying
Components
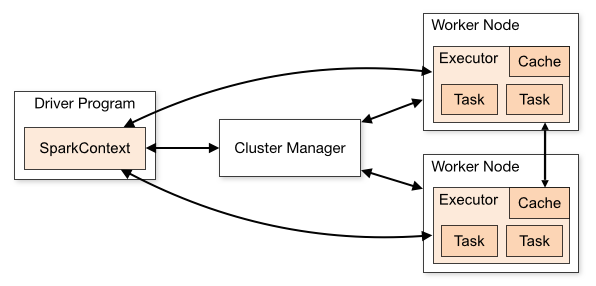
https://blog.csdn.net/Young_IT/article/details/133808672 & https://segmentfault.com/a/1190000038683520
Local
单机,Spark 做计算,也做资源调度
curl -LOJ https://mirrors.cloud.tencent.com/apache/spark/spark-3.5.5/spark-3.5.5-bin-hadoop3.tgz sudo tar -zxf spark-3.5.5-bin-hadoop3.tgz -C /opt cd /opt/spark-3.5.5-bin-hadoop3 ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master local[*] \ ./examples/jars/spark-examples_*.jar \ 10
YARN
集群,Spark 做计算,YARN 做资源调度
cp conf/spark-env.sh.template conf/spark-env.sh vim conf/spark-env.sh YARN_CONF_DIR=/opt/hadoop-3.4.1/etc/hadoop cp conf/spark-defaults.conf.template conf/spark-defaults.conf vim conf/spark-defaults.conf spark.eventLog.enabled true spark.eventLog.dir hdfs://localhost:9000/spark-logs spark.yarn.historyServer.address localhost:18080 spark.history.ui.port 18080 vim conf/spark-env.sh export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=30 -Dspark.history.fs.logDirectory=hdfs://localhost:9000/spark-logs " /opt/hadoop-3.4.1/bin/hdfs namenode -format /opt/hadoop-3.4.1/sbin/start-dfs.sh /opt/hadoop-3.4.1/bin/hdfs dfs -mkdir -p /spark-logs /opt/hadoop-3.4.1/sbin/start-yarn.sh sbin/start-history-server.sh ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode client \ ./examples/jars/spark-examples_*.jar \ 10
Spark History Server WebUI:http://localhost:18080
deploy-mode 默认 client(Driver Program(spark jar) 在 Submit 节点运行,结果可在客户端显示),生产环境建议用 cluster(在集群中运行,结果不能在客户端显示) 提交应用运行
节点预部署问题:spark.yarn.archive 和 spark.yarn.jars
hdfs dfs -mkdir /spark-jars hadoop fs -put jars/* /spark-jars ./bin/spark-submit \ --master yarn \ --deploy-mode client \ --conf spark.yarn.jars="hdfs://localhost:9000/spark-jars/*.jar" \ --class org.apache.spark.examples.SparkPi \ ./examples/jars/spark-examples_*.jar \ 10 zip -qrj spark_jars_3.5.5.zip jars/* # hadoop fs -rm -r /spark-archive hdfs dfs -mkdir /spark-archive hadoop fs -put spark_jars_3.5.5.zip /spark-archive ./bin/spark-submit \ --master yarn \ --deploy-mode client \ --conf spark.yarn.archive=hdfs://localhost:9000/spark-archive/spark_jars_3.5.5.zip \ --class org.apache.spark.examples.SparkPi \ ./examples/jars/spark-examples_*.jar \ 10 hdfs dfs -mkdir /spark-apps hadoop fs -put examples/jars/spark-examples_*.jar /spark-apps ./bin/spark-submit \ --master yarn \ --deploy-mode client \ --conf spark.yarn.jars=hdfs://localhost:9000/spark-jars/*.jar \ --class org.apache.spark.examples.SparkPi \ hdfs://localhost:9000/spark-apps/spark-examples_2.12-3.5.5.jar \ 10
Standalone
集群,Spark 做计算,也做资源调度
sbin/start-master.sh sbin/start-worker.sh spark://localhost:7077 bin/spark-shell --master spark://master:7077
Spark Shell WebUI:http://127.0.0.1:4040,Spark Master/Worker WebUI:http://127.0.0.1:8080
https://spark.apache.org/docs/latest/cluster-overview.html
https://spark.apache.org/docs/latest/monitoring.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号