

Hadoop Single Node Cluster
https://hadoop.apache.org/releases.html & https://dlcdn.apache.org/hadoop
准备工作
安装 SSHD
sudo apt install --reinstall -y openssh-server sudo systemctl start ssh # sudo service ssh restart ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys ssh localhost
下载 JDK
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
curl -LOJ https://repo.huaweicloud.com/java/jdk/8u202-b08/jdk-8u202-linux-x64.tar.gz tar -zxf jdk-8u202-linux-x64.tar.gz -C /opt/
安装 Hadoop
镜像:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop、https://mirrors.huaweicloud.com/apache/hadoop/、https://mirrors.aliyun.com/apache/hadoop、https://mirrors.cloud.tencent.com/apache/hadoop/
Windows 还需下载 winutils.exe 和 hadoop.dll 放入 bin 目录下,也可自行编译
curl -LOJ https://mirrors.cloud.tencent.com/apache/hadoop/common/stable/hadoop-3.4.1.tar.gz tar -zxf hadoop-3.4.1.tar.gz -C /opt/ cd /opt/hadoop-3.4.1 bin/hadoop version
配置 Hadoop 伪分布式
2.X 默认端口,HDFS NameNode 内部通信:8020 或 9000,HDFS NameNode HTTP UI:50070,HDFS DataNode HTTP UI:50075,Yarn 任务执行状态查看:8088,历史服务器通信:19888。
3.X 默认端口,HDFS NameNode 内部通信:8020、9000 或 9820,HDFS NameNode HTTP UI:9870,HDFS DataNode HTTP UI:9864,Yarn 任务执行状态查看:8088,历史服务器通信:19888。
配置文件,core-site.xml:系统设置。hdfs-site.xml:定义文件系统的参数。yarn-site.xml:资源管理器的配置。mapred-site.xml:MapReduce 作业的配置。workers(3.X)/slaves(2.X):定义集群中的工作节点。
一、配置 HDFS
vim etc/hadoop/hadoop-env.sh export JAVA_HOME=/opt/jdk1.8.0_202 vim etc/hadoop/core-site.xml <configuration> <property><!-- 指定 HDFS 中 NameNode 的地址 --> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value><!-- hostnamectl status | grep "Static hostname" --> </property> <property><!-- 指定 Hadoop 运行时产生文件的存储目录 --> <name>hadoop.tmp.dir</name> <value>/opt/hadoopTmp</value> </property> </configuration> vim etc/hadoop/hdfs-site.xml <configuration> <property><!-- 指定 HDFS 副本的数量 --> <name>dfs.replication</name> <value>1</value> </property> </configuration> bin/hdfs namenode -format sbin/start-dfs.sh
访问(2.x默认50070,3.x默认9870)端口查看 web 端
bin/hdfs dfs -mkdir -p /user/$USER bin/hdfs dfs -mkdir input bin/hdfs dfs -put etc/hadoop/*.xml input bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.1.jar grep input output 'dfs[a-z.]+' # bin/hdfs dfs -get output output # cat output/* bin/hdfs dfs -cat output/*
二、配置 YARN
vim etc/hadoop/yarn-site.xml <configuration> <property><!-- Reducer 获取数据的方式 --> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value> </property> <property><!-- 物理内存检查 --> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property><!-- 虚拟内存检查 --> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration> sbin/start-yarn.sh
访问 8088 端口查看 web 端
三、配置 MapReduce
vim etc/hadoop/mapred-site.xml <configuration> <property><!-- 指定 MR 运行在 YARN 上 --> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value> </property> </configuration> # 运行一个计算圆周率的 MapReduce 任务 bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.1.jar pi 10 100
访问 8088 端口可查看记录

其它
一、启动 jobhistory,查看历史记录
bin/mapred --daemon start historyserver
访问 19888 端口查看 web 端
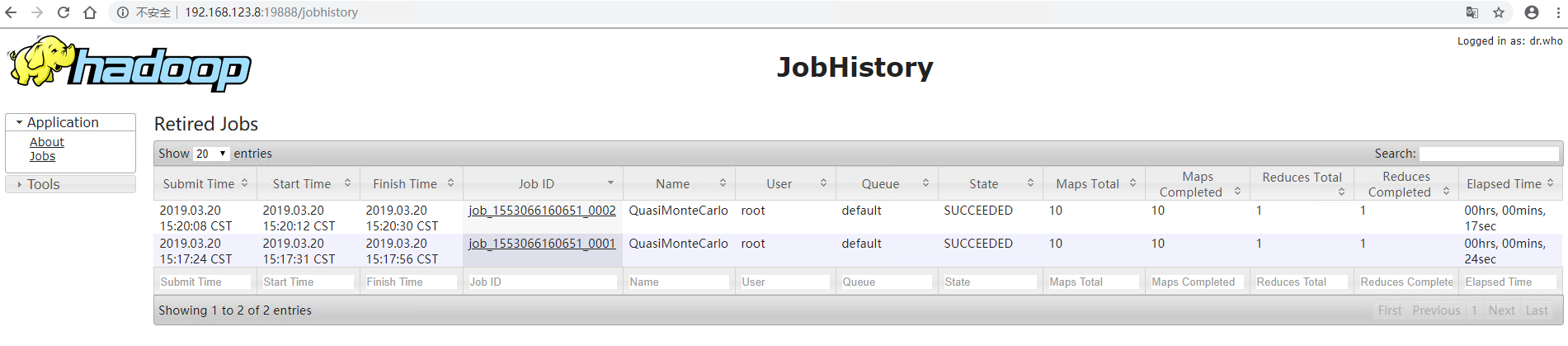
二、配置 log-aggregation,查看运行详情
vim etc/hadoop/yarn-site.xml <configuration> <property><!-- 开启日志聚集功能 --> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property><!-- 设置日志保留时间(7天) --> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration> # 重启服务 bin/mapred --daemon stop historyserver sbin/stop-yarn.sh sbin/stop-dfs.sh sbin/start-dfs.sh sbin/start-yarn.sh bin/mapred --daemon start historyserver bin/mapred --daemon stop historyserver bin/yarn --daemon stop nodemanager bin/yarn --daemon stop resourcemanager bin/hdfs --daemon stop secondarynamenode bin/hdfs --daemon stop namenode bin/hdfs --daemon stop datanode bin/hdfs --daemon start namenode bin/hdfs --daemon start datanode bin/hdfs --daemon start secondarynamenode bin/yarn --daemon start resourcemanager bin/yarn --daemon start nodemanager bin/mapred --daemon start historyserver # 再运行一个任务,就可以看到详情 bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.1.jar pi 10 100
查看刚刚运行的任务的详情,未开启 log-aggregation 之前运行的任务无法查看详情
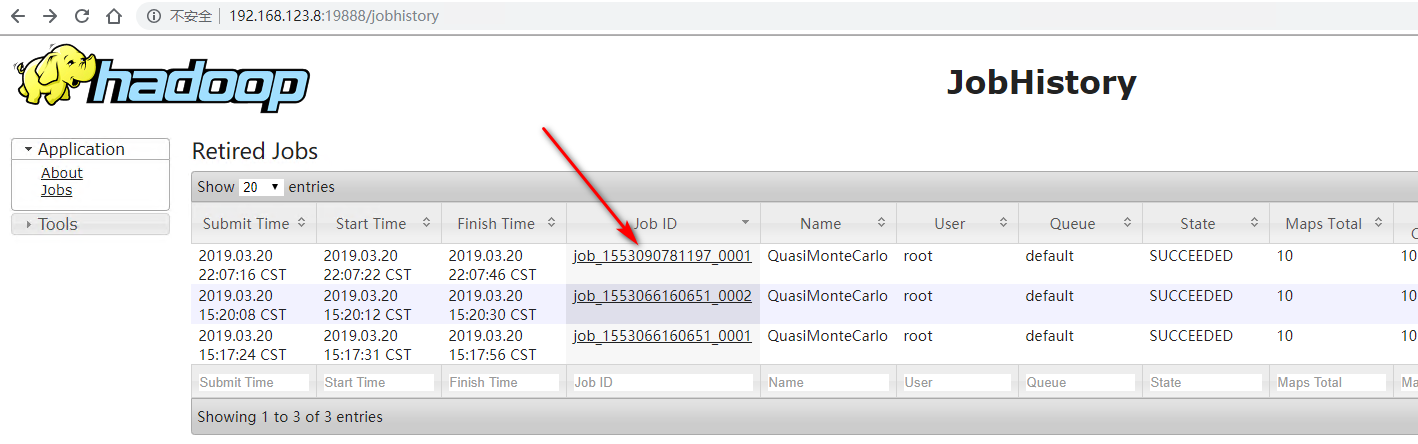
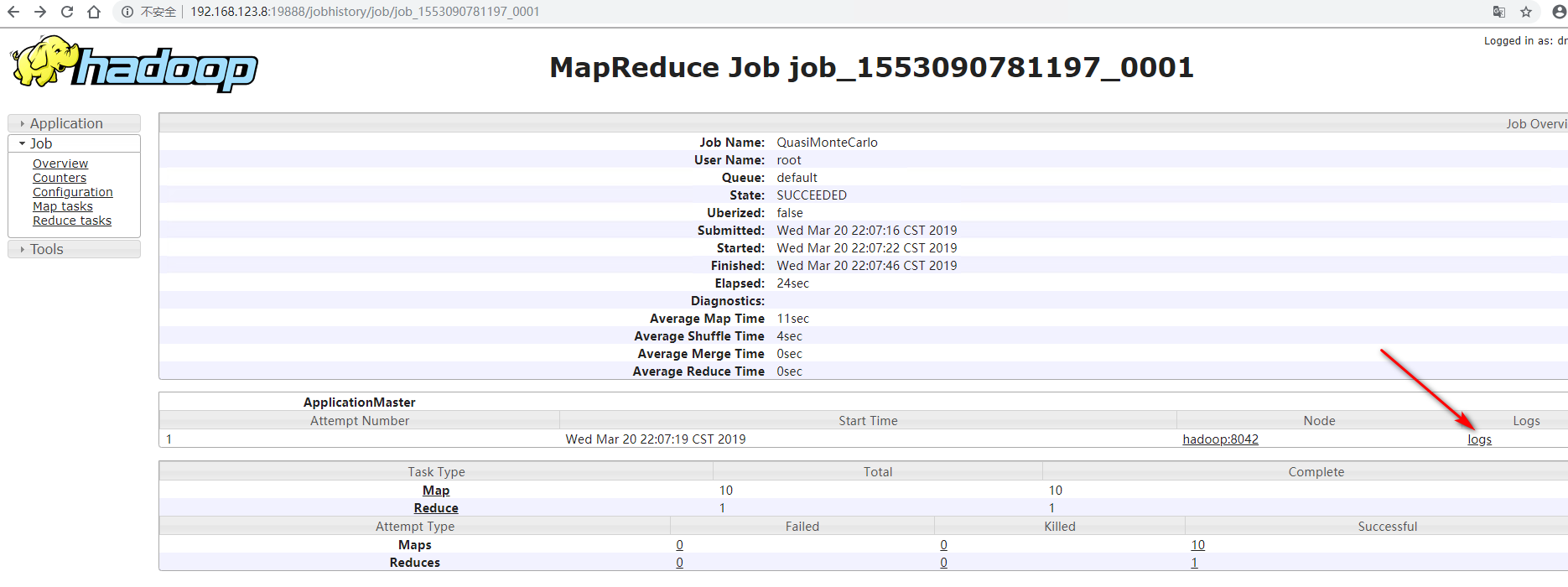
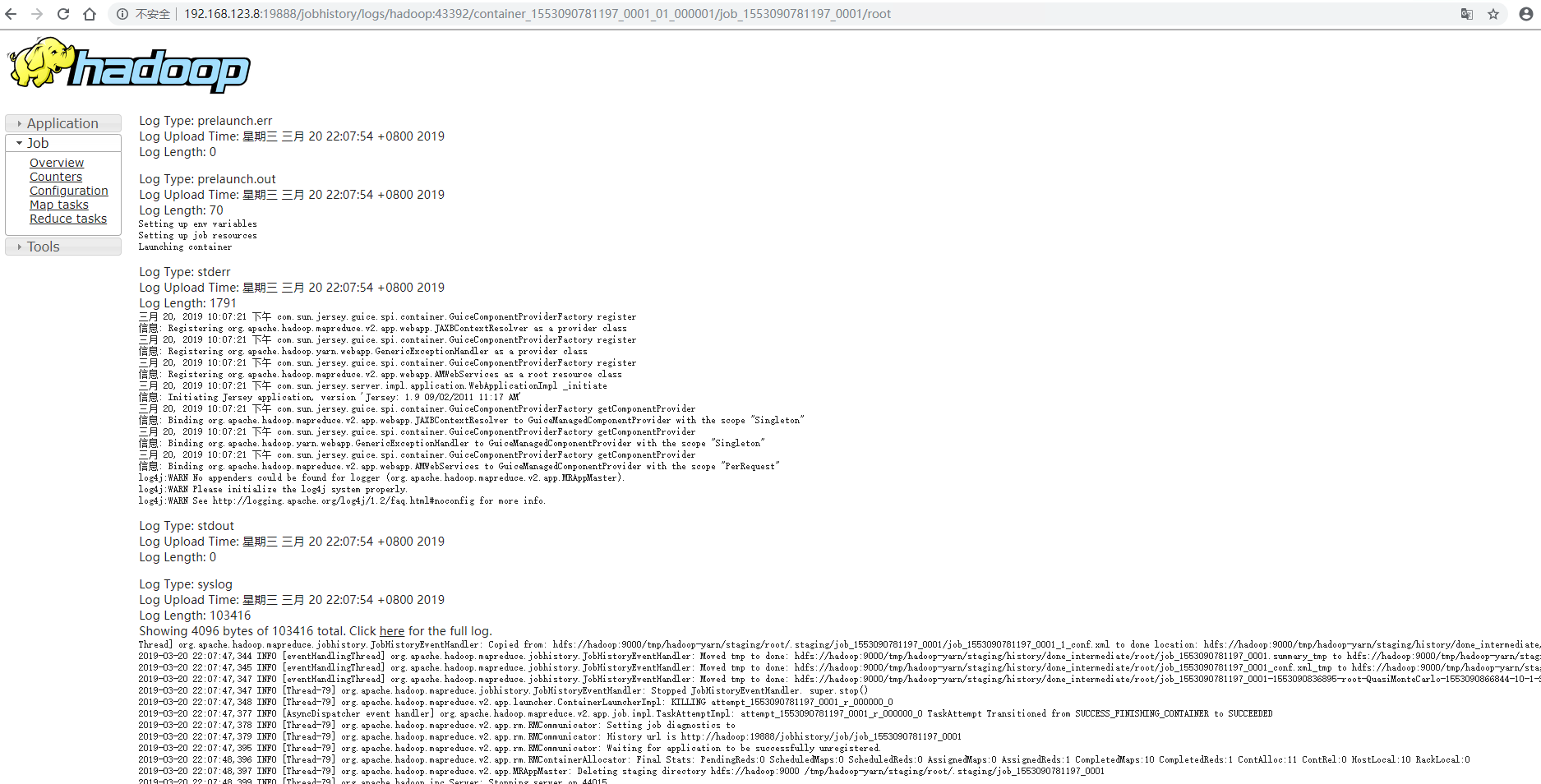
https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html
https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/ResourceManagerRest.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号