JPA
配置文件
mysql8.0和5.7有区别
- 如启动报错:Communications link failure
The driver has not received any packets from the server. 则注意检查连接mysql版本
点击查看代码
## 数据源配置
spring.datasource.url=jdbc:mysql://localhost:3306/test?characterEncoding=utf-8&useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=admin
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
## Spring Data JPA 配置 5.7的
spring.jpa.database-platform=org.hibernate.dialect.MySQL57Dialect
##Spring Data JPA 配置 8.0的
spring.jpa.database-platform=org.hibernate.dialect.MySQL5InnoDBDialect
## 运行时输出 jpa 执行的 sql 语句
## 打印sql
spring.jpa.show-sql=true
## 根据实体类自动生成数据表(SpringDataJPA可以自动生成数据表)
## create:每次运行项目会自动创建新表,如果之前已经存在,则删除,重新创建
## update:只会更新数据表
# create-drop,启动时生成表,停止时,把表删除!!!
spring.jpa.hibernate.ddl-auto=update
#jackson对日期时间格式化设置:时间格式
spring.jackson.date-format=yyyy-MM-dd HH:mm:ss
#jackson对日期时间格式化设置:时区设置
spring.jackson.time-zone=GMT+8
如何初始化数据库
# 控制spring.jpa.hibernate.ddl-auto=xxx是否执行
spring.jpa.generate-ddl=true
spring.jpa.hibernate.ddl-auto=update
- spring.jpa.hibernate.ddl-auto= 有5个属性
| value值 | 含义 |
|---|---|
| none | 不做处理 |
| create | 每次加载会先删除上一次生成的表,哪怕2次没任何变化也要删,数据会丢失 |
| create-drop | 每次加载hibernate时根据model类生成表,但是sessionFactory一关闭,表就自动删除。即系统停止时,会删表,数据会丢失 |
| update | 每次启动先检查是否有表,无则创建,有再检查是否有新字段,无此字段则添加,老字段,列类型无法修改 |
| validate | 验证创建数据库表结构,只进行比较,不会创建新表,但是会插入新值 |
生产环境
spring.jpa.hibernate.ddl-auto=none
spring.jpa.generate-ddl=false
生产环境的数据不允许随便修改,属性类型有调整,可以新建个字段和属性,把原来的数据用脚本迁移过去
原生写法
- load方法(代码中使用该对象时才查库)
User user = entityManager.getReference(User.class,1);
此时user是个代理对象
- get方法(正常查询)
User user = entityManager.find(User.class,1);
实体类注解
点击查看代码
@Entity
@Data
@Table(name = "student")
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long sid;
@Column(length = 30,unique = true)
private String name;
// 属性在字段的实际类型
@Column(columnDefinition = "char")
private int age;
@Column
private String home;
}
@Entity 加在类上,表示类名和表名的映射
@Table类上,当类名和表名不同时使用
@GeneratedValue(strategy = GenerationType.AUTO) 主键的生产策略
IDENTITY :自增(oracle不支持)
AUTO: jpa自动选择合适的策略,(默认值)
SEQUENCE: 通过序列产生主键,通过@SequenceGenerator注解指定序列名(mysql不支持);
TABLE: 通过表产生主键,借由表模拟序列产生主键,此策略可以使应用更易于数据库移植
@Basic,属性和字段的映射,getXxx()默认即为@Basic。
fetch属性,optional属性,是否允许为null,默认true
@Column 加在属性、get方法上,属性名和字段名不同时,使用。
有unique,length等属性
@Transient 加在属性上,表中可以没有此属性的字段(javax.persistence包)
// 表的字段会为date
@Temporal(TemporalType.DATE) 日期的格式,精确到日(3种:DATE--date,TIME,TIMESTAMP--datetime)
private Date birthday;
原生sql
MP和JPA对比
实体类
| jpa | MP | 备注 | |
|---|---|---|---|
| 类上 | @Entity(name = "distribution_task_temp") 或 @Table(name = "distribution_task_temp") | 1.@TableName("tb_user") | 表名和类名映射 |
| 主键属性 | "@Id @GeneratedValue(generator = "system-uuid")@GenericGenerator(name = "system-uuid", strategy = "uuid")@Column(name = "id") | @TableId(type= IdType.AUTO) | 3 |
| 普通属性 | @Column(name = "customer_id") | @TableField |
dao
栗子:
@Repository
public interface WriteOffRecordRepository extends JpaRepository<WriteOffRecord, Long>,
JpaSpecificationExecutor
JPQL语法
@Query注意点
1:大多情况下需要将*改为别名
2:表名要改为类名
3:字段名改为属性名
4:修改、删除还需要加注解:@Modifying
5:想写原生sql设置属性nativeQuery = true,要用Obeject[]来接
6: 占位符默认和参数顺序保持一致
占位符不按参数顺序的写法,?数字:

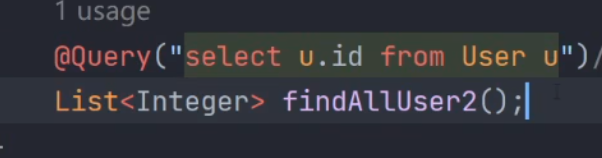
- 查一个列(泛型是属性的类型)
![image]()
- 查多个列
![image]()

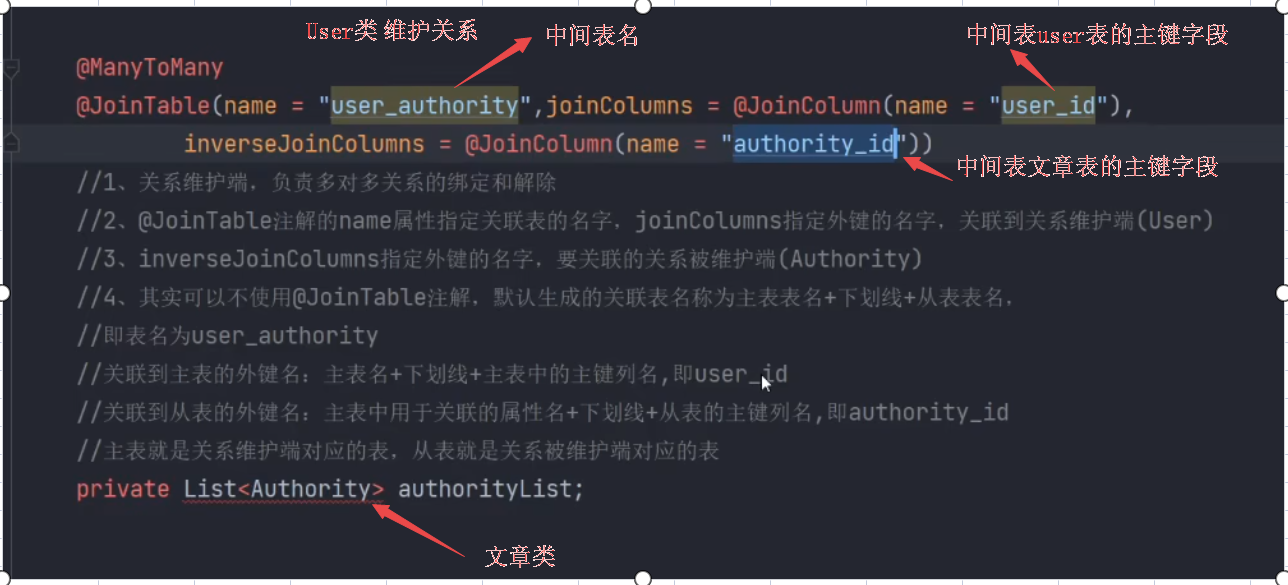
多对多
@ManyToMany
@JoinTable
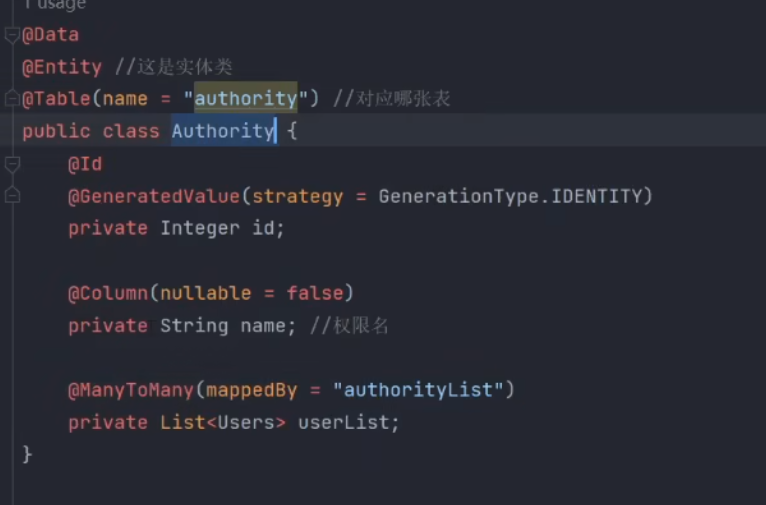
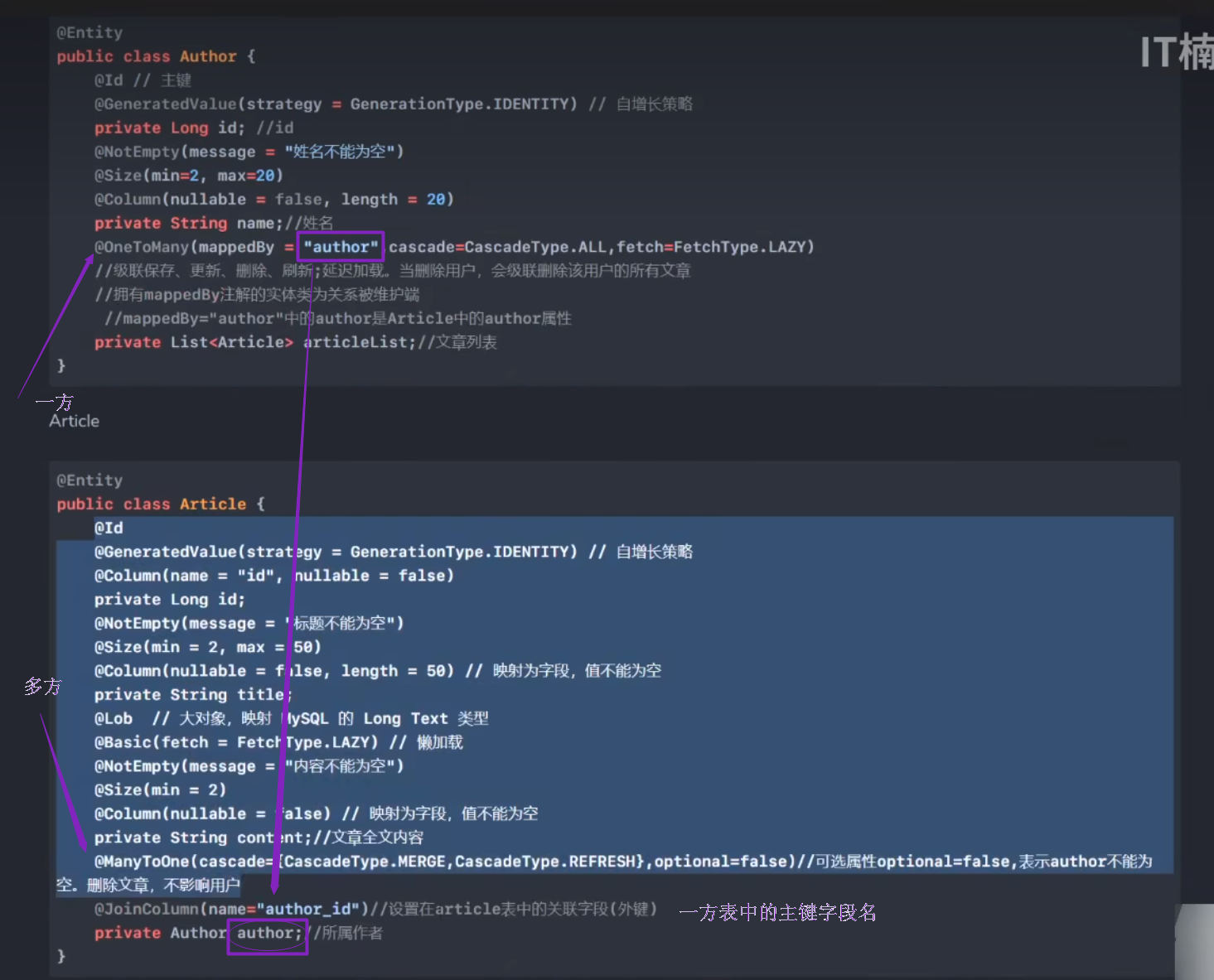
一对多
多方表会创建外键(一方的主键)
@OneToMany(加在一方)
例子:@OneToMany(mappedBy = "classes", cascade=CascadeType.DETACH, fetch = FetchType.LAZY)
-
属性“串联”: cascade=CascadeType
- 增:CascadeType.PERSIST —–>save()
- 删:对应CascadeType.REMOVE —–>delete()
- 改:对应CascadeType.MERGE ——>update()
- CascadeType.DETACH
-
属性“获取” fetch=FetchType.EAGER 和LAZY
- LAZY,访问该对象,才查询。
- EAGER,立即查询
@ManyToOne(加在多端)
@JoinColumn 填写一方的属性名
下图是错误的示范,在一方,fetch=FetchType.Lazy会造成查询时报错,无法级联查出多方数据
查一方,自动级联查出多方
1:一方的注解:@OneToMany(mappedBy="一方在多方的属性名",fecth=FetchTypeEAGER),如果是LAZY,会报could not initialize proxy - no Session
2: 注意循环依赖问题(StackOverflowError),在多方排除一方(双引号里面是一方属性名)
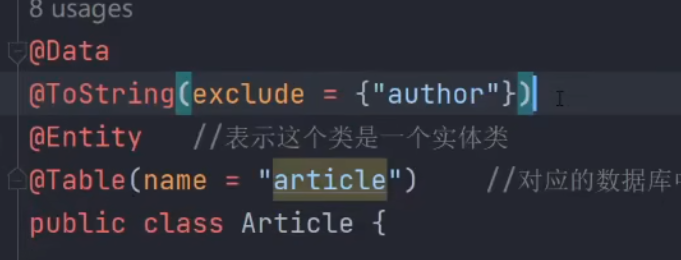
一对一
@OneToOne
-
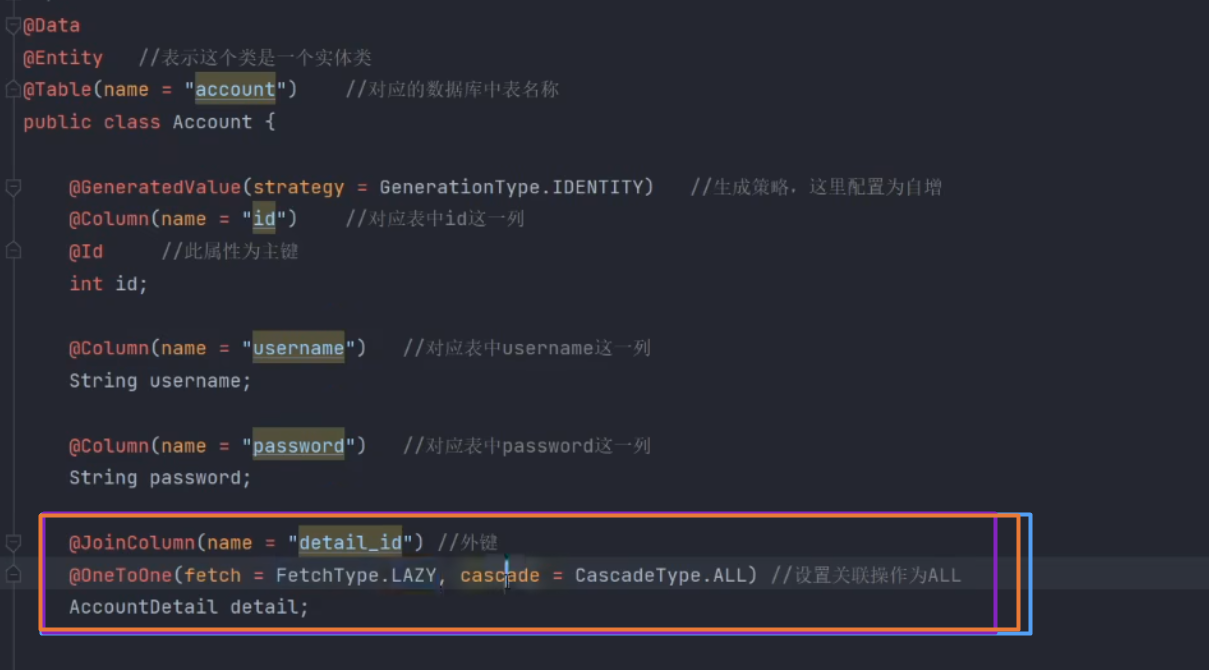
实体类(截图中会自动创建外键)
![image]()
-
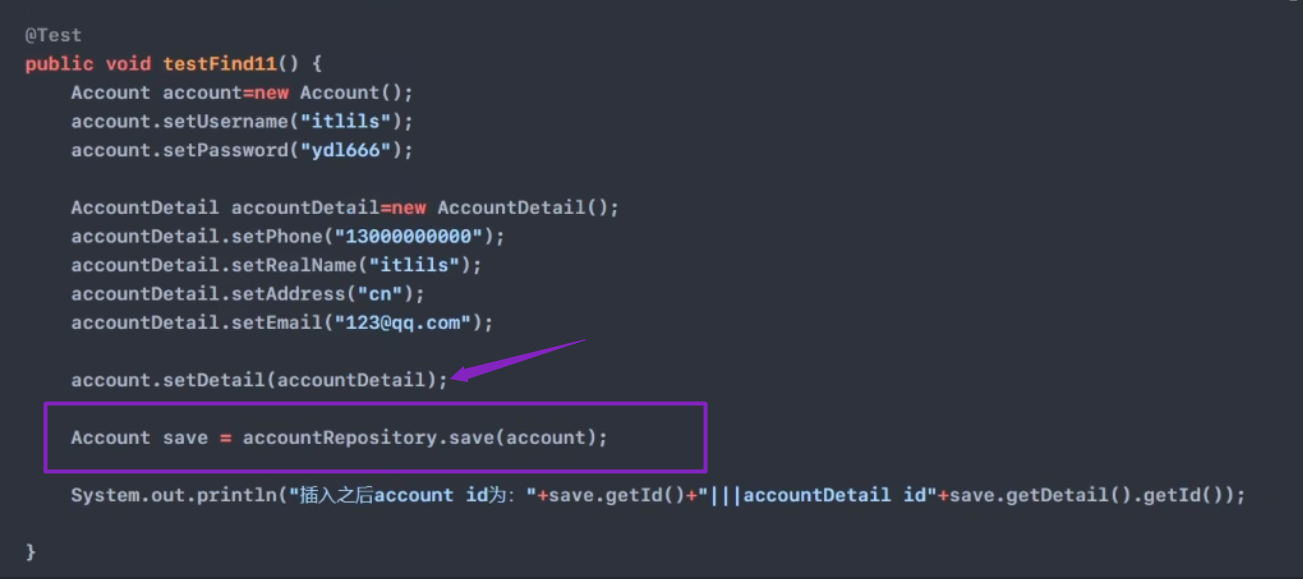
dao
save(子对象和主对象都插入了)
![image]()
删(删主对象,关联对象那行也别删了)
![image]()

高级用法
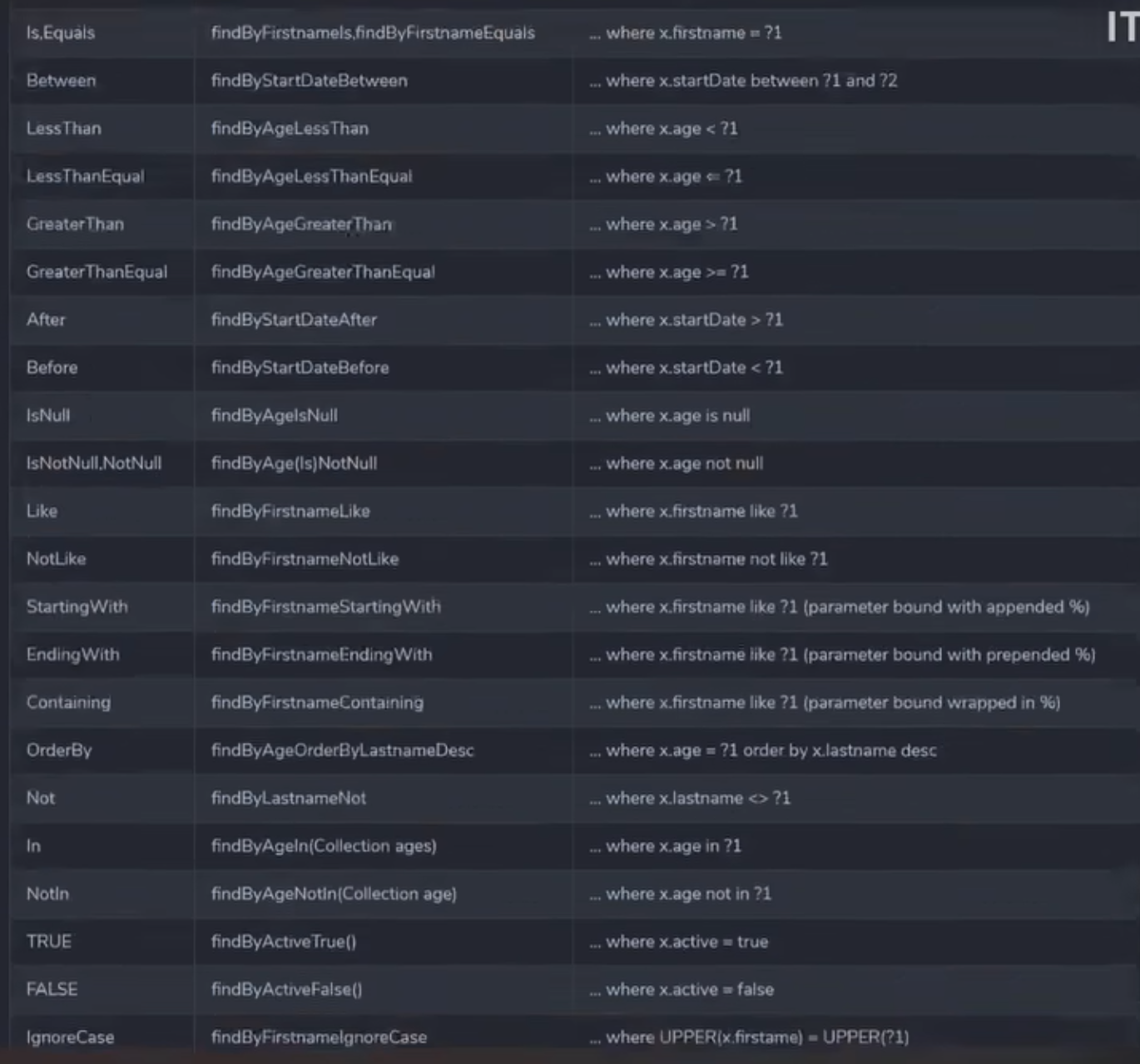
- findBy
属性名首字母大写
参数默认按顺序 - eq
/**
* 固定语法格式:findBy 加属性名首字母大写(where student0_.name=?)
* @param name
* @return
*/
ListfindByName(String name);
-
and
![image]()
-
多字段组合
findByNameLikeOrAgeBetween(String nam, int startAge, int endAge); -
文档
startingWith,截图意思是,参数就要这样传:“jf%”
![image]()
-
对比

| jpa | MP | 备注 | |
|---|---|---|---|
| dao层 | JpaRepository | BaseMapper | 对单表的curd方法 |
动态查询
重点
JpaSpecificationExecutor<T> 接口
类似于MP的IService
方法

Specification参数
类似于MP的QueryWarrper

Sort排序参数
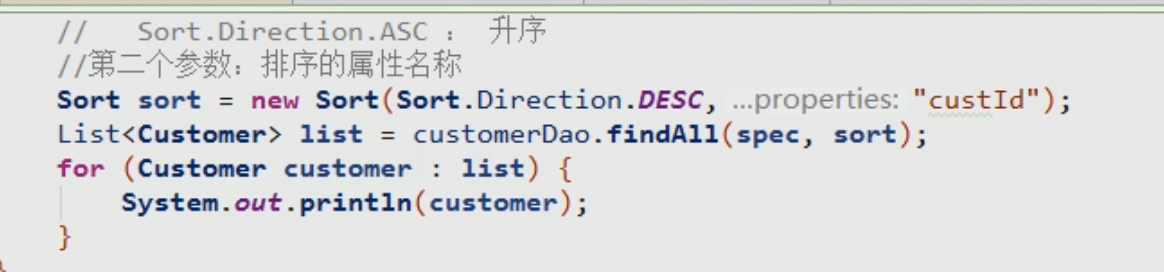
PageRequest分页参数
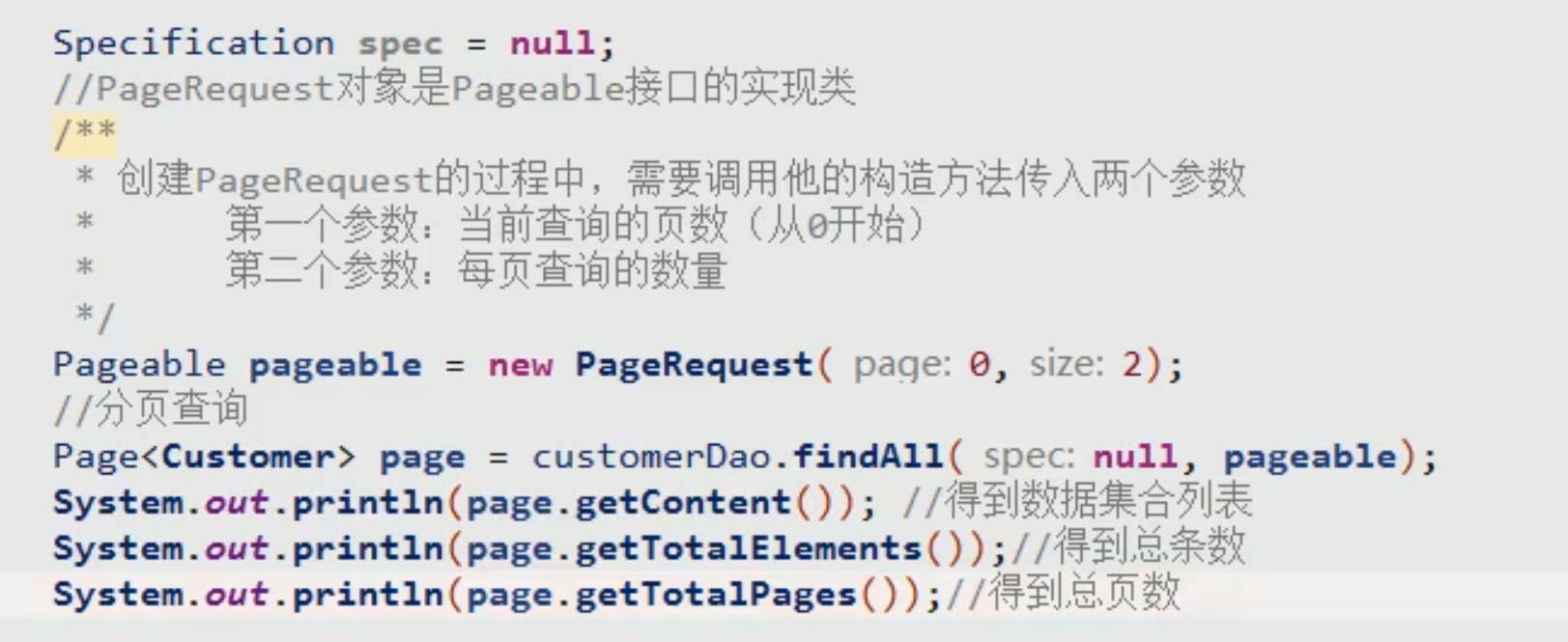
问题
@Formula
- 用法2:执行sql
@Formula("select count(s.id) from order s where s.user_id=id") - 用法1:表中字段做函数运算
@Formula("goods_sales_num + sham_sales_num")
private Long allSalesNum;
@MappedSuperclass
@EntityListeners(AuditingEntityListener.class)
@DynamicInsert做什么的
默认true
Entity类中写@DynamicInsert(true)从而实现
在使用save函数保存新数据时如果实例对象某个属性为null时则不写入数据库中。
如果不使用此注解则会把null写入数据库中,数据库中该字段变为null值。
NamedEntityGraph做什么的
应用场景:N+1
用法
@NamedEntityGraph(name = "goodsInfo", attributeNodes = {@NamedAttributeNode("goodsInfo")})
@JoinColumn的属性用法
什么意思
@JoinColumn(name = "goods_info_id", insertable = false, updatable = false)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号