
102302145 黄加鸿 数据采集与融合技术作业4
作业4
作业①
1)代码与结果
目标:使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
之前几个作业采用的存储方式都是用python自带的轻量级且易于使用的一种嵌入式数据管理系统SQLite。但本次任务选择关系型数据库MySQL来存储,所以实验开始前要先在本机安装部署MySQL。
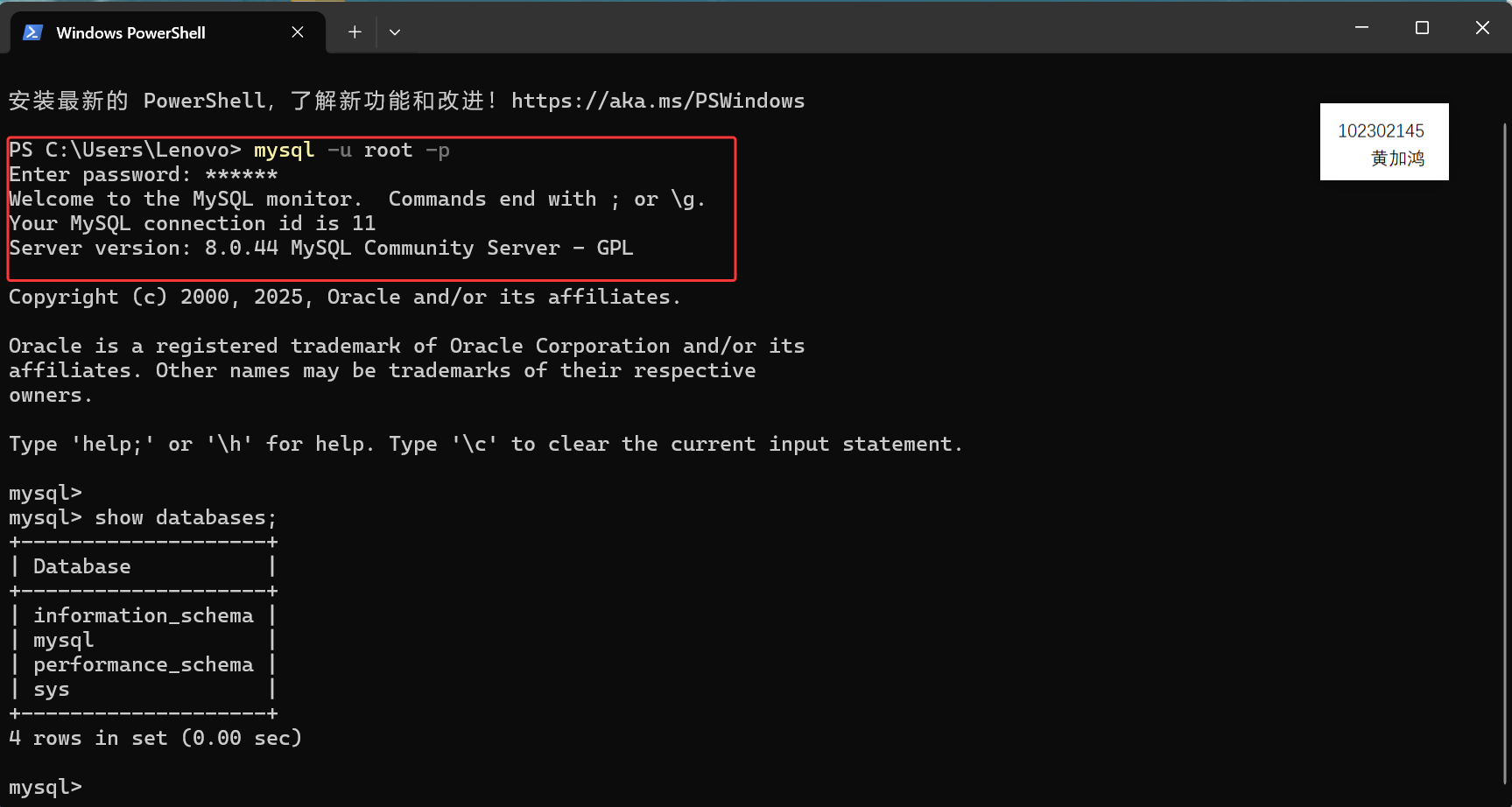
第一步,进入官网下载相应版本的安装包,根据提示安装部署mysql服务端,然后在命令行窗口打开MySQL界面:

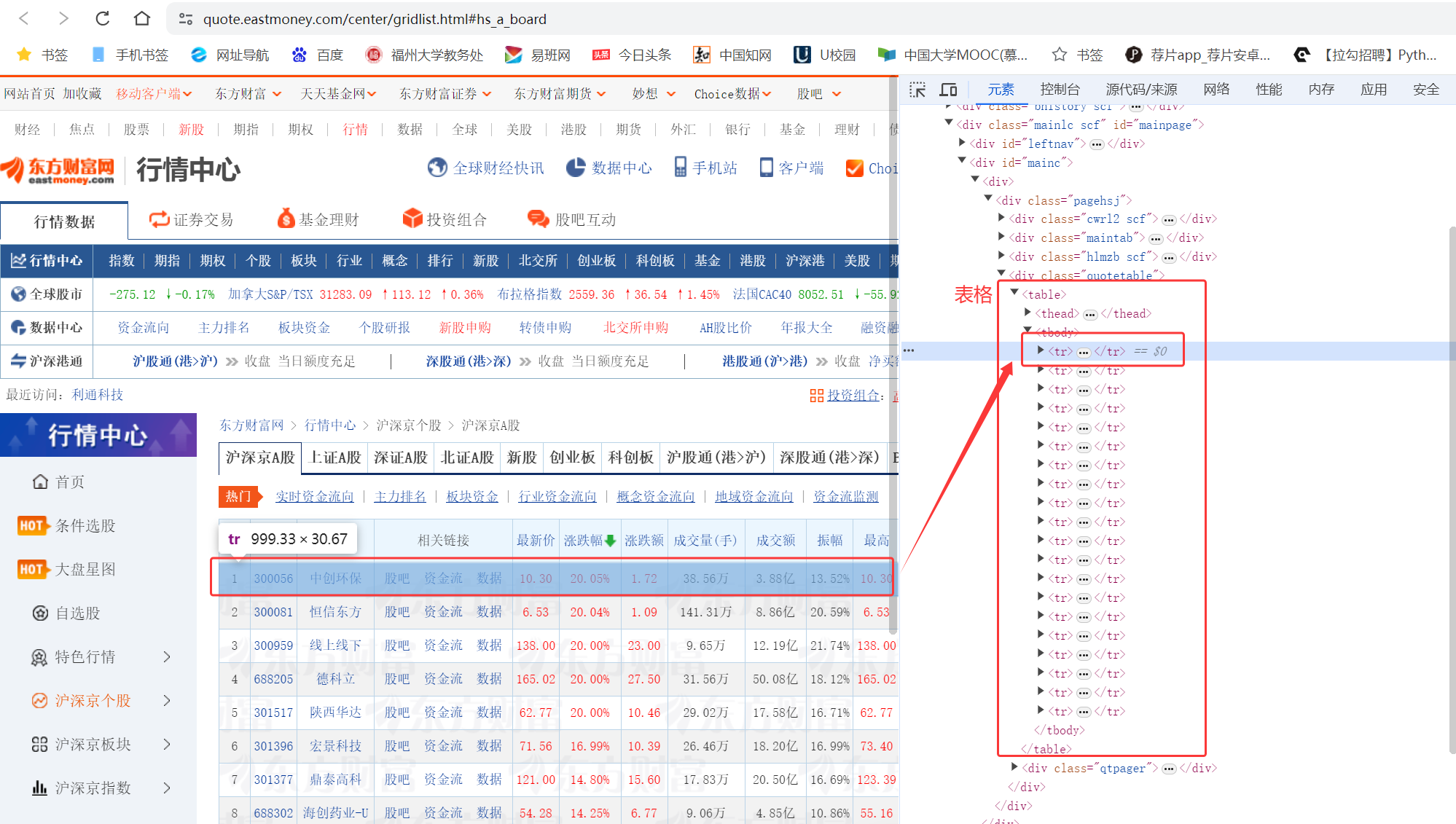
第二步,分析网页,定位要爬取的表格:
第三步,编写程序,用Selenium框架自动爬取数据最后保存到MySQL数据库:
核心代码
配置数据库连接部分:
db_config = {
'host': 'localhost', # 数据库服务器地址
'port': 3306, # MySQL端口
'user': 'root', # 用户名
'password': '232300', # 密码
'database': 'stock_data', # 数据库名
'charset': 'utf8mb4' # 字符编码
}
数据库建表部分:
CREATE TABLE IF NOT EXISTS stock_data (
id INT AUTO_INCREMENT PRIMARY KEY, -- 主键,自增ID
plate_type VARCHAR(20) NOT NULL, -- 板块类型:沪深A股/上证A股/深证A股
serial_number VARCHAR(10), -- 序号
stock_code VARCHAR(20) NOT NULL, -- 股票代码
stock_name VARCHAR(50) NOT NULL, -- 股票名称
latest_price DECIMAL(10, 2), -- 最新报价
change_percent DECIMAL(10, 2), -- 涨跌幅
change_amount DECIMAL(10, 2), -- 涨跌额
volume VARCHAR(50), -- 成交量
turnover VARCHAR(50), -- 成交额
amplitude DECIMAL(10, 2), -- 振幅
high DECIMAL(10, 2), -- 最高
low DECIMAL(10, 2), -- 最低
open_price DECIMAL(10, 2), -- 今开
previous_close DECIMAL(10, 2), -- 昨收
crawl_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 爬取时间
INDEX idx_stock_code (stock_code) -- 股票代码索引,提高查询效率
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 -- 使用InnoDB引擎,支持中文
用Xpath路径:'//*[@id="mainc"]/div/div/div[4]/table/tbody'定位到表格,然后析取表格数据:
def extract_stock_data(self, table, plate_name):
"""从表格提取股票数据"""
stock_data = []
rows = table.find_elements(By.TAG_NAME, "tr") # 获取所有表格行
if len(rows) == 0:
return stock_data
for row in rows:
try:
cells = row.find_elements(By.TAG_NAME, "td") # 获取行中所有单元格
# 构建股票数据字典
data = {
'plate_type': plate_name, # 板块类型
'serial_number': cells[0].text.strip(), # 序号
'stock_code': cells[1].text.strip(), # 股票代码
'stock_name': cells[2].text.strip(), # 股票名称
'latest_price': self.parse_number(cells[4].text.strip()), # 最新报价
'change_percent': self.parse_number(cells[5].text.strip().replace('%', '')), # 涨跌幅
'change_amount': self.parse_number(cells[6].text.strip()), # 涨跌额
'volume': cells[7].text.strip(), # 成交量
'turnover': cells[8].text.strip(), # 成交额
'amplitude': self.parse_number(cells[9].text.strip().replace('%', '')), # 振幅
'high': self.parse_number(cells[10].text.strip()), # 最高
'low': self.parse_number(cells[11].text.strip()), # 最低
'open_price': self.parse_number(cells[12].text.strip()), # 今开
'previous_close': self.parse_number(cells[13].text.strip()), # 昨收
}
# 验证必要字段不为空
if data['stock_code'] and data['stock_name']:
stock_data.append(data)
except Exception:
continue # 跳过解析失败的行
return stock_data
因为要爬三个板块,所以创建一个url列表:
plates = [
('沪深A股', 'https://quote.eastmoney.com/center/gridlist.html#hs_a_board'),
('上证A股', 'https://quote.eastmoney.com/center/gridlist.html#sh_a_board'),
('深证A股', 'https://quote.eastmoney.com/center/gridlist.html#sz_a_board')
]
运行结果
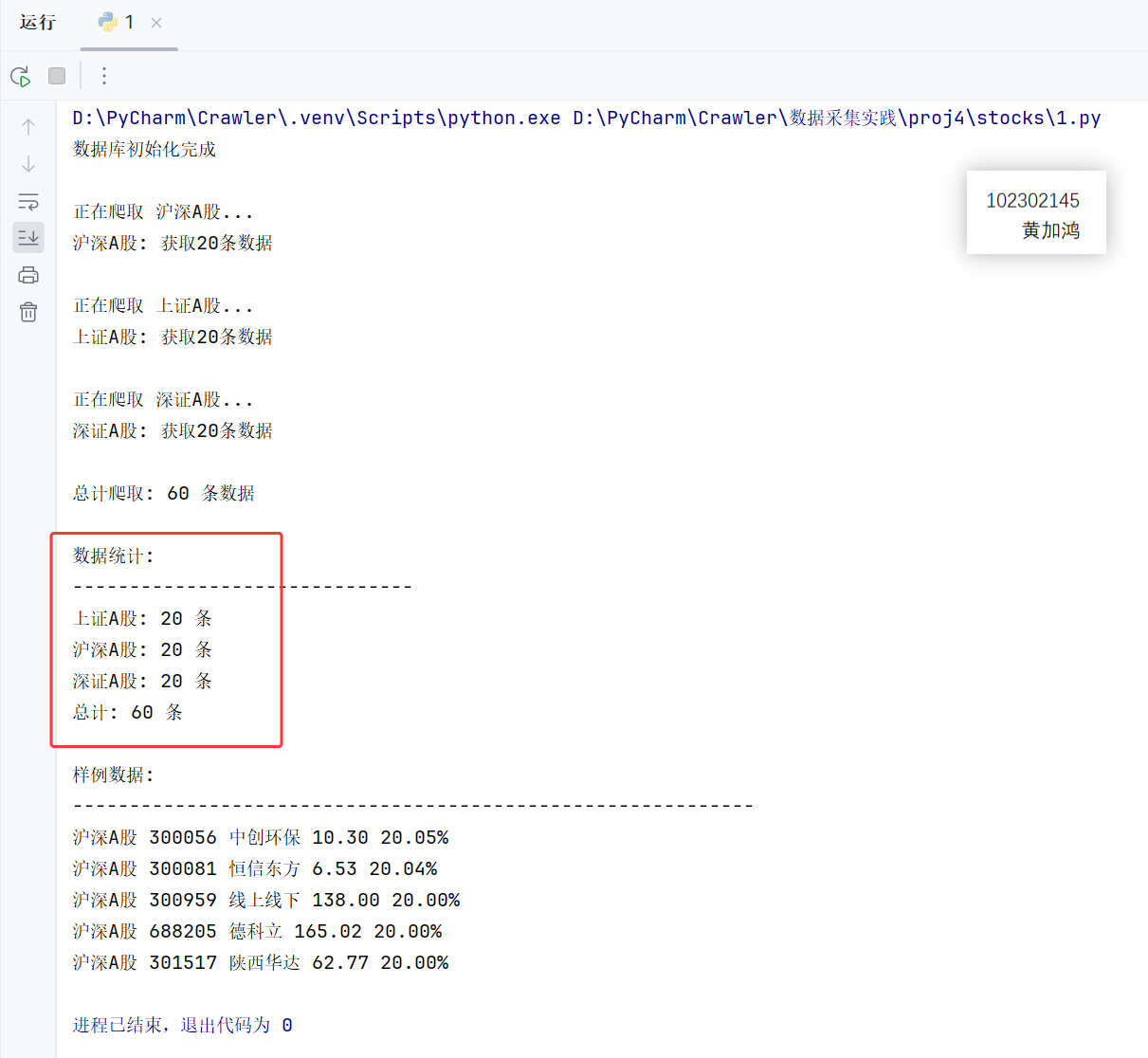
运行程序后,浏览器驱动器打开网页自动爬取数据,程序输出:
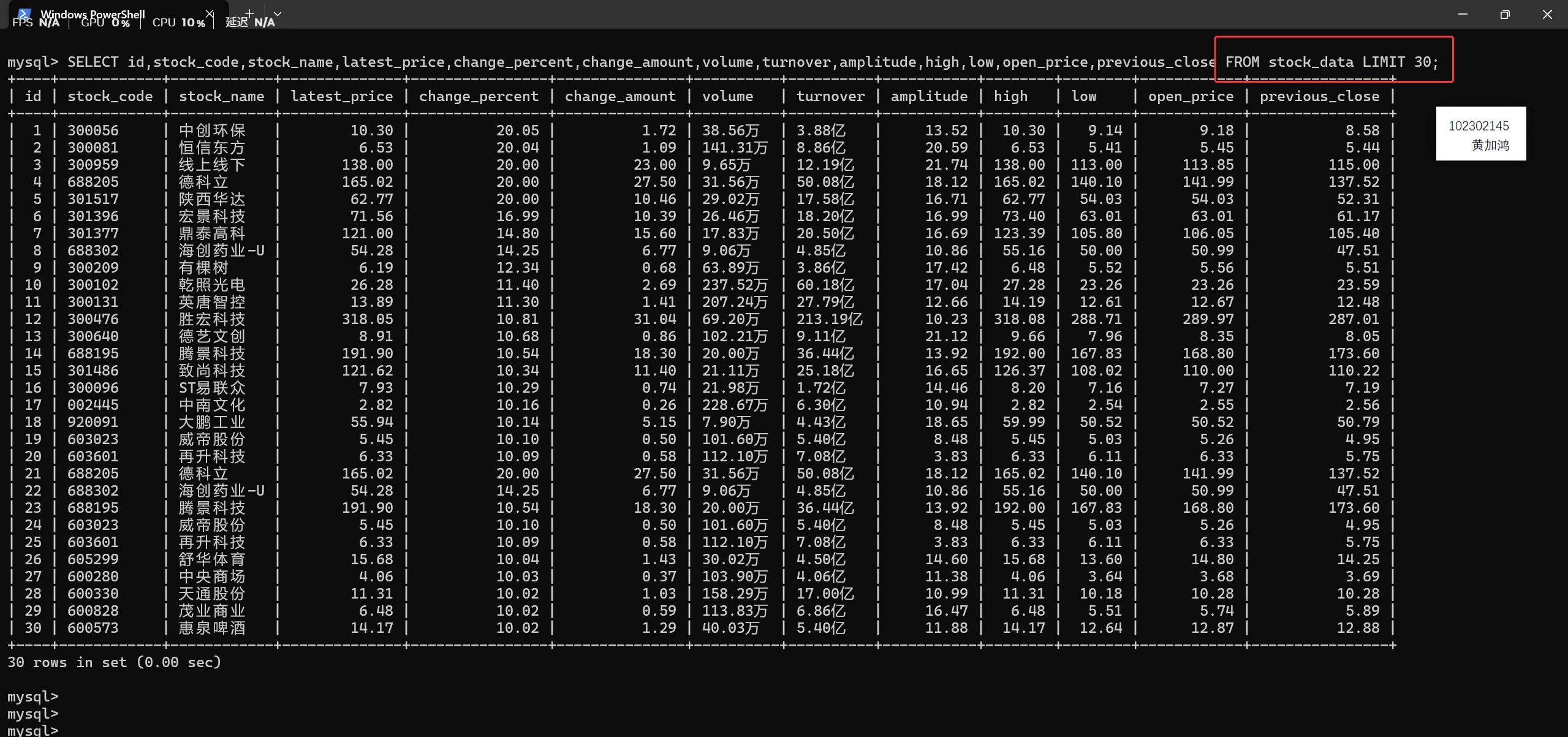
命令行打开MySQL,用查询语句查看表stock_data保存情况:
2)心得体会
学会了本地部署MySQL,以及python程序如何连接MySQL。比起直接调用SQLite库,用MySQL多了个配置连接的步骤,其余的步骤都差不多。我觉得用MySQL存储的好处就是爬完数据之后,再用SQL语句对数据进行查询、更新等其他操作的时候更方便,而且MySQL在各种场景下,比如Web应用、云应用开发时,使用更加广泛。
3)Gitee链接
· https://gitee.com/jh2680513769/2025_crawler_project/blob/master/%E4%BD%9C%E4%B8%9A4/1.py
作业②
1)代码与结果
目标:熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容;用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
核心代码
第一步,模拟登录MOOC,打开网页中国大学MOOC,点击右上角按钮“登录 | 注册”,然后会跳转到登录的界面:
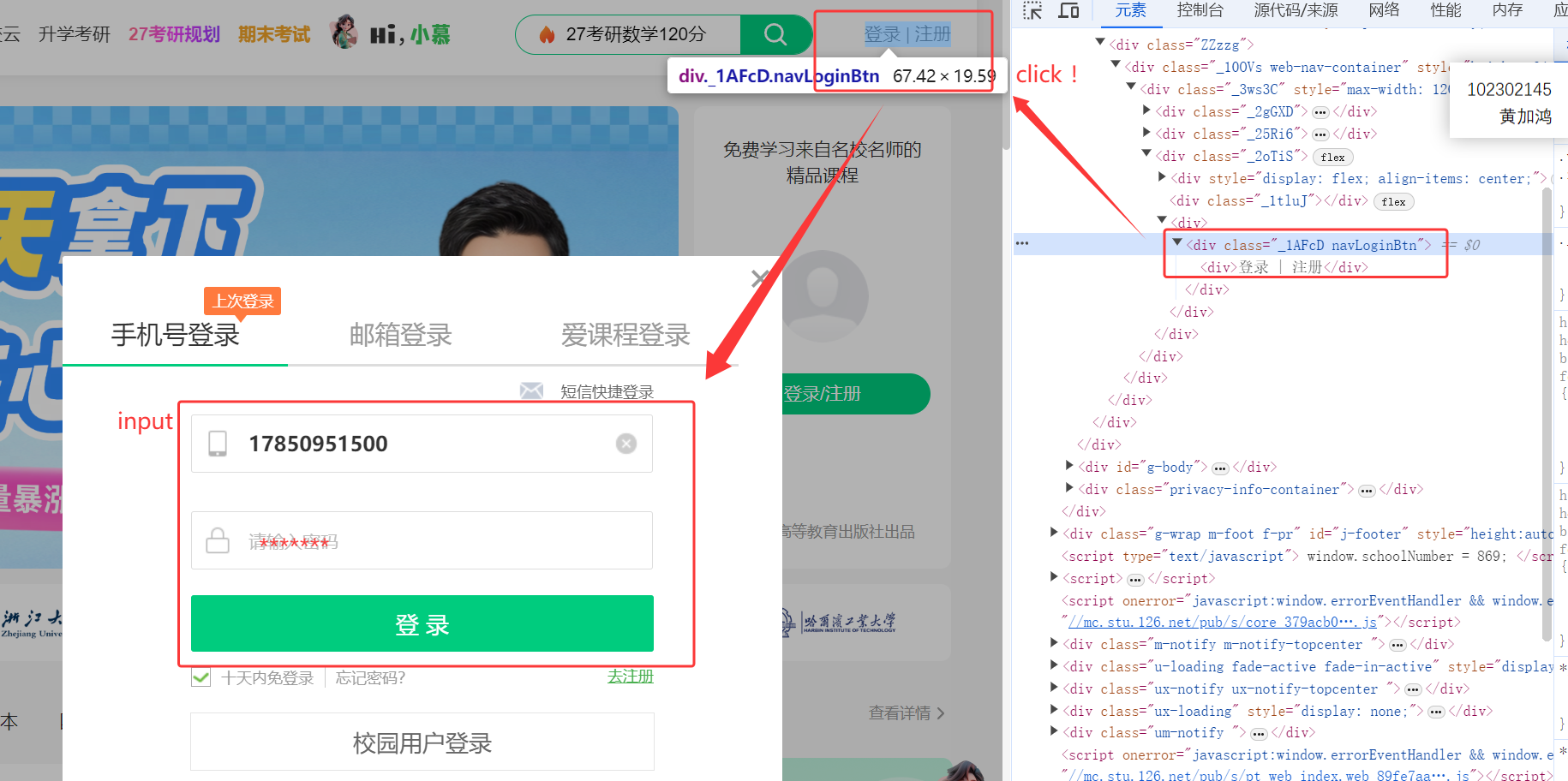
我自己用XPath定位的方式去输入登录信息会发现查找不到,也就无法登录。试过几次行不通之后,去问ai给出的解决方法是使用iframe来处理登录框:
def login_mooc(self, driver):
"""登录MOOC网站 - 使用iframe处理登录框"""
try:
print("正在登录...")
driver.get("https://www.icourse163.org")
time.sleep(3)
# 点击登录按钮
login_btn = driver.find_element(By.XPATH, '//*[@id="web-nav-container"]/div/div/div/div[3]/div[3]/div/div')
login_btn.click()
time.sleep(2)
# 切换到iframe(登录框在iframe中)
frame = driver.find_element(By.XPATH, '//*[@id="j-ursContainer-0"]/iframe')
driver.switch_to.frame(frame)
time.sleep(1)
# 输入手机号和密码
account_input = driver.find_element(By.ID, 'phoneipt')
account_input.send_keys("17850951500")
time.sleep(1)
password_input = driver.find_element(By.XPATH,
'/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]')
password_input.send_keys("哈哈哈哈哈")
time.sleep(1)
# 点击登录按钮
login_button = driver.find_element(By.XPATH, '//*[@id="submitBtn"]')
login_button.click()
# 切换回主文档
driver.switch_to.default_content()
# 等待登录完成
time.sleep(5)
print("登录完成")
return True
except Exception as e:
print(f"登录失败: {e}")
return False
这样处理之后就可以正常登录了,登录之后点击“我的课程”进入个人课程列表的页面,然后就是寻找爬取的对象,在这个页面还不能直接爬到课程信息,所以需要找到每个课程的课程介绍的url,以我的课程页面里“大学生职业发展与就业指导”为例:
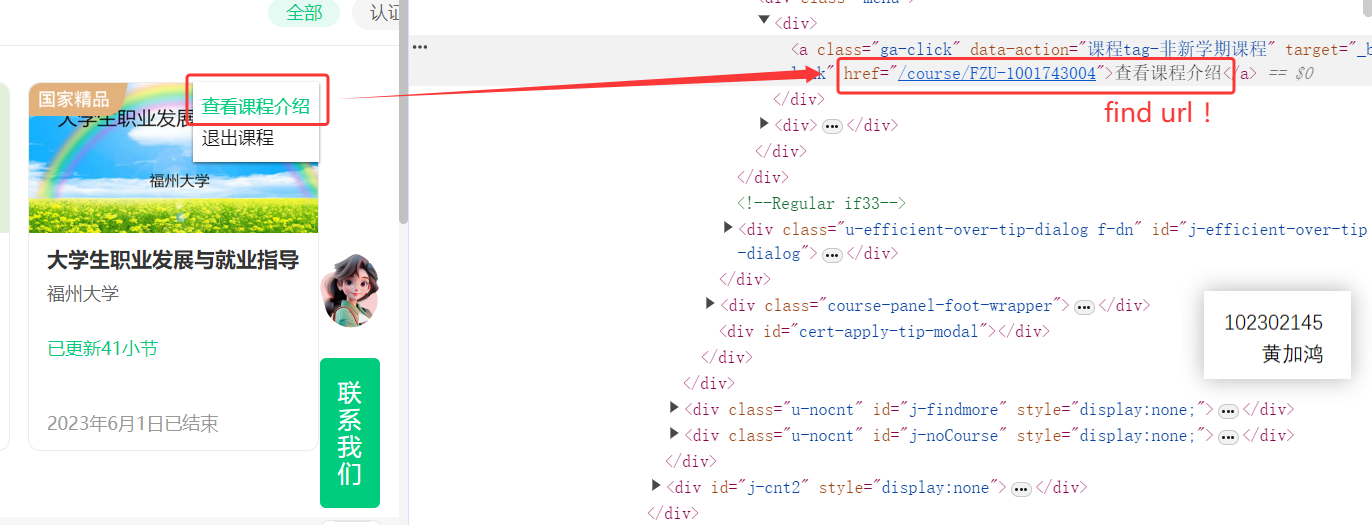
def go_to_my_courses(self, driver):
"""进入我的课程页面"""
try:
print("进入我的课程...")
# 点击"我的课程"按钮
my_courses_btn = driver.find_element(By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[4]/div')
my_courses_btn.click()
time.sleep(5)
return True
except Exception as e:
print(f"进入我的课程失败: {e}")
return False
第二步,提取信息,找到课程介绍的url之后再拼接出完整的url并进行访问,根据所需信息进行爬取:
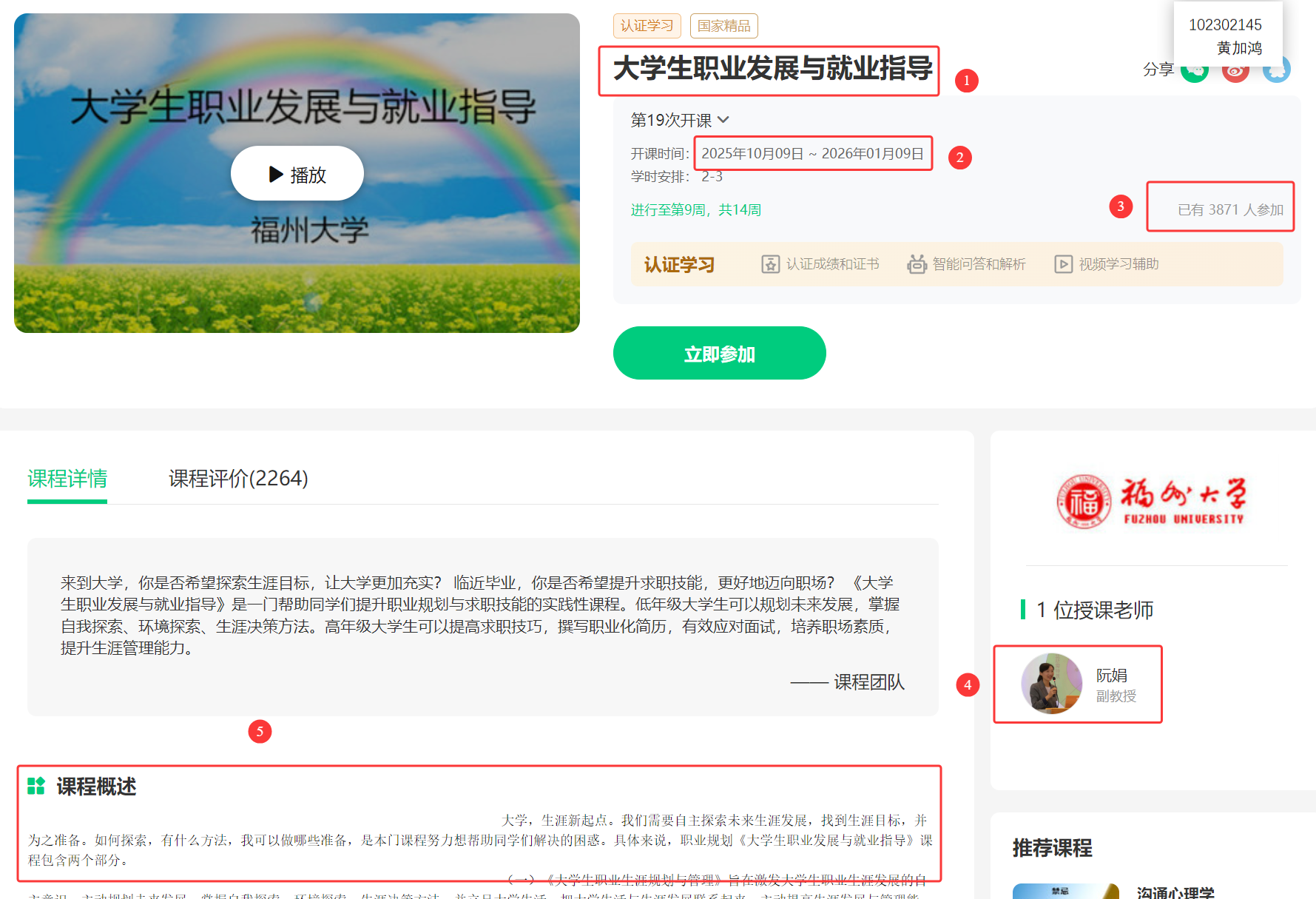
# 1. 课程名称
try:
course_name_element = driver.find_element(By.CSS_SELECTOR, '.course-title.f-ib.f-vam')
course_info['course_name'] = course_name_element.text.strip()
except:
course_info['course_name'] = "未知课程"
# 2. 开课时间
try:
time_element = driver.find_element(By.CSS_SELECTOR,
'.course-enroll-info_course-info_term-info_term-time span:nth-child(2)')
course_info['course_progress'] = time_element.text.strip()
except:
course_info['course_progress'] = "未提供"
# 3. 参与人数
try:
participants_element = driver.find_element(By.CSS_SELECTOR, '.count')
course_info['participants'] = participants_element.text.strip()
except:
course_info['participants'] = "0人"
# 4. 授课教师
teachers = self.extract_teachers(driver)
if teachers:
course_info['main_teacher'] = teachers[0] # 第一个教师作为主讲教师
course_info['team_members'] = "、".join(teachers) # 所有教师用顿号分隔
else:
course_info['main_teacher'] = "未知教师"
course_info['team_members'] = ""
# 5. 课程概述
try:
brief_element = driver.find_element(By.XPATH, '//*[@id="content-section"]/div[4]/div')
course_info['course_brief'] = brief_element.text.strip()[:300] # 限制长度
except:
course_info['course_brief'] = "暂无概述"
# 6. 学校名称(从URL中提取)
if '/course/' in course_url:
parts = course_url.split('/course/')
if len(parts) > 1:
school_code = parts[1].split('-')[0] # 提取学校代码,如FZU
course_info['college_name'] = school_code
else:
course_info['college_name'] = "未知"
else:
course_info['college_name'] = "未知"
# 7. 课程号(从URL中提取)
if '/course/' in course_url:
course_id = course_url.split('/course/')[1].split('?')[0]
course_info['course_id'] = course_id
else:
course_info['course_id'] = "未知"
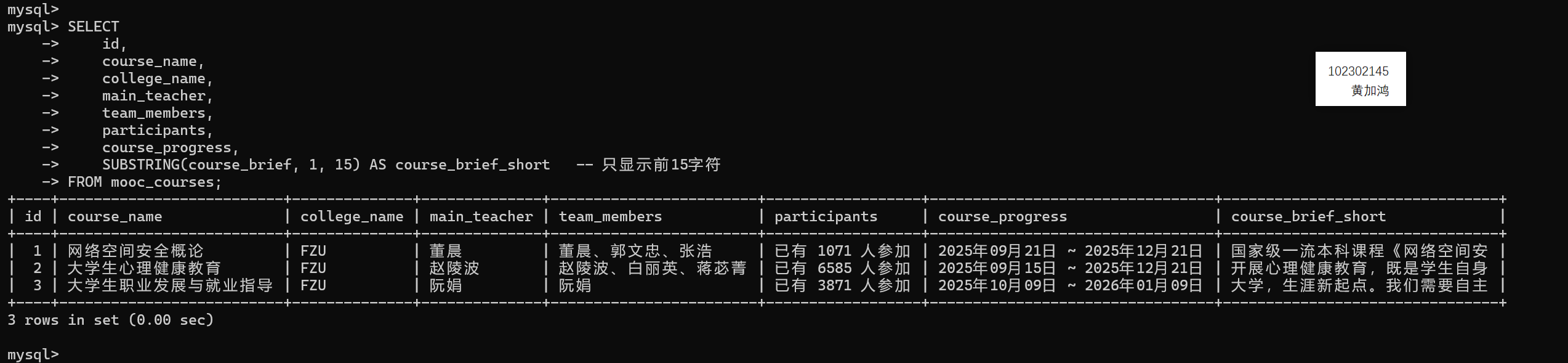
第三步,把爬取的数据存入数据库,数据库mooc_data中构建的表的结构如下:
CREATE TABLE IF NOT EXISTS mooc_courses (
id INT AUTO_INCREMENT PRIMARY KEY,
course_id VARCHAR(50), -- 课程号
course_name VARCHAR(200), -- 课程名称
college_name VARCHAR(100), -- 学校名称
main_teacher VARCHAR(100), -- 主讲教师
team_members TEXT, -- 团队成员
participants VARCHAR(50), -- 参加人数
course_progress VARCHAR(100), -- 开课时间
course_brief TEXT, -- 课程简介
crawl_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- 爬取时间
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
运行结果
运行程序,查看输出:
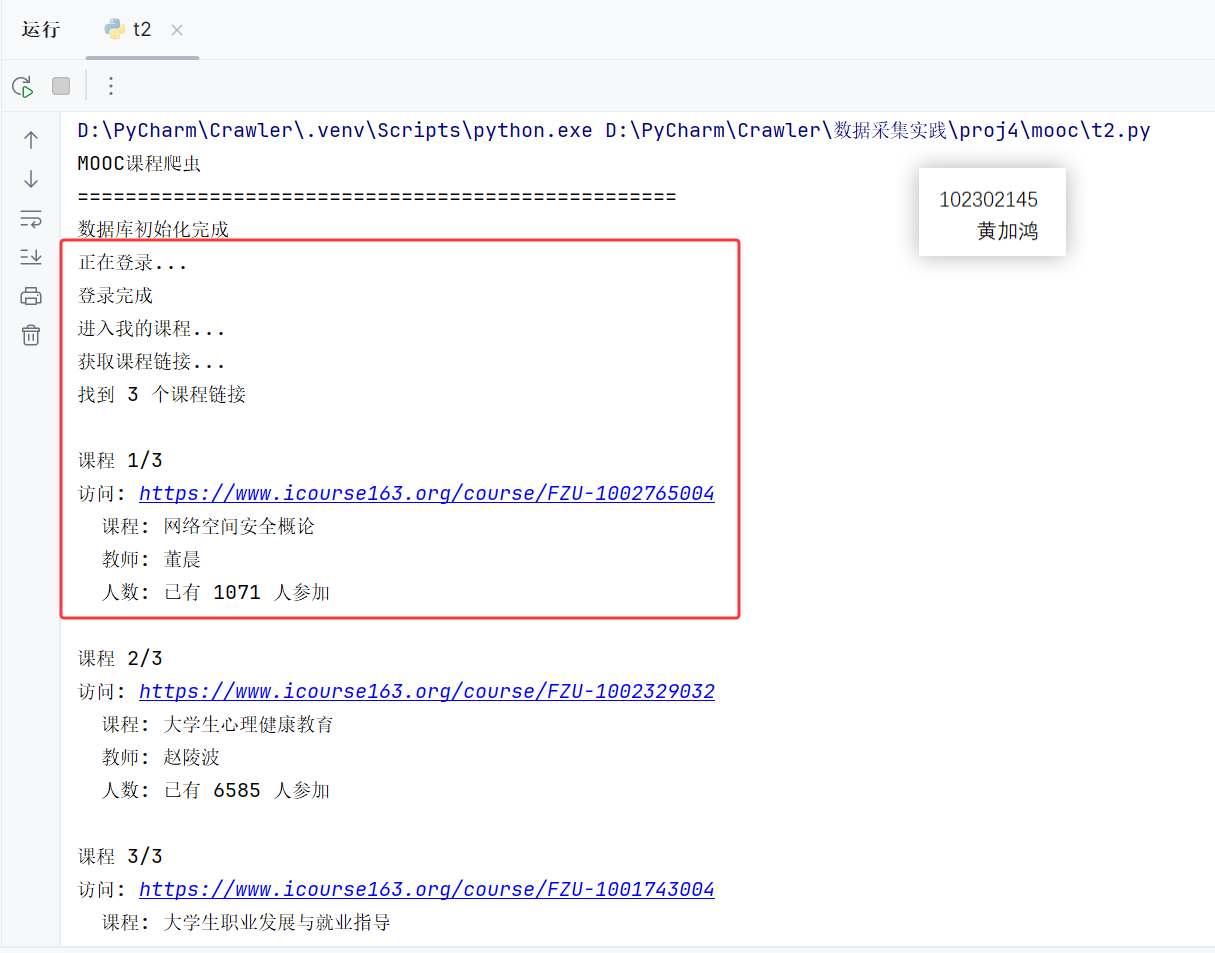
使用查询语句在MySQL里面查询数据保存情况:
2)心得体会
模拟登录的环节比较麻烦,中国MOOC网的登录框嵌套在iframe中,需要先切换iframe才能操作登录表单元素,并且密码输入框的ID是动态生成的(如auto-id-1765316504383),直接使用固定ID会发现一直找不到位置。通过这次实践,我掌握了Selenium处理iframe、动态元素、等待策略的方法,学会了分析网站结构和交互逻辑的思维方式。
3)Gitee链接
· https://gitee.com/jh2680513769/2025_crawler_project/blob/master/%E4%BD%9C%E4%B8%9A4/2.py
作业③
1)代码与结果
环境搭建:
任务一:开通MapReduce服务

实时分析开发实战:
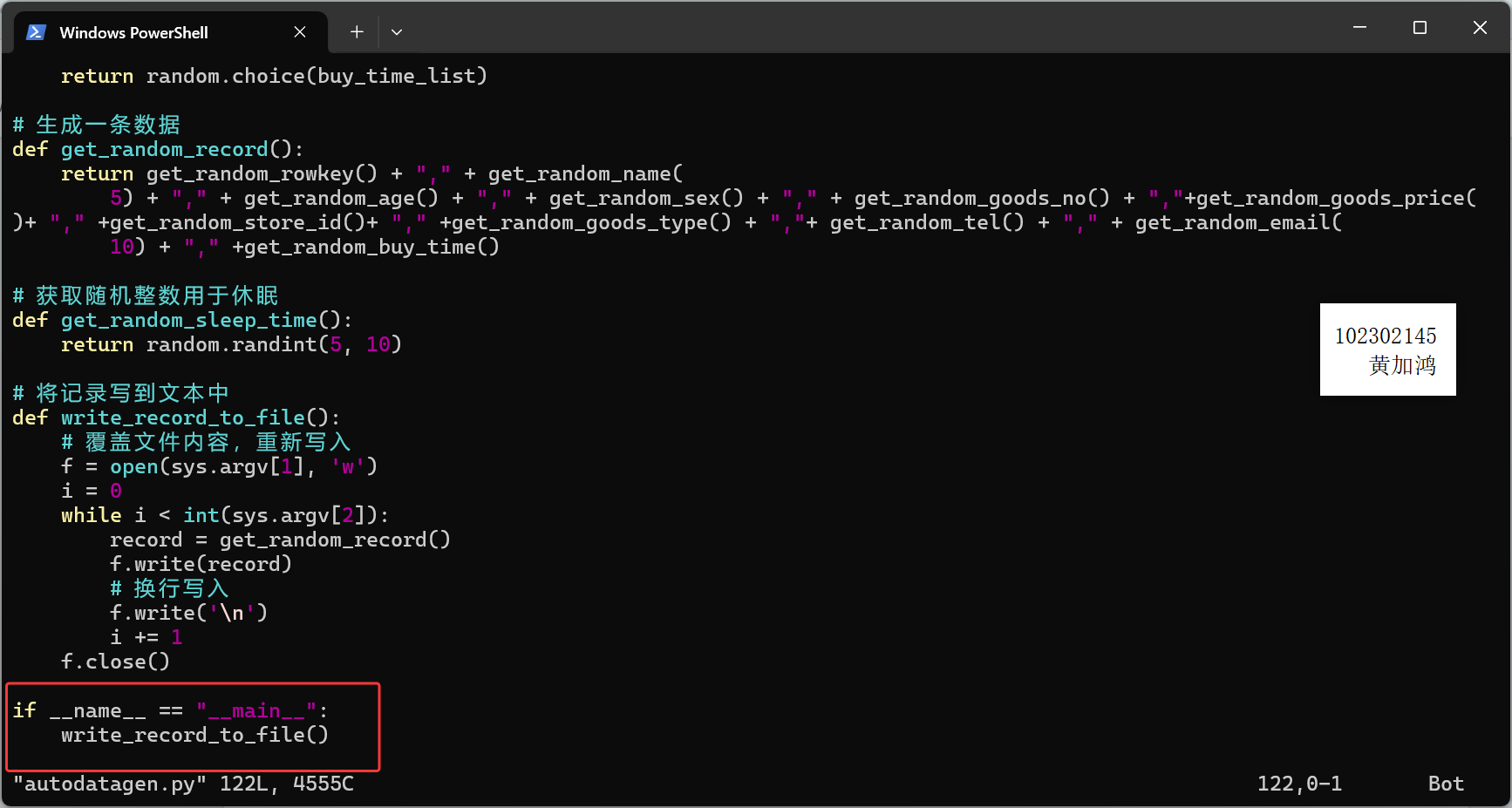
任务一:Python脚本生成测试数据
编写python脚本
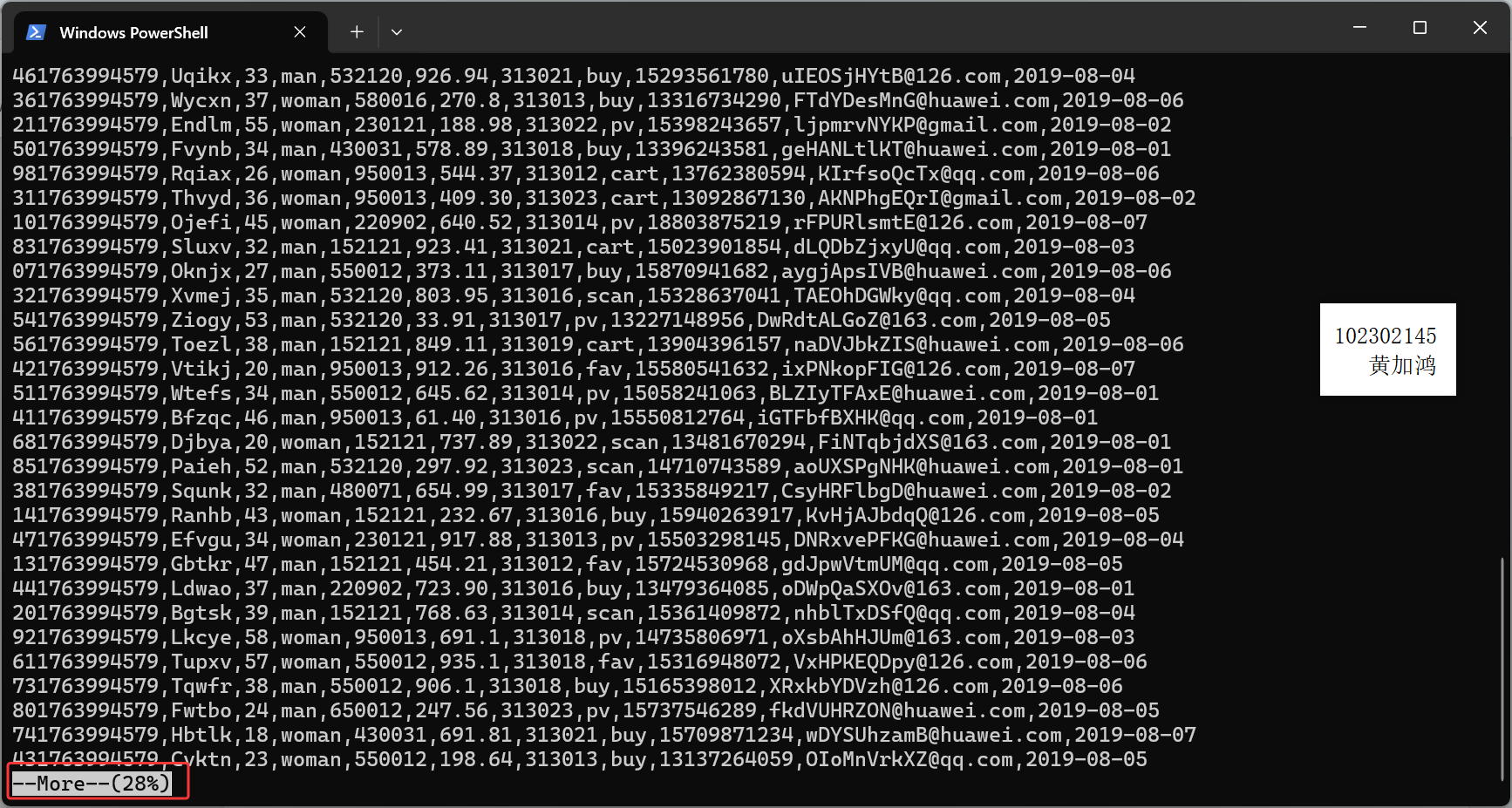
执行脚本测试
任务二:配置Kafka
下载客户端
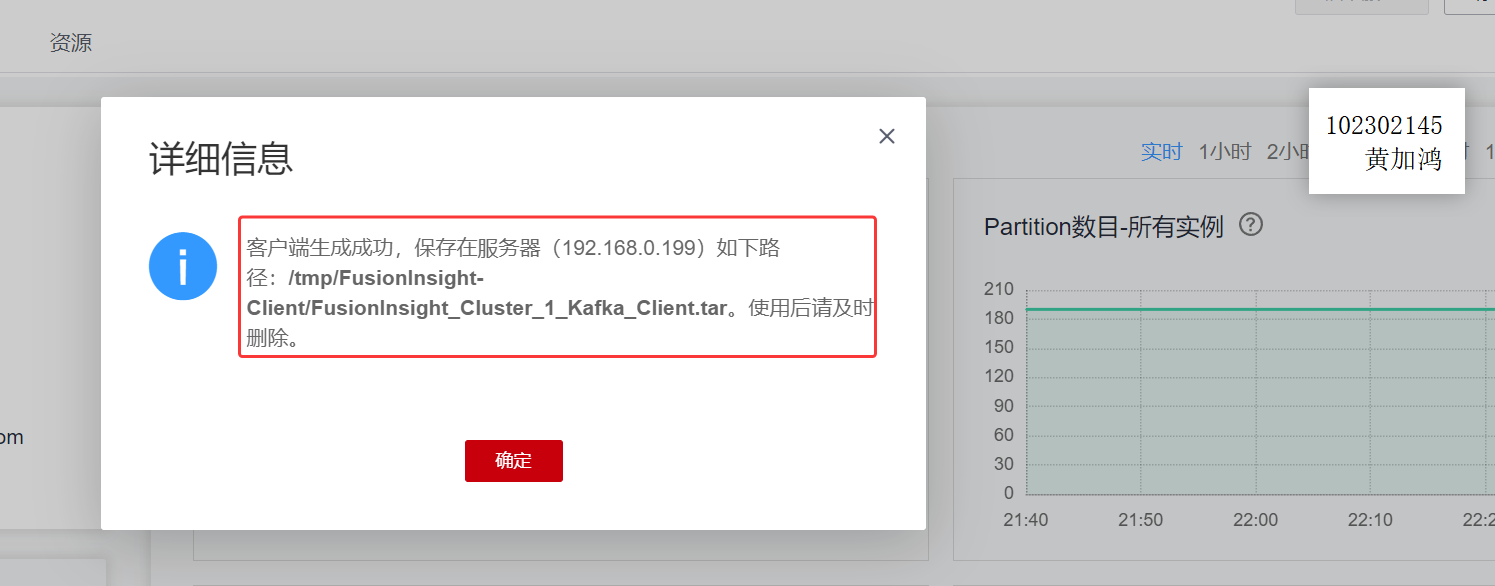
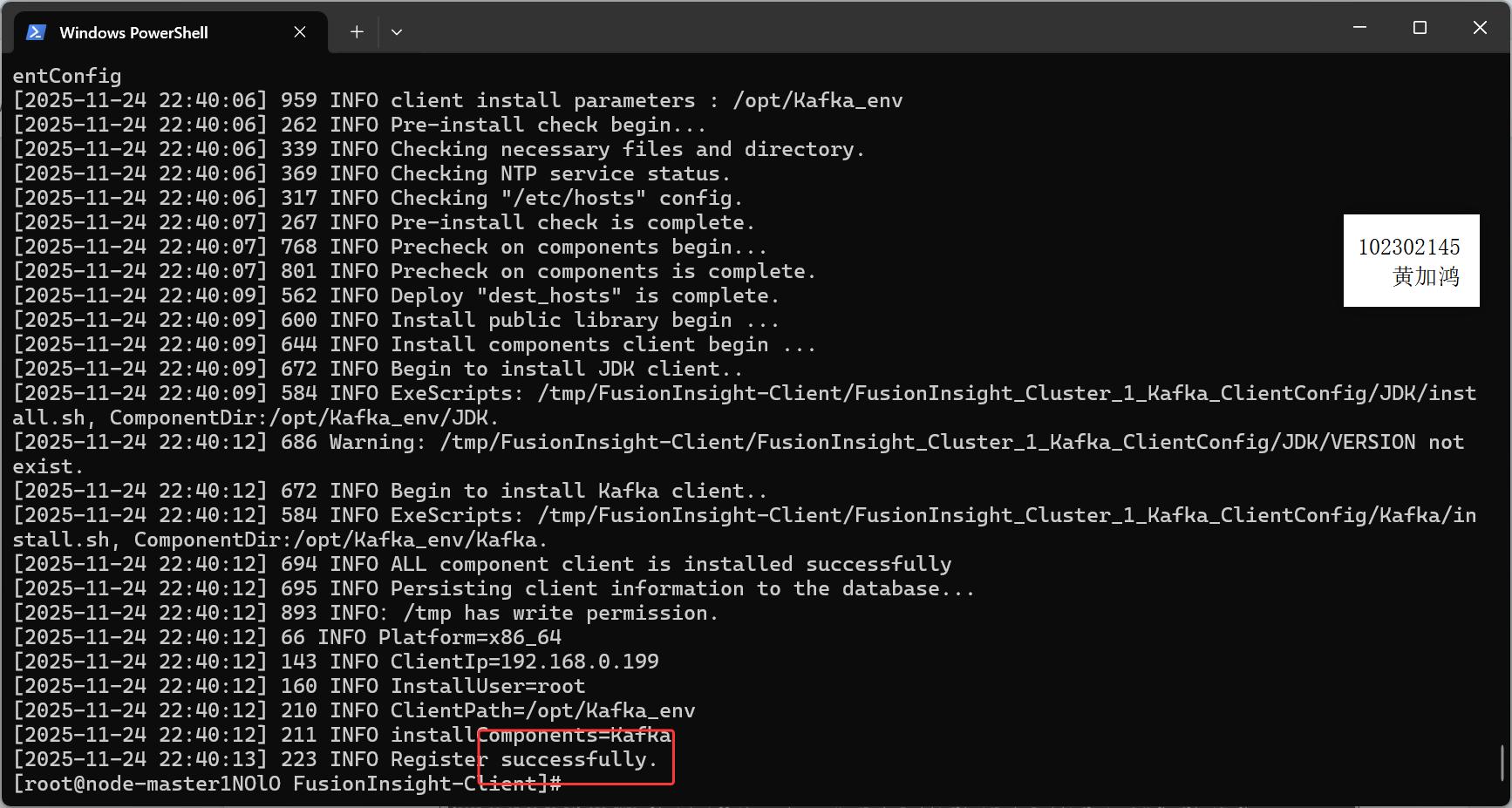
安装Kafka
任务三: 安装Flume客户端
下载客户端
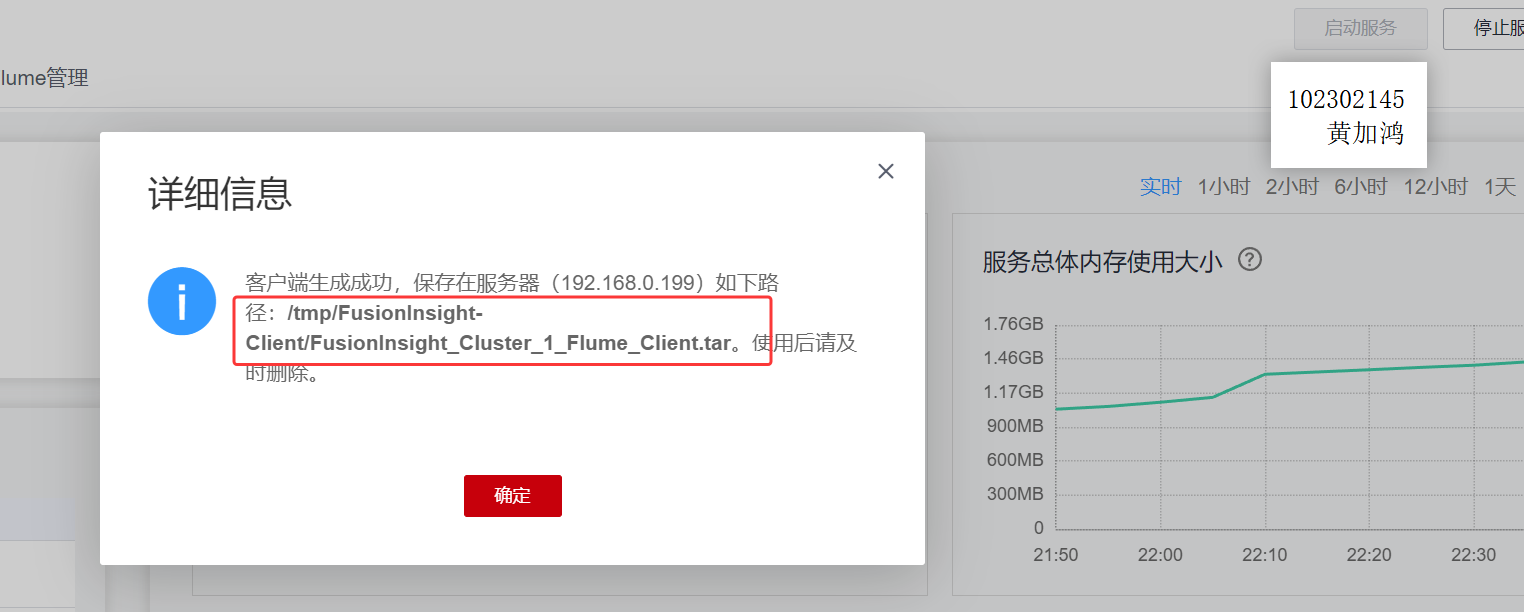
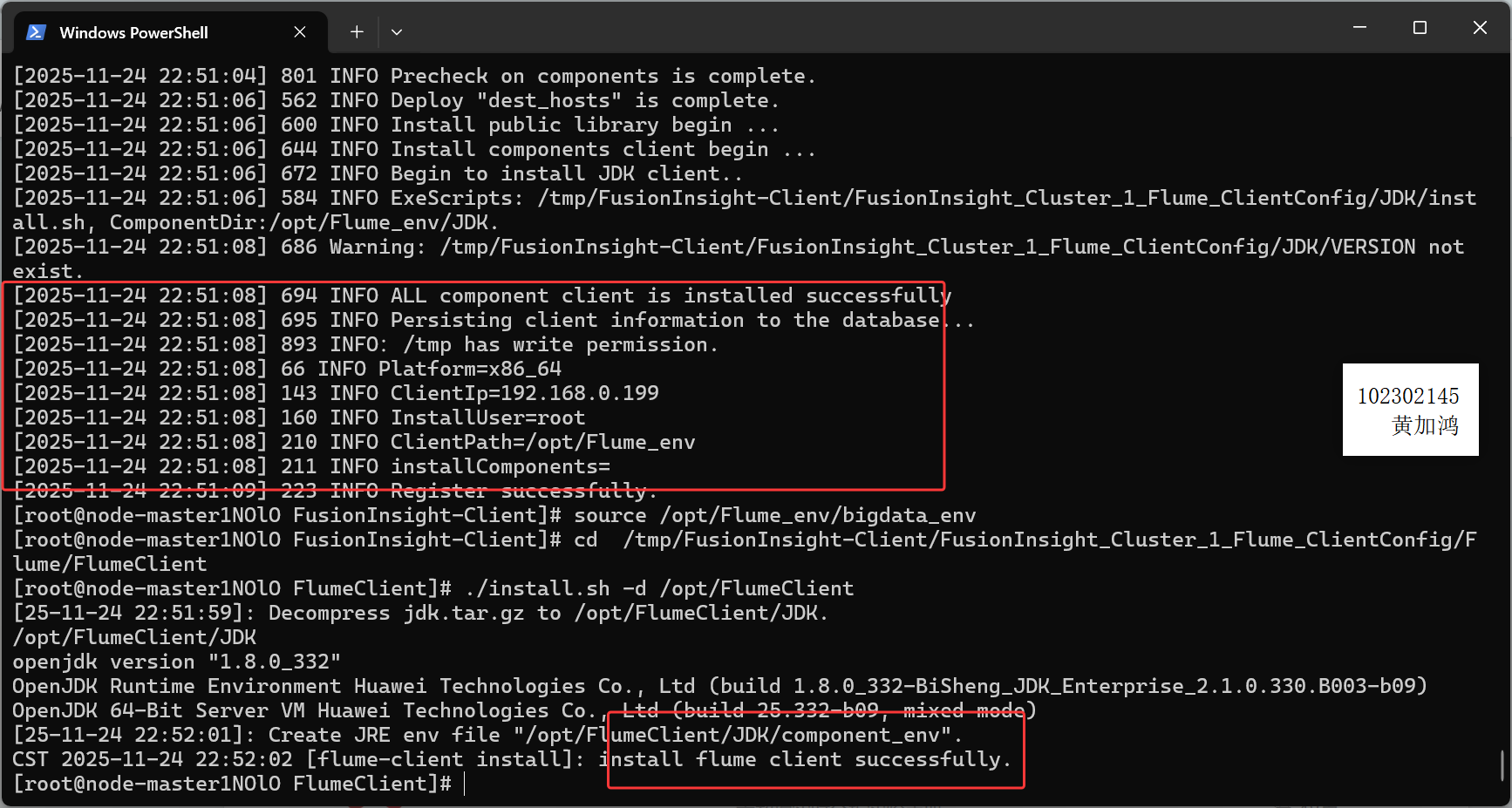
安装flume
任务四:配置Flume采集数据
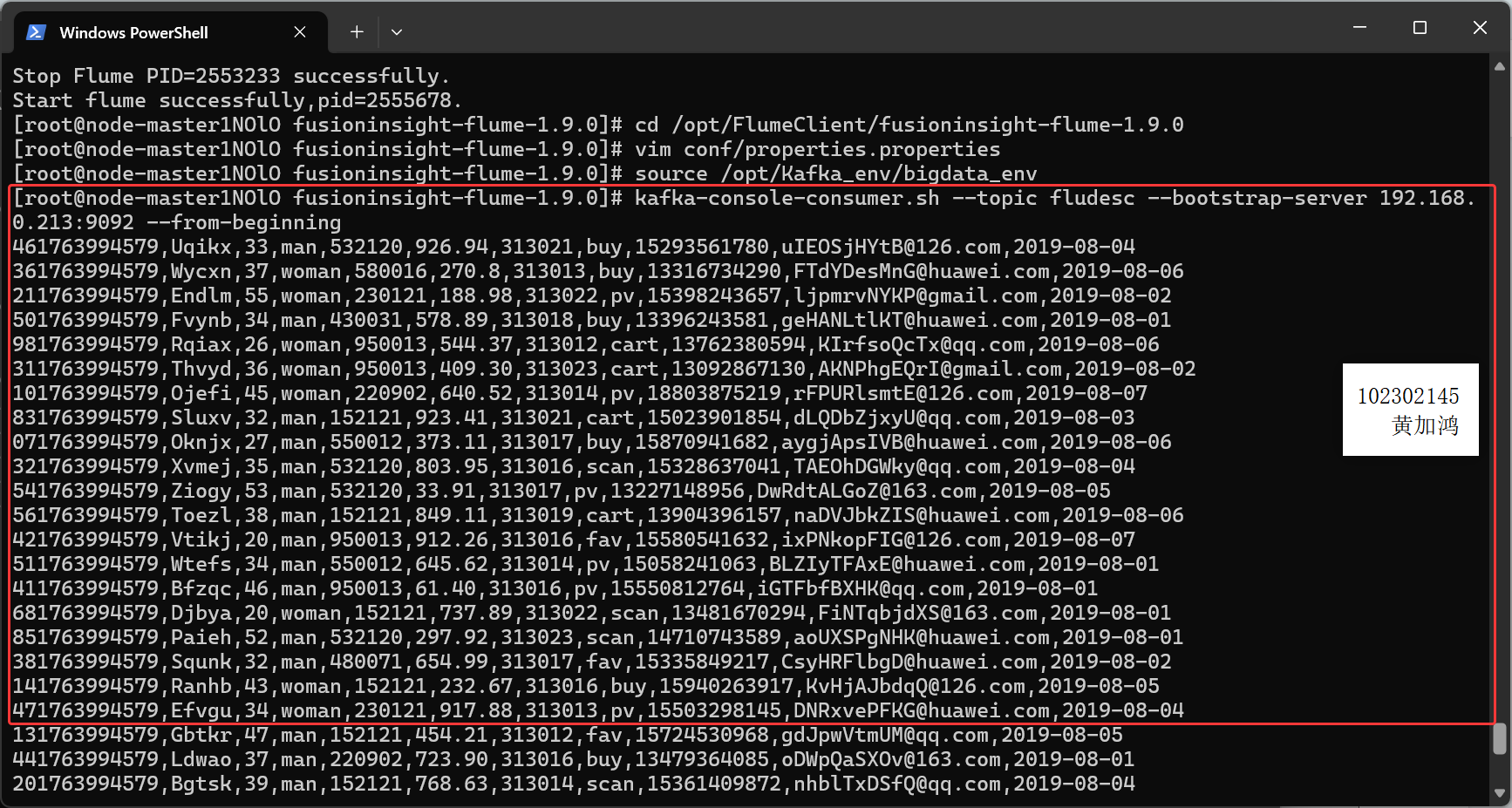
2)心得体会
通过Flume日志采集实验,我掌握了大数据实时处理流程。从数据生成到Kafka消息队列,再到Flume采集传输,理解了数据流动的完整链路。实践让我深刻体会到配置文件的严谨性和组件协作的重要性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号