

MySQL引擎InnoDB读书笔记-第二章
第二章
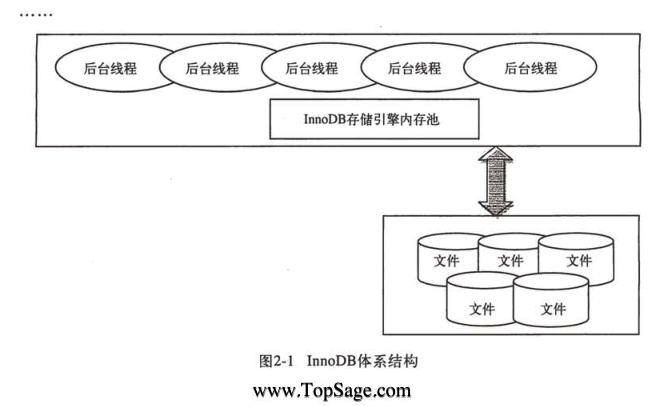
2.2 体系架构
内存池的用途:
- 维护内部的数据结构
- 缓存磁盘上面的数据,方便读取
- 重做日志缓冲
后台线程的作用:
负责刷新内存池中的数据,保证池中的内存缓存的时最近的数据。此外,将已修改的数据文件刷新到磁盘中,同时保证发生异常情况下能回复到正常运行状态。
2.2.1 后台线程
一共有 7 个,4 个 io thread,1 个master thread,1个lock thread,1个err thread
这是 4 个 I/O thread : log, insert buffer, read, write

2.2.2 内存
缓冲池,重做日志缓冲池,额外的内存池
工作方式是将数据库文件按页(每页 16K)读取到缓冲池,然后按LRU 的算法来淘汰。如果需要修改数据库文件,那么会先修改池中缓存的(修改后变为脏页) 以一定频率刷新到磁盘中。
缓冲池中缓存的数据页类型有: 索引页,数据页,undo页,插入缓冲,自适应哈希u松阴,锁信息等
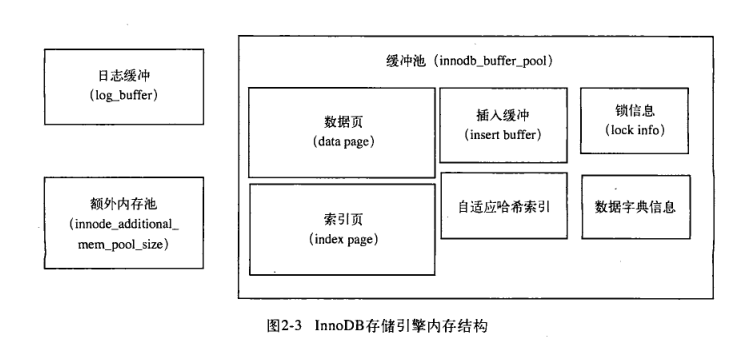
这说明缓冲区不知识缓存索引页,数据页,只是他们占缓冲池很大的一部分而已。
日志缓冲将重做日志信息先写入这个缓冲区,然后按照一定频率刷新。
额外内存池:
对内存的管理是通过 内存堆 的方式进行,比如我们需要创建一些数据结构,就会去他那申请,如果他不够,就会想缓冲池中申请,每个缓冲池中的帧缓冲还有对应的缓冲控制对象,而且这些对象记录了诸如LRU,锁,等待方面的信息,这会从额外缓冲池中申请,所以当申请了很大的 InnoDB缓冲池时,也应增加该值。
2.3 master thread
- 优先级最高。
- 由几个循环组成, 主,后台,刷新,暂停。会根据数据库运行章台在这几个循环中来回切换。
主循环
每秒钟的操作和每十秒钟的操作
loop:
for{int i = 0;i < 10;i ++){
// 必做:
// 将 日志缓冲刷新到磁盘,即使没由提交
// 选做:
// 1. 合并插入缓冲
// 2. 最多刷新 100个 缓冲池中的脏页 -> disk
// 3. 如果没有用户活动,可以切换到 后台循环
sleep 1
}
// work per ten seconds
// 选做:
// 1. 刷新 100个 脏页 -> disk
//必做:
// 1. 合并至少5个插入缓存
// 2. 还是刷新日志缓冲 -> disk
// 3. 删除无用的 undo页
// 4. 刷新 10 或者 100个 脏页 -> disk
// 5. 产生一个检查点
goto loop;
每秒
必做:日志缓冲刷新到磁盘,即使没由提交
这就是为什么再大的事务 commit 也很快
选做
合并插入缓冲 前会判断当前1s内发生的io次数是否小于 5 次,以此判定io压力
刷新脏页: 看是否超过阈值
每十秒
根据 I/O op < 200来判断是否刷新 100 个脏页 -> disk
合并>5页的插入缓存
刷新日志缓存 -> disk
执行 pull purge,删除无用的 Undo页,对标执行update delete这些更改表中数据的操作时,我们会产生行版本信息,在 pull purge这个操作中,我们会判断时否可以删除这个版本。
在跟据脏页比例来 比率 > 70% ? 100 : 10
产生一个检查点。模糊,只写入最老的日志序列号(LSN 8字节的版本号)
Checkpoint(检查点)技术的目的是解决以下几个问题
- 缩短db 恢复时间
- 当数据库发生宕机时,数据库不需要重做所有日志,因为Checkpoint之前的页都已经刷新回磁盘
- 故数据库只需要对Checkpoint后的重做日志进行恢复。这样就大大缩短了恢复时间
- 缓冲池不够用,将脏页 -> disk
- 此外,当缓冲池不可用时,根据LRU算法会溢出最近最少使用的页,若此页为脏页,那么需要强制执行Checkpoint,将脏页也就是页的新版本刷回磁盘
- 重做日志不可用,刷新脏页。
后台
删除无用的 undo 页
合并 20个 插入缓冲
跳回 主循环
可能跳转 flush loop
flush loop
不断刷新 100 个页
切换暂停,等待事件。
2.4关键特性
插入缓冲 -性能
也是物理页的一部分
插入聚集索引一般是顺序的,不需要随机读取。后面章节会讲,如果是辅助索引的话,因为叶子节点存储的是主键,还需要根据这个主键去读正真的索引页,所以不是顺序读。
所以设计了插入缓冲,对于非聚集索引的更新或者插入,不是每一次直接插入到索引页中,而是先判断非聚集索引页是否在缓冲池中。
在: 插入
不在:放一个到插入缓冲区中,这时我们其实没有访问到真正的非聚集索引页,所以时假 插,然后以一定频率进行 与非聚集索因页 子节点进行合并),就像批插入。
使用插入缓冲需要两个条件。
- 辅助索引
- 不是唯一
为什莫不是唯一呢?因为唯一需要判重。
两次写 -可靠性
避免数据丢失。
写失效: 没将整个页写完,比如(16K只写了4K)
为什么不用重做日志回复。因为重做日志是对页的物理操作,操作的页都有问题,拿什么保证恢复的正确性?
写入 double write
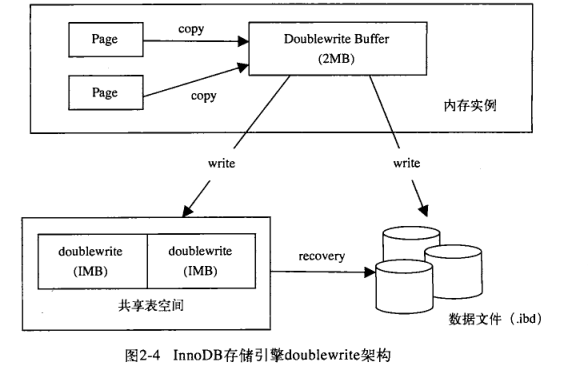
两部分
- 内存中的
double write buffer - 物理磁盘上共享表空间的连续
128个页
大小都为两个区 2MB
当池中的脏页刷新时,并不直接写磁盘,回事先将脏页中的数据拷贝到内存中的double write buffer,然后通过 double write buffer再分两次,每次写入 1MB到共享表空间的物理磁盘,然后立马同步到磁盘。因为写入共buffer 是顺序写,所以开销不是很大。然后写入 各个表空间。此时的写是离散的。
恢复过程
- 写失效,在共享表空间找副本,拷贝到表空间文件
- 应用重做日志。
自适应哈希索引
监控对表上索引的查找,如果观察到建立索引可以提高速度,那麽就会建立,所以称为自适应的。
通过缓冲池中的b+树构造而成,因此建立速度很快。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号