MapReduce框架在Yarn上的具体解释
MapReduce任务解析
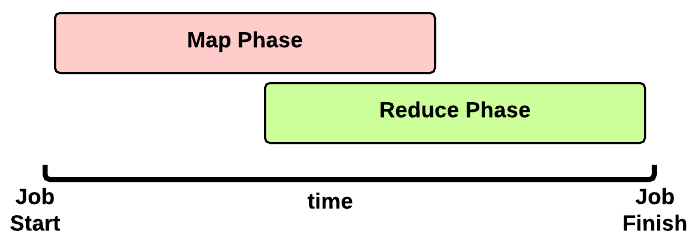
在YARN上一个MapReduce任务叫做一个Job。
一个Job的主程序在MapReduce框架上实现的应用名称叫MRAppMaster.
MapReduce任务的Timeline
这是一个MapReduce作业运行时间:
- Map 阶段:依据数据块会运行多个Map Task
- Reduce 阶段:依据配置项会运行多个Reduce Task
为提高Shuffle效率Reduce阶段会在Map阶段结束之前就開始。(直到全部MapTask完毕之后ReduceTask才干完毕。由于每一个ReduceTask依赖全部的MapTask的结果)
Map阶段
首先看看Map阶段,一个Job须要多少Map Task吧
用户会提交什么?
当一个client提交的应用时会提供下面多种类型的信息到YARN上。
- 一个configuration(配置项):Hadoop有默认的配置项,所以即使什么都不写它也有默认的配置项载入。
优先级高到低顺序是用户指定的配置项>etc/conf下的XML>默认配置项
- 一个JAR包
- 一个map()实现(Map抽象类的实现)
- 一个combiner 实现(combiner抽象类的实现,默认是跟Reduce实现一样)
- 一个reduce()实现(Reduce抽象类的实现)
- 输出输入信息:
- 输入文件夹:输入文件夹的指定。如输入HDFS上的文件夹、S3或是多少个文件。
- 输出文件夹:输出文件夹的指定。在HDFS还是在S3。
输入文件夹中的文件数用于决定一个Job的MapTask的数量。
那么究竟会有多少个MapTask呢?
Application Master会为每个split(分片)创建一个MapTask。通常情况下,每个文件都会是一个split。
假设文件太大(大于128M、HDFS默认块大小)就会分为多个split并关联到这个文件,也就是一个文件会产生多个Map Task。获取split数量方法代码例如以下 getSplits() of the FileInputFormat class:
num_splits = 0
for each input file f:
remaining = f.length
while remaining / split_size > split_slope:
num_splits += 1
remaining -= split_size
split_slope = 1.1
split_size =~ dfs.blocksize
MapTask运行过程
Application Master会向Resource Maneger资源管理器提交job所须要的资源:为每个split文件申请一个container来执行Map Task。
为了提高文件读取效率container在map split所在的机器上执行是最为理想的。因此AM会依据数据本地性>CPU>内存匹配的方式分配container
- 假设发现一个Node Manager上有所需的map split那么相关的container就会分配到这个NM上(由于依据HDFS备份机制有3台机器上同一时候拥有同样的块);
- 否则, 会分配到机柜内的其它机器上;
- 否则, 会分配到集群上的不论什么一个机器上
当容器被分配给AM时Map Task任务就会启动。
Map 阶段:演示样例
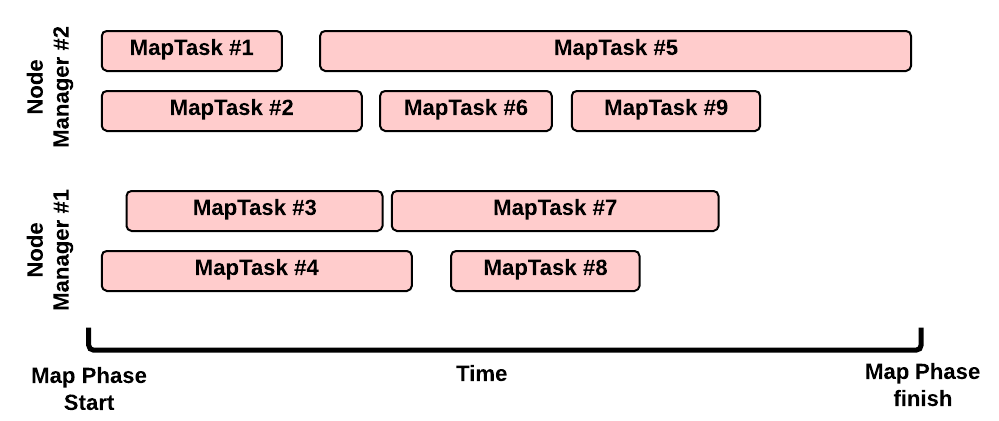
这是一个典型的Map运行场景:
- 有2个Node Manager:每一个Node Manager拥有2GB内存,而每一个MapTask须要1GB内存。因此每一个NM能够同一时候执行2个container
- 没有其它的应用程序在集群中执行
- 我们的job有9个split (比如,在输入文件夹里有8个文件。但当中仅仅有一个是大于HDFS块大小的文件,所以我们把它分为2个map split);因此须要9个map
MapTask运行的Timeline
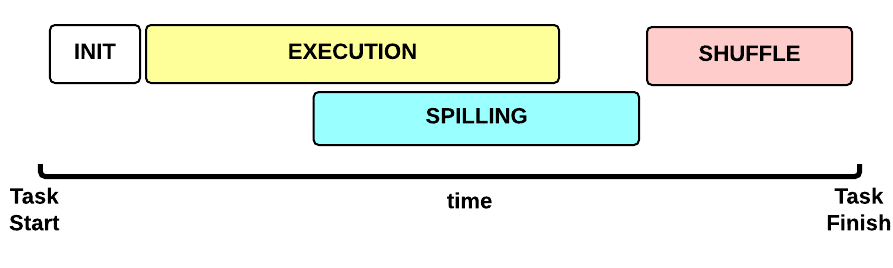
如今让我们专注于一个Map Task任务。这是Map Task任务运行时间线:
- 初始化(INIT)阶段:初始化Map Task(默认是什么都没有。。
)
- 运行(EXECUTION)阶段: 对于每一个 (key, value)运行map()函数
- 排序(SPILLING)阶段:map输出会暂存到内存其中排序,当缓存达到一定程度时会写到磁盘上。并删除内存里的数据
- SHUFFLE 阶段:排序结束后,会合并全部map输出,并分区传输给reduce。
MapTask:初始化(INIT)
1. 创建一个Task上下文,Reduce也继承自它(TaskAttemptContext.class)
2. 创建MAP实例 Mapper.class
3. 设置input (e.g., InputFormat.class, InputSplit.class, RecordReader.class)
4. 设置output (NewOutputCollector.class)
5. 创建mapper的上下文(MapContext.class, Mapper.Context.class)
6. 初始化输入。比如
7. 创建一个SplitLineReader.class object
8. 创建一个HdfsDataInputStream.class object
MapTask:运行(EXECUTION)
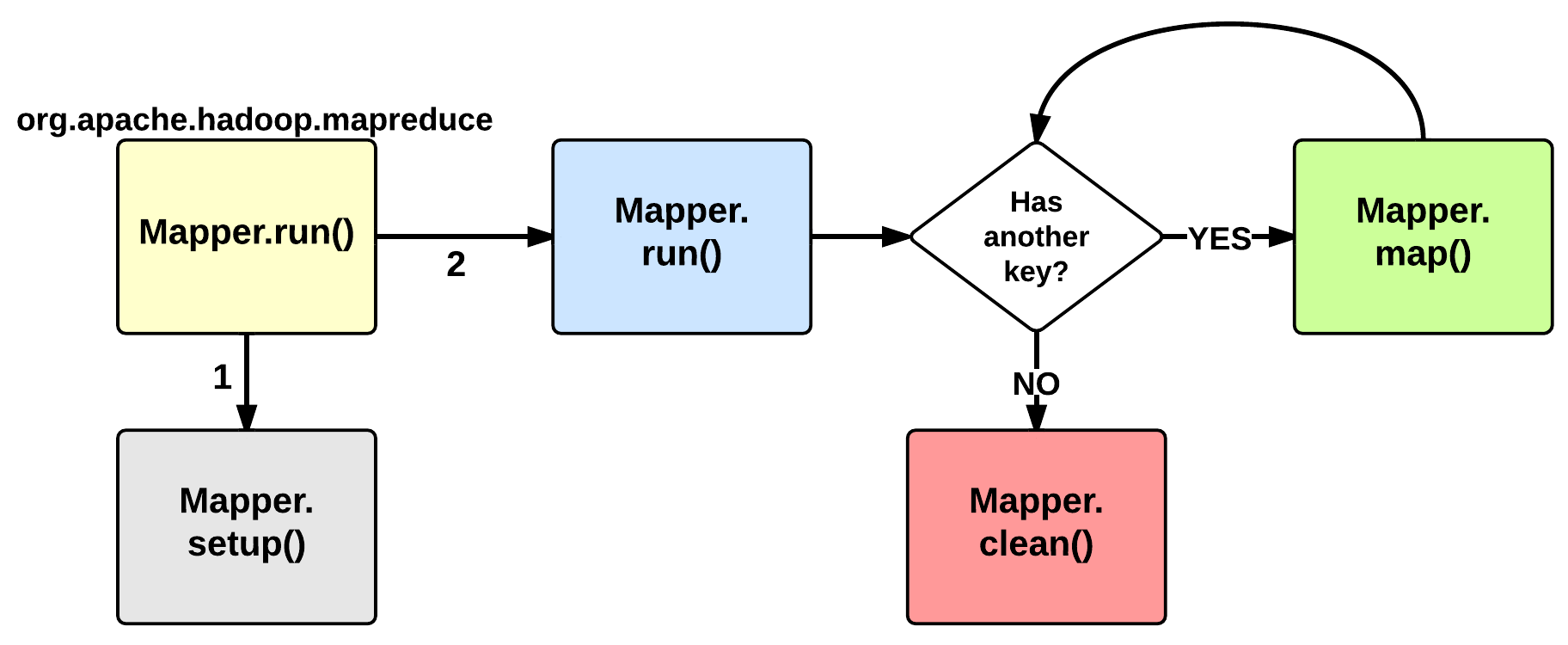
Map的运行阶段从 Mapper class的run 方法開始,我们通常要写的也就是它了。默认情况下run之前会调用setup方法:这个函数没有做不论什么事情。可是我们能够重写它来配置相关的类变量等信息。运行setup方法之后会对每个<key, value>运行map()函数。
之后map context会存储这些数据到一个缓存区。为兴许排序做准备。
当map运行完处理时。还会调用一个clean方法:默认情况下,也不运行不论什么操作,但用户也能够重写它。
MapTask:排序(SPILLING)
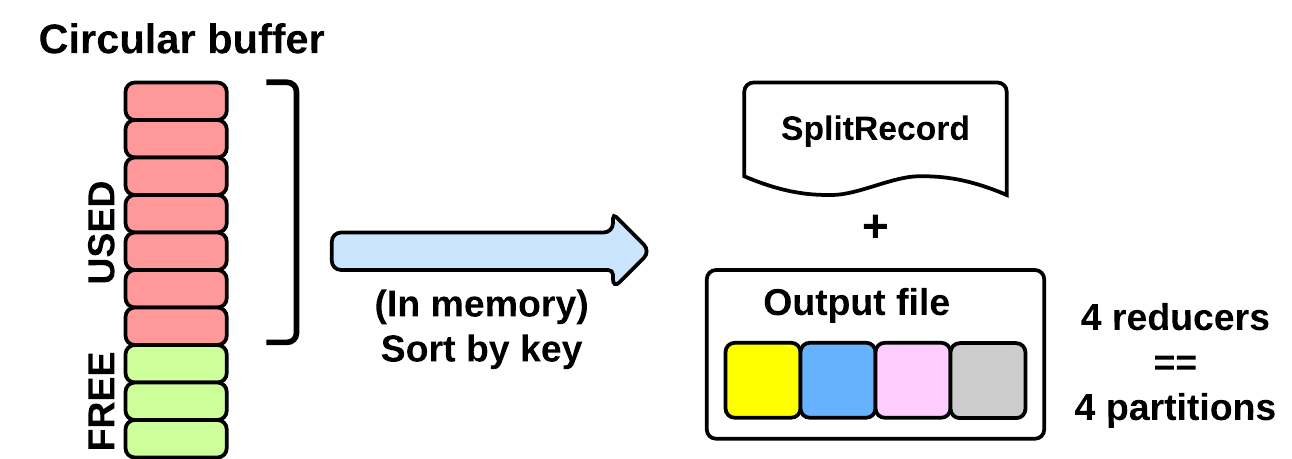
运行阶段期间map会把数据写进一个缓存区(MapTask.MapOutputBuffer)。这个缓存大小由配置项设定mapreduce.task.io.sort.mb (默认:100MB)。为了提高硬盘刷写速度缓存区达到80%会写数据到磁盘,会有一个单独的线程并行运行。当缓存区容量达到100%那么就要等到这个单独的线程把数据写完才干继续运行map方法。
排序线程会运行下面动作:
1. 创建一个SpillRecord和一个FSOutputStream (在本地文件系统)
2. 在内存中对键值对进行高速排序
3. 分区
4. 按顺序写入本地分区文件。
Shuffle阶段
也就说从Map函数出来之后到Reduce函数之前的全部数据操作都叫Shuffle操作。包含排序、合并、分区、传输等。
Reduce阶段
Reduce阶段的run与Map阶段的run运行是类似的。
ref:http://ercoppa.github.io/HadoopInternals/AnatomyMapReduceJob.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号