flink配置rocksdb状态后端,使用hdfs做checkpoint 和 savepoint
最近公司的项目需要使用flink做流数据处理,抓紧学习了一下,记录一下配置状态后端时候遇到的坑。
1. 最初,在使用默认的HashMapStateBackend做状态后端时,以yarn application模式运行flink任务正常,提交命令如下
flink run-application -t yarn-application -ynm chargetask /..../xxxx.jar
项目正常运行
2. 后来发现每次启动的时候,状态中的数据都会重新初始化,计数就不准确了,因此需要使用持久化的状态后端和checkpoint机制
在flink任务代码中添加如下语句

3. 提交flink任务时候发现任务执行失败,查看nodemanager日志发现 cpu not yet
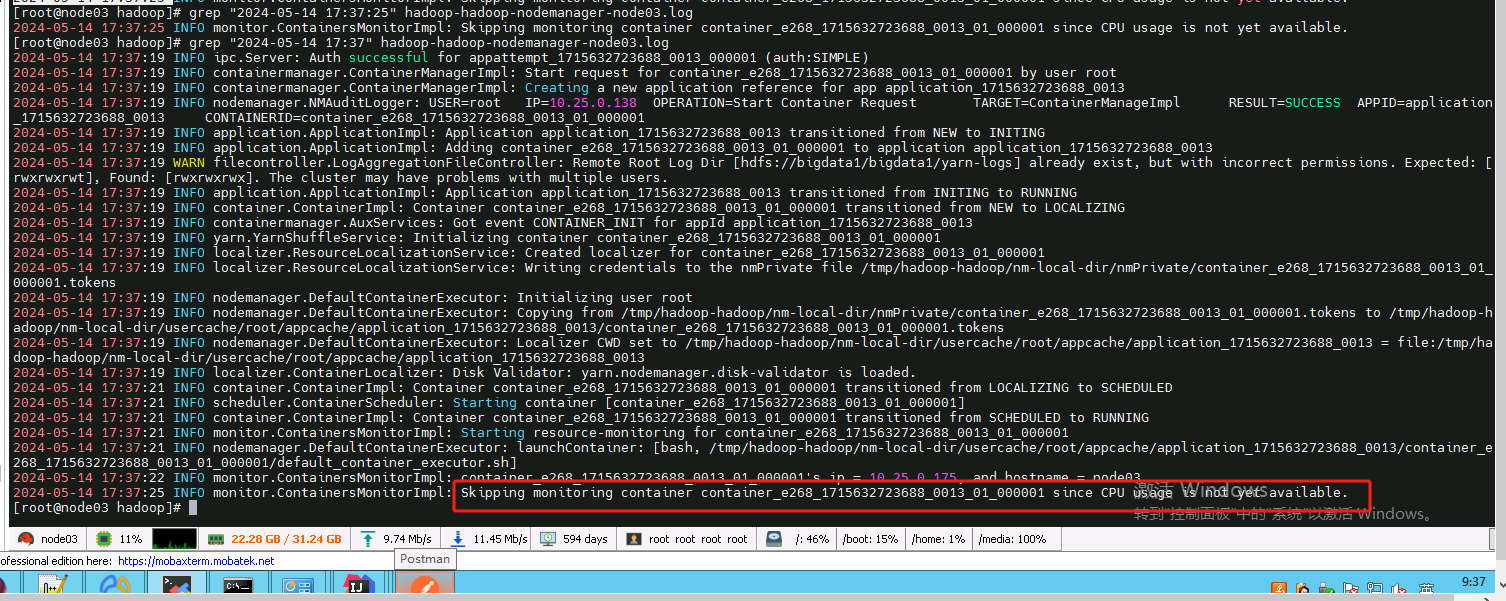
4. 最后查看配置的hdfs的路径当前linux用户没有写权限,授权后启动成功

5. 到这里还没有万事大吉,发现每次cancel job,升级jar包后再重新提交任务时,任务的jobid改变了,导致无法加载之前的checkpoint数据。而且checkpoint也从头开始了,状态数据也从0开始,如何处理呢,继续看
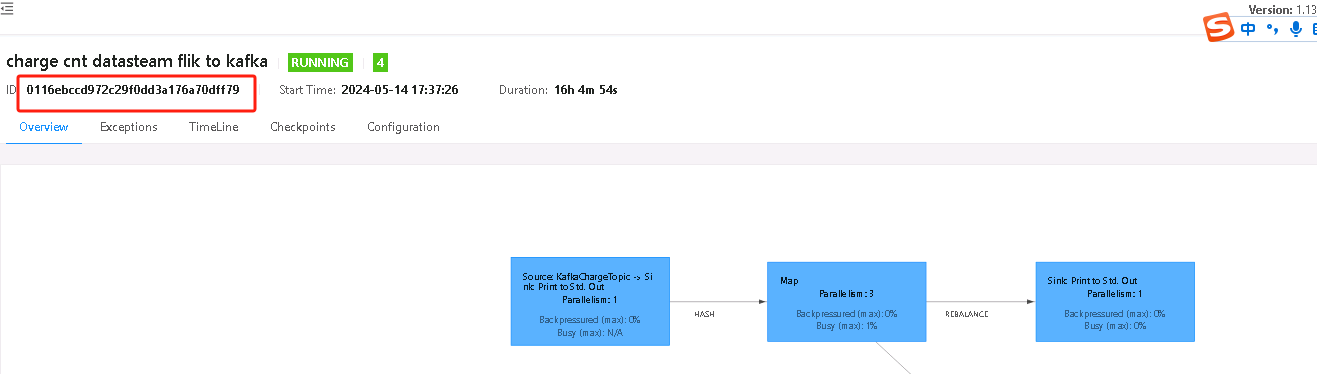
6. 这就要依赖之前保存下来的checkpoint和savepoint了,从hdfs中找到之前的checkpoint

7. 在提交flink任务时,添加上 -s参数,指定checkpoint 点,命令如下所示
flink run-application -t yarn-application -ynm chargetask -s hdfs://../../chk-11864/_metadata /..../xxxx.jar
8. 查看结果,之前的状态数据加载回来了,成功
9. 使用savepoint进行手动保存
flink savepoint jobID targetStorage -yid

本文来自博客园,作者:蓬莱寒剑,转载请注明原文链接:https://www.cnblogs.com/jhans/articles/18192091

 浙公网安备 33010602011771号
浙公网安备 33010602011771号