DEX文件解析 - string_ids解析
DEX文件解析 - string_ids解析
在上一篇中介绍了header的解析,那么接下来就要学习string_ids的解析。
1. string_ids结构
在android的aosp源码中,string_ids的结构如下:
aosp源码位置:art/libdexfile/dex/dex_file.h
// Raw string_id_item.
struct StringId {
uint32_t string_data_off_; // offset in bytes from the base address
private:
DISALLOW_COPY_AND_ASSIGN(StringId);
};
StringId在代码中是一个结构体类型,其中内部属性string_data_off_是一个无符号的4个字节数据,表示的是字符串数据的偏移量
在DexFile类中的StringId是一个指针变量,实际上是使用指针来表示数组
class DexFile {
// Points to the base of the string identifier list.
const StringId* const string_ids_;
}
2. 010Editor解析
如图,仔细观察
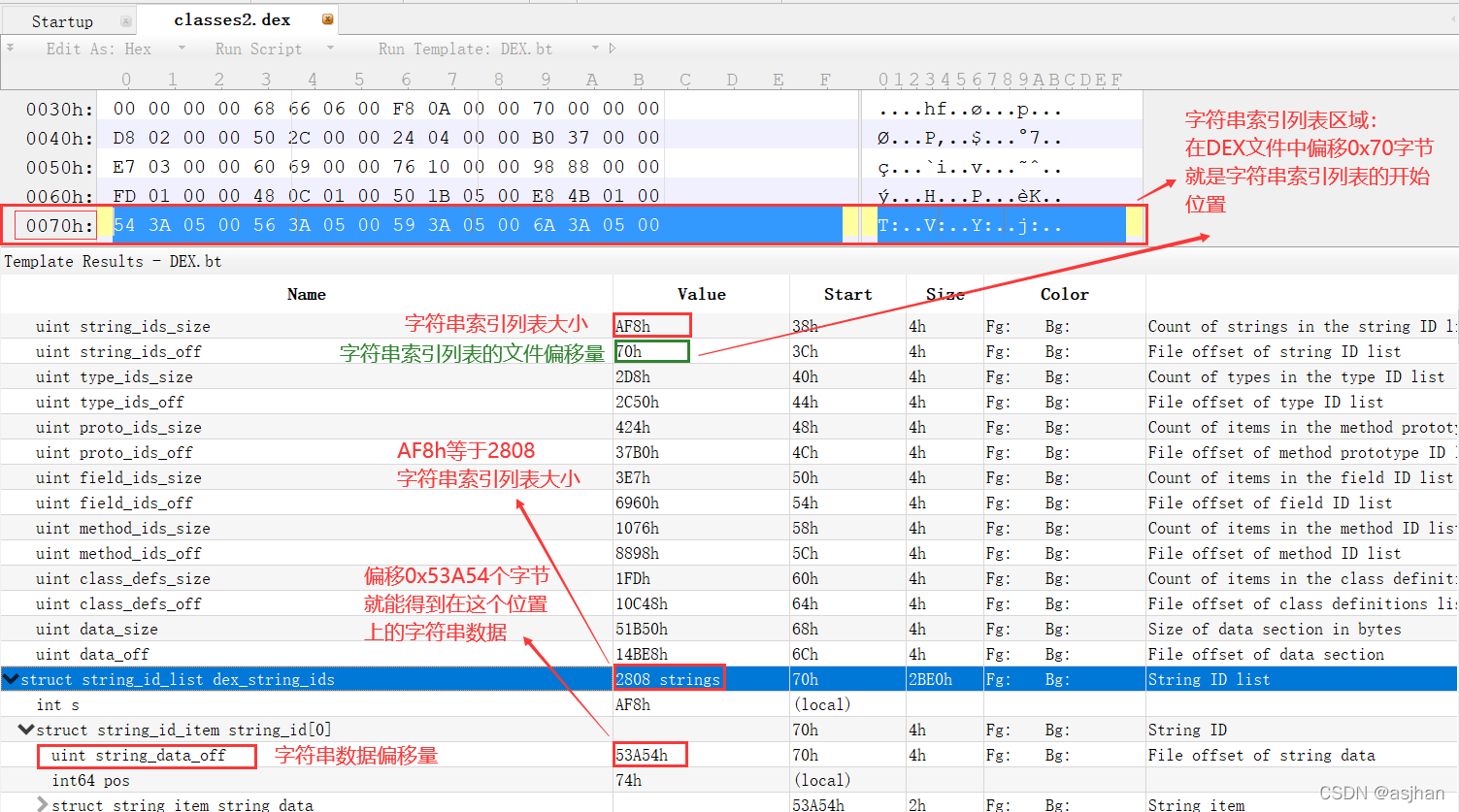
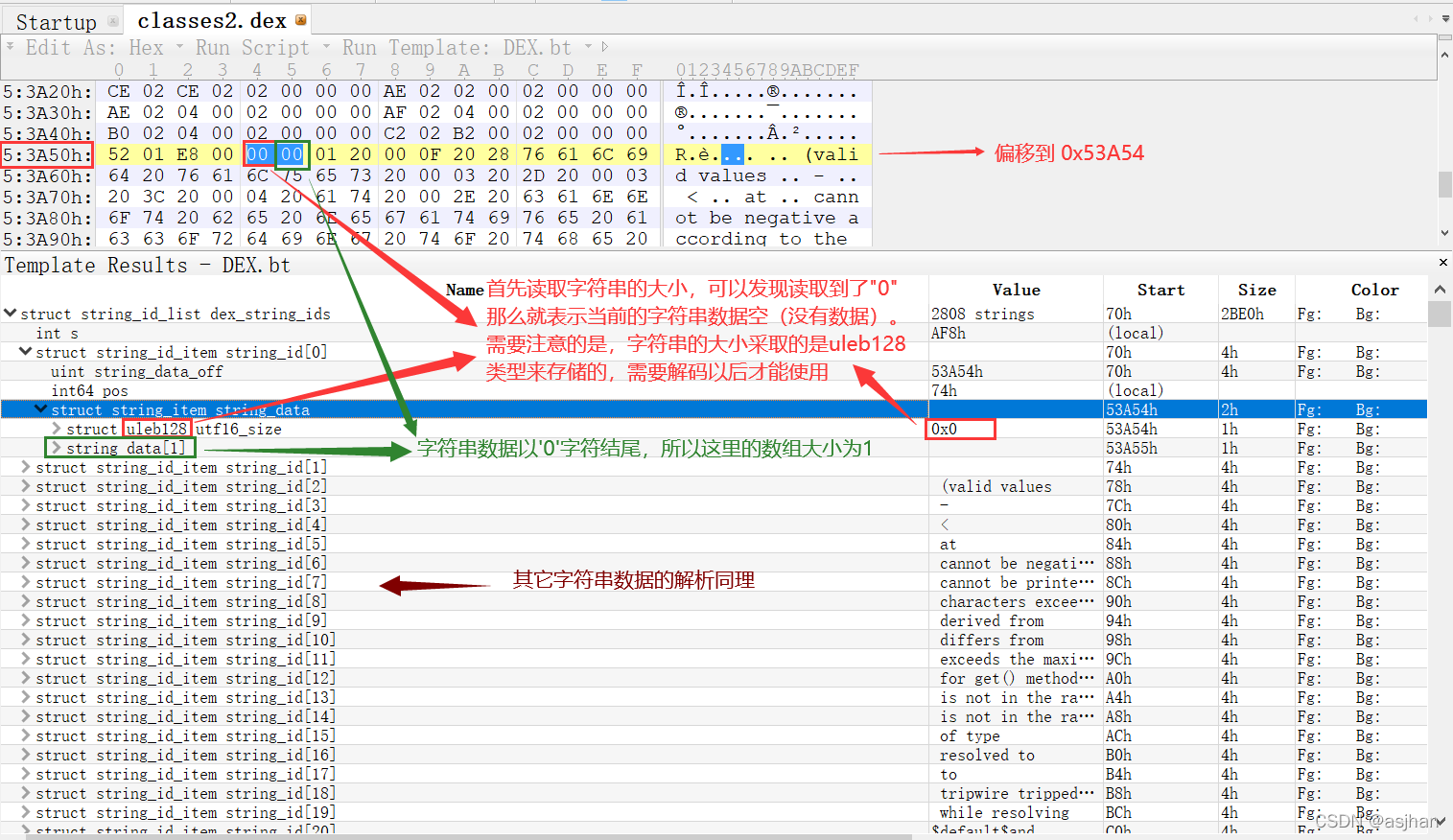
3. string_ids解析
java语言解析string_ids
/**
* 解析StringIds
* @param raf
* @return 字符串索引列表
*/
private static List<StringId> toPaeseDexStringIds(RandomAccessFile raf) {
try {
//字符串索引列表 stringIdsList
List<StringId> stringIdsList = new ArrayList<>();
//获取字符串索引列表的文件偏移量(string_ids_off),偏移到指定位置,解析字符串列表
raf.seek(mDexFile.getString_ids_off());
//获取字符串索引列表的大小,循环读取字符串池
for (int i=0;i<mDexFile.getString_ids_size();i++) {
//获取字符串数据的偏移量
int string_data_off = NumConversion.byteToInt(readData(raf, 4),false);
//记录当前偏移值
long curOff = raf.getFilePointer();
//偏移到当前字符串数据所在位置
raf.seek(string_data_off);
//当前字符串所在位置,需要读取的结构大致如下
// ------------------------
// | | |
// |size|string_data[size]|
// | | |
// ------------------------
//其中 size 表示的是字符串的字节数,size 采用 uleb128类型进行存储
//string_data[size] 表示的是具体的数据
//读取字符串的大小
byte uleb128Byte = raf.readByte();
ByteBuffer byteBuffer = ByteBuffer.allocate(5);
byteBuffer.put(uleb128Byte);
while ((uleb128Byte & 0xff) > 0x7f) { //uleb 判断是否需要下一个字节,最高位为1时表示需要 0x7f: 01111 1111
uleb128Byte = raf.readByte();
byteBuffer.put(uleb128Byte);
}
byte[] uLeb128Bytes = byteBuffer.array();
//将uleb128类型的数据进行解码转换成 int
int decodeuleb128=NumConversion.byteToIntformUleb128(uLeb128Bytes);
byte[] stringDataByte = null;
if(decodeuleb128 > 0) {
//根据解码的字符串大小,读取字符串数据
stringDataByte = readData(raf, decodeuleb128);
System.out.println(i+" uleb未解码结果:"+Arrays.toString(uLeb128Bytes) +" 解码uleb128: "+decodeuleb128+" 字符串:"+new String(stringDataByte));
}
//创建StringId类,保存数据
StringId stringId = new StringId();
stringId.setString_data_off(string_data_off);
stringId.setString_data_size(decodeuleb128);
stringId.setData(stringDataByte);
stringIdsList.add(stringIds);
//恢复偏移
raf.seek(curOff);
}
return stringIdsList;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
public static byte[] readData(RandomAccessFile raf,int limit) {
byte[] buff = new byte[limit];
try {
raf.read(buff);
} catch (IOException e) {
e.printStackTrace();
}
return buff;
}
工具类:NumConversion
/**
* uleb128转int
* ULEB128 需要的字节大约在: 1~5字节
* 转换规则:每一个字节只有7位为有效位,第一个字节若最高位为 1 ,表示ULEB128需要使用第二个字节,
* 如果第二个字节最高位为 1 ,则表示需要使用第三个字节,以此类推,知道最后一个字节最
* 高位为0为止。
*在转换过程中采用了小端字节序
* @return
*/
public static int byteToIntformUleb128(byte[] bytes) {
if ((bytes[0]&0xff) > 0x7f) { // 0x7f -> 0111 1111 = 127
//最高位为 1 ,表示需要第二个字节
int result = ((bytes[0]&0xff) & 0x7f) | ((bytes[1]&0xff) & 0x7f) << 7 ;
if((bytes[1]&0xff) > 0x7f) {
//最高位为 1 ,表示需要第三个字节
result = result | ((bytes[2]&0xff) & 0x7f) << 14;
if((bytes[2]&0xff) > 0x7f) {
//最高位为 1 ,表示需要第四个字节
result = result | (bytes[3] & 0x7f) << 21;
if((bytes[3]&0xff) > 0x7f) {
//最高位为 1 ,表示需要第五个字节
result = result | ((bytes[4]&0xff) & 0x7f) << 28;
}
}
}
return result;
}
return bytes[0] ; //说明 若第一个字节的大小在 0~127范围内,没有超过java中byte的最大值,没有溢出
}
实体类:StringId
public class StringId {
private int string_data_off; //字符串数据偏移
private int string_data_size; //字符串数据大小(uleb128类型解码的大小)
private byte[] data; //字符串数据
public int getString_data_off() {
return string_data_off;
}
public void setString_data_off(int string_data_off) {
this.string_data_off = string_data_off;
}
public int getString_data_size() {
return string_data_size;
}
public void setString_data_size(int string_data_size) {
this.string_data_size = string_data_size;
}
public byte[] getData() {
return data;
}
public void setData(byte[] data) {
this.data = data;
}
}
asjhan for Android reverse

 浙公网安备 33010602011771号
浙公网安备 33010602011771号