

Es图形化软件使用之ElasticSearch-head、Kibana,Elasticsearch之-倒排索引操作、映射管理、文档增删改查
今日内容概要
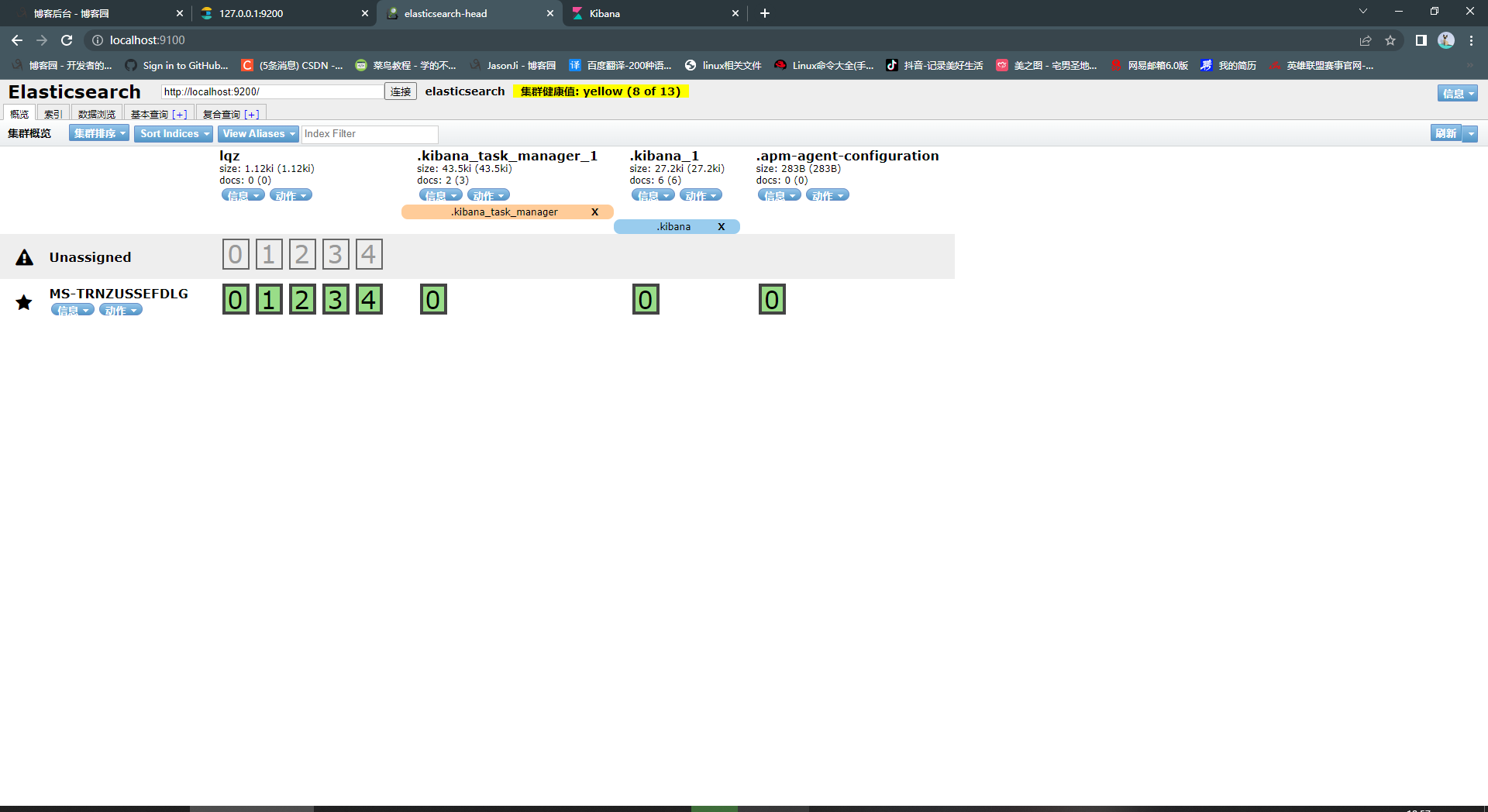
- ElasticSearch之-ElasticSearch-head
- ElasticSearch之-安装Kibana
- Elasticsearch之-倒排索引
- Elasticsearch之-索引操作
- Elasticsearch之-映射管理
- Elasticsearch的文档增删查改(CURD)
内容详细
1、ElasticSearch之-ElasticSearch-head
# 本质都是 c s 架构的软件
# es:web服务端封装了一些restful接口 --b s架构
-docker
# mysql,redis---》自定制的 tcp 协议 --b s架构
# 服务端装好了
# 装客户端
-浏览器--->只能发get请求
-postman
-ElasticSearch-head 第三方用nodejs写的的客户端
-Kibana 官方提供的
# head的安装
# 地址:https://github.com/mobz/elasticsearch-head,可以用git下载,或者下载zip
# 解压后切换到目录下
cd elasticsearch-head-master
# 通过npm安装依赖
npm install
# 启动
npm run start
#在浏览器里打开
http://localhost:9100/
# 使用ElasticSearch-head连接服务端
-es是一个web后端
-ElasticSearch-head在跑在一个端口上,会有跨域问题
-解决跨域问题---》es的配置文件中加入允许跨域
# 跨域的配置---》es 的 config目录下的 elasticsearch.yml 添加下面两句:
http.cors.enabled: true
http.cors.allow-origin: "*"
2、ElasticSearch之-安装Kibana
# 可视化客户端---》在浏览器中访问
# 重点:
-es版本需要跟Kibana完全一一对应
# 使用步骤
-官方下载,解压
https://www.elastic.co/cn/downloads/past-releases/kibana-7-5-0
-配置Kibana---》指定连接的es服务端是什么
E:\es\kibana-7.5.0-windows-x86_64\config\kibana.yml:
server.port: 5601
server.host: "127.0.0.1"
server.name: lqz
elasticsearch.hosts: ["http://localhost:9200/"]
-启动即可
cd到 安装路径的 bin路径 启动: ./kibana
# 会在es中创建一些索引,我们不需要管,也不要删掉
# head 用来看es的数据
# kibana 增删查改数据
3、Elasticsearch之-倒排索引
# 面试es重点:倒排索引 keywords和text区别
keyword不分词,直接建索引
text要分词,再建索引
# 倒排索引:通过关键字建立索引查询文档,存的时候对关键字建立索引
文章id---》文章内容 ---》正向索引
关键词1
关键词2 ---》文章内容1,文章内容2---》倒排索引
关键词3
# 总结
- 反向索引又叫倒排索引,是根据文章内容中的关键字建立索引
- 搜索引擎原理就是建立反向索引
- Elasticsearch 在 Lucene 的基础上进行封装,实现了分布式搜索引擎
- Elasticsearch 中的索引、类型和文档的概念比较重要,类似于 MySQL 中的数据库、表和行
- Elasticsearch 也是 Master-slave 架构,也实现了数据的分片和备份
- Elasticsearch 一个典型应用就是 ELK 日志分析系统
4、Elasticsearch之-索引操作(增删改查)
# 索引对等 mysql的数据库
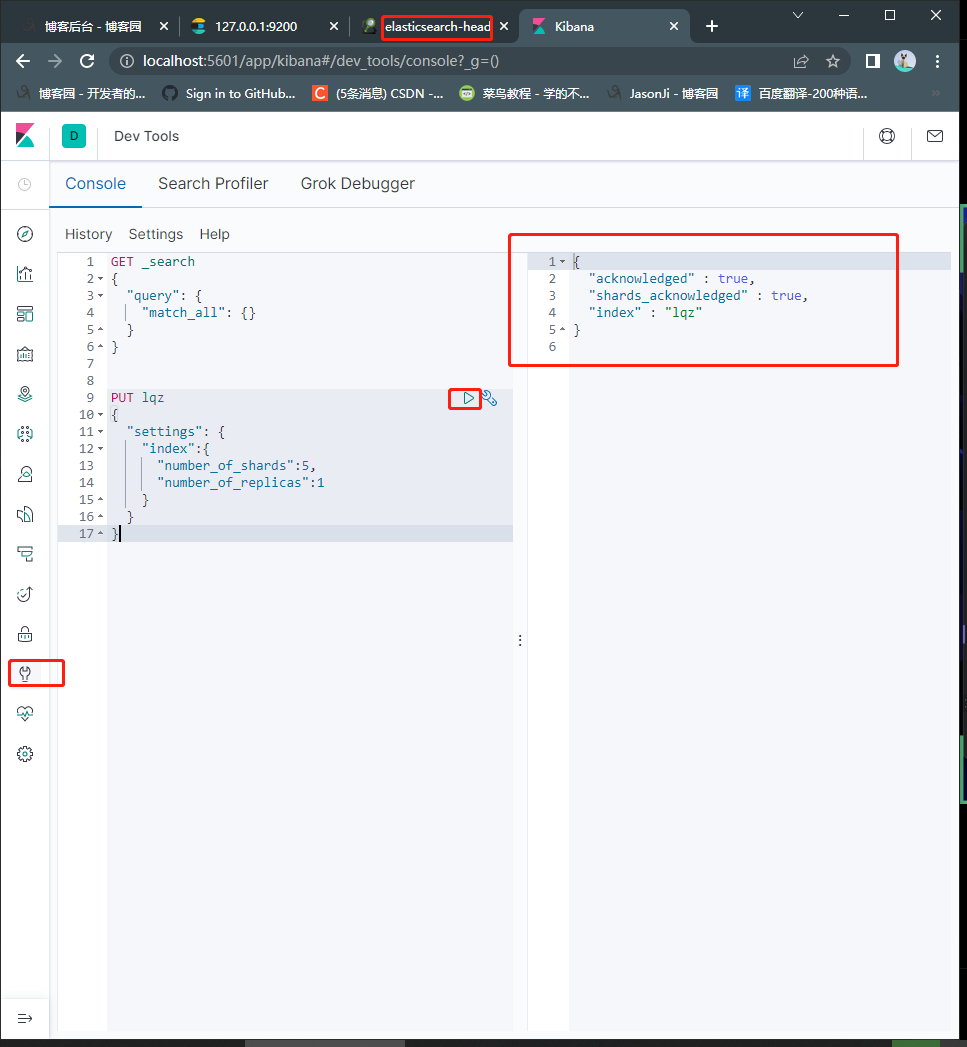
### 新增索引 建立一个lqz索引,有5个分片,每个分片一个副本
PUT lqz
{
"settings": {
"index":{
"number_of_shards":5,
"number_of_replicas":1
}
}
}
### 查看索引
# 获取lqz2索引的配置信息
GET lqz/_settings
# 获取所有索引的配置信息
GET _all/_settings
# 同上
GET _settings
# 获取lqz和lqz2索引的配置信息
GET lqz,lqz2/_settings
### 修改索引 (一般不改)
PUT lqz/_settings
{
"number_of_replicas": 2
}
### 删除索引
DELETE lqz
5、Elasticsearch之-映射管理
# 等同于原来 mysql中建表语句
# es 6.x之前,一个索引下可以有多个类型 --->一个库下可以有多个表
# 6.x 可以使用多个类型,但不能创建了
# es 6.x以后,一个索引下只能有一个类型 --->一个库下只能有一个表
# 在es中,索引没有,类型没有,可以直接插入文档--》插入文档后,自动创建索引和类型
# mysql必须先建库,再建表,再插入数据
##### 创建类型
# 6.x之前的建立类型
PUT books # 给books索引,建立一个类型book类型,无论索引是否存在
{
"mappings": {
"book":{
"properties":{
"title":{
"type":"text"
},
"price":{
"type":"integer"
},
"addr":{
"type":"keyword"
},
"company":{
"properties":{
"name":{"type":"text"},
"company_addr":{"type":"text"},
"employee_count":{"type":"integer"}
}
},
"publish_date":{"type":"date","format":"yyy-MM-dd"}
}
}
}
}
# 6.x以后的建立类型-->不能建多个类型了,不需要指定类型,默认叫 _doc
PUT books
{
"mappings": {
"properties":{
"title":{
"type":"text"
},
"price":{
"type":"integer"
},
"addr":{
"type":"keyword"
},
"company":{
"properties":{
"name":{"type":"text"},
"company_addr":{"type":"text"},
"employee_count":{"type":"integer"}
}
},
"publish_date":{"type":"date","format":"yyy-MM-dd"}
}
}
}
# python 没有基础数据类型---》对象 ---》整形可以无限长
# 字段类型 字段数据类型
string类型:text,keyword
数字类型:byte(int8->一个字节),short(int16->2个字节),integer(int32->4个字节),long(int64-->8个字节),float(float32),double(float64)
日期类型:data
布尔类型:boolean
binary类型:binary
复杂类型:object(实体,对象),nested(列表)
geo类型:geo-point,geo-shape(地理位置)
专业类型:ip,competion(搜索建议)
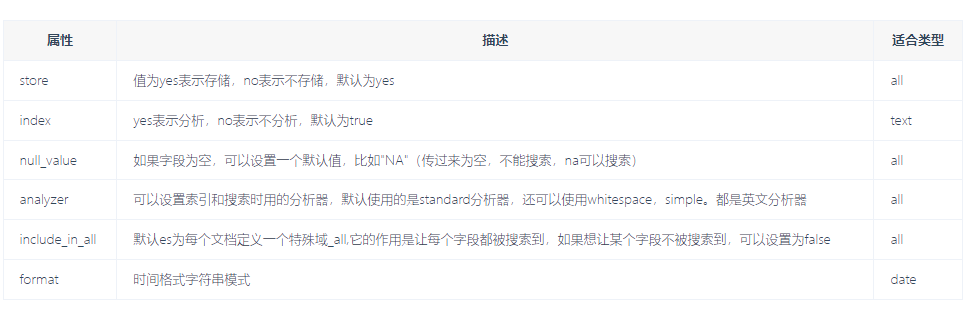
# 字段参数\映射参数---》字段有参数
属性 描述 适合类型
store 值为yes表示存储,no表示不存储,默认为yes all
index yes表示分析,no表示不分析,默认为true text
null_value 如果字段为空,可以设置一个默认值,比如"NA"(传过来为空,不能搜索,na可以搜索) all
analyzer 可以设置索引和搜索时用的分析器,默认使用的是standard分析器,还可以使用whitespace,simple。都是英文分析器 all
include_in_all 默认es为每个文档定义一个特殊域_all,它的作用是让每个字段都被搜索到,如果想让某个字段不被搜索到,可以设置为false all
format 时间格式字符串模式 date
###### 查看映射 mapping 类型
# 查看books索引的mapping
GET books/_mapping
# 获取所有的mapping
GET _all/_mapping
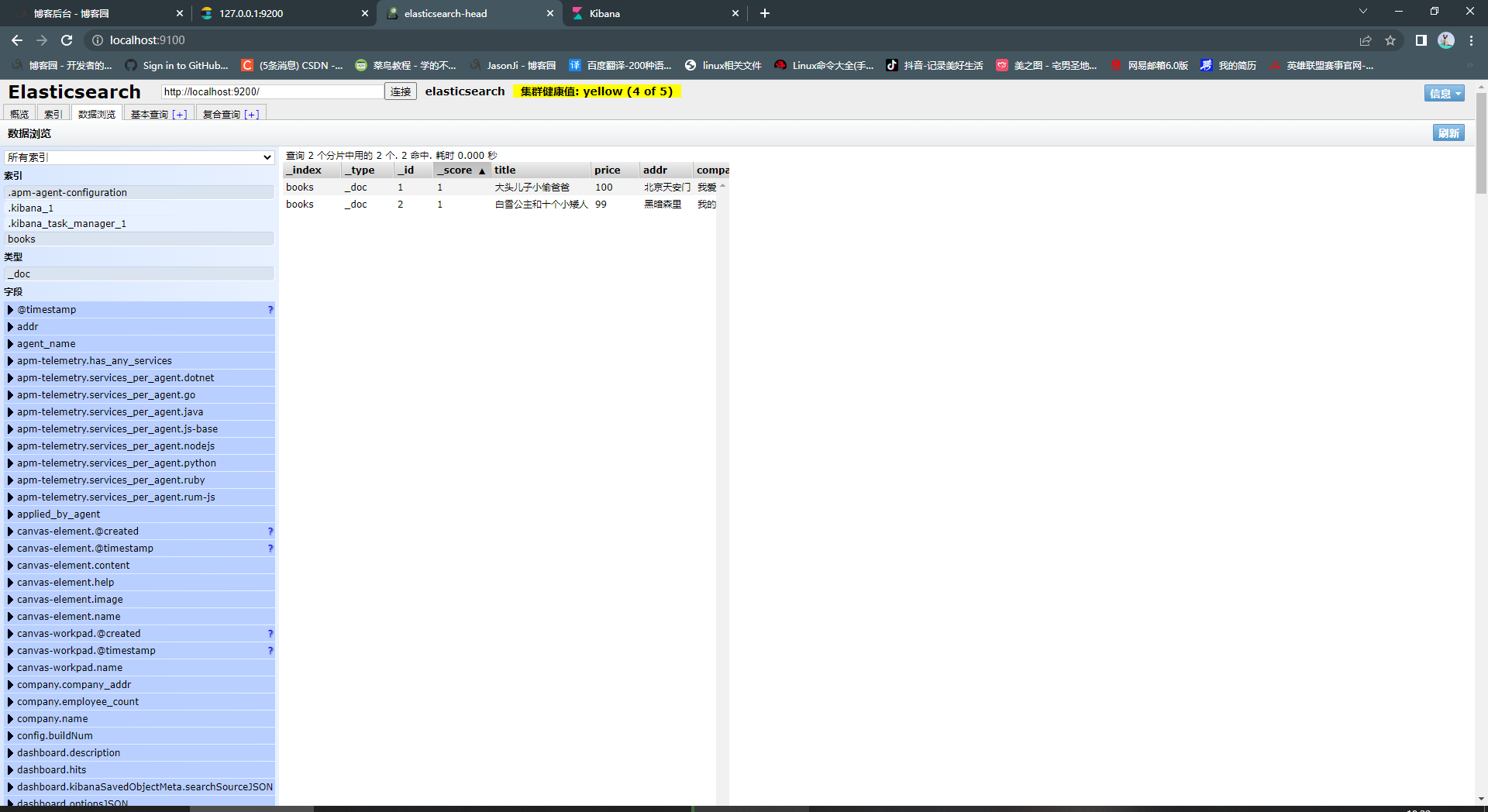
#### 插入文档
# 测试数据1
PUT books/_doc/1
{
"title":"大头儿子小偷爸爸",
"price":100,
"addr":"北京天安门",
"company":{
"name":"我爱北京天安门",
"company_addr":"我的家在东北松花江傻姑娘",
"employee_count":10
},
"publish_date":"2019-08-19"
}
# 测试数据2
PUT books/_doc/2
{
"title":"白雪公主和十个小矮人",
"price":"99",
"addr":"黑暗森里",
"company":{
"name":"我的家乡在上海",
"company_addr":"朋友一生一起走",
"employee_count":10
},
"publish_date":"2018-05-19"
}
6、Elasticsearch的文档增删查改(CURD)
### 文档增
PUT lqz/_doc/1
{
"name":"顾老二",
"age":30,
"from": "gu",
"desc": "皮肤黑、武器长、性格直",
"tags": ["黑", "长", "直"]
}
### 文档改
# 方式一:覆盖更新
PUT lqz/_doc/1
{
"name":"lqz",
"age":30,
}
# 方式二:真更新
POST lqz/_doc/1/_update
{
"doc": {
"desc": "皮肤很黄,武器很长,性格很直",
"tags": ["很黄","很长", "很直"]
}
}
POST lqz/_update/1
{
"doc": {
"desc": "xx,yy,zz",
"tags": ["很黄","很长", "很直"]
}
}
### 文档删
DELETE lqz/_doc/1
### 文档查(最复杂)
# 方式一:根据id
GET lqz/_doc/1
# 方式二:根据查询字符串
GET lqz/_search?q=from:gu
GET lqz/_search?q=age:29
# 方式三:结构化查询(常用,功能丰富)
GET lqz/_search
{
"query": {
"match": {
"name": "gu"
}
}
}
#### 面试重点:term 和 match的区别
- term代表完全匹配,不进行分词器分析
term 查询的字段需要在mapping的时候定义好,否则可能词被分词。传入指定的字符串,查不到数据
-match
match的查询词会被分词,会把要搜索的词分词---》搜索
存的时候,如果是text类型,会分词,建索引存储
# es是个存数据的地方
-mysql---》存到es
-pymysql取出mysql数据---》存到es中
-查询数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号