redis
安装
linux
wps上有文档,单机部署 、主从部署 、哨兵部署 、集群 部署的安装
WIN
带密码
== 需要配置一个bat脚本,不然需要每次启动时重复执行,而且需要以系统管理员执行bat,不然rdb文件保存会失败==
1:redis.windows.conf文件中配置:requirepass这一行,示例:requirepass 123456 // 数字为你的密码
2: bat文件内容(需要以系统管理员运行)如下:
@echo off
set REDIS_DIR="C:\Program Files\Redis"
REM 切换到Redis安装目录
cd /d %REDIS_DIR%
REM 启动Redis服务并使用配置文件
redis-server redis.windows.conf
pause
客户端连接
win
需要先有 redis-cli.exe
-
连本地
双击redis-cli.exe
![image]()
-
连远程
cd 到 redis-cli.exe目录
执行:redis-cli -h IP -p 6379
连接上效果:
![image]()

面试题

启动问题
- win双击闪退,可通过命令行命令启动
到 redis 文件目录下,输入cmd命令
然后在dos窗口输入:redis-server.exe redis.windows.conf
命令
| 用密码:登录 | auth 1111 |
|---|---|
| 查询所有键 | keys * |
| 通过键查值 | get xxx |
| 命令行登录客户端 | 切换到redis目录下双击运行 redis-cli.exe |
| 设置过期时间 | persist |
| 查看密码 | config get requirepass |
| 设置密码 | config set requirepass 123456 |
命令行要验证密码
先输入 auth 密码
再执行命令
win命令行登录客户端
1:找到redis-cli.exe的目录,双击redis-cli.exe
2:验证连接是否成功,执行命令ping,返回pong,表示成功。
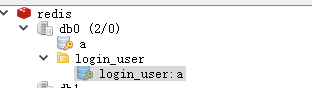
分组
前缀分号“:”,代表分组
效果图:
持久化
RDB
1:手动持久化
2:根据配置文件自动触发
配置文件
save 900 1 // 900秒有一个键值对发生变化
save 300 10 // 300秒内有十个键值对变化
save 60 10000 // 60秒内有1W个键值变化
手动有2个命令
1:save,该操作在主线程工作,会阻塞其它请求,应该避免,默认会把数据持久化到dump.rdb文件,在redis重启后自动读取。
2:bgsave是调用fork产生子进程做数据持久化写入临时文件,写完后,替换原有的.rdb文件。fork发生时,父子进程内存共享,在这期间修改的数据会复制一份,不进共享内存,所以说,rdb持久化的数量,是fork发生时的数据,在某些情况掉电时,会丢失一段时间的数据。
AOF
配置文件默认为关闭 appendonly no ,no修改为yes,切换到aof持久化,开启aof后,每执行一条指令,都会被记录到appendonly.aof文件中。不是立即将命令写入磁盘,而是写入硬盘缓存。
根据下面配置,控制多久从硬盘缓存写入硬盘,在某种情况下还是会有数据丢失。

默认为everysec,每秒一次。
而always则是每次操作立即写入aof文件。效率最低
no是不主动同步操作,默认30s一次,
rdb和aof对比
rdb极端情况下,会丢失的数据比aof多,但性能相对更好,恢复数据更快,
aof的持久化文件会更大,更消耗内存。
缓存穿透
定义:redis和db都没有,大量请求持续发起请求,压到db,导致db压力过大,甚至击垮db。
场景:
请求持续查询某个不存在的id,恶意攻击。
解决办法:
1: 拦截器做权限校验,在接口层做参数合法格式校验。
2:可以将此key的值设为null,设置个过期时间(可防止反复用同一个id暴力攻击)。
优点:实现简单,维护方便。
缺点:
额外的内存消耗(恶意请求大量随机不重复的值)
3:表数据放入bloomfilter过滤器,它的特点是,bloomfilter中不存在,那数据一定不存在,bloomfilter中存在,实际可能也不存在。
优点:内存占用少
缺点:
算法复杂(误判率越低,算法越复杂)
存在误判
缓存击穿
定义:雪崩是大量的,击穿是针对个别key,穿透是redis和db都没有,击穿(key过期)是redis无,db有,某个key在失效的瞬间,持续的大量并发穿过缓存,直接请求到db,击垮db。
解决办法:
1:热点数据永不过期。
2:加互斥锁。
场景:
微博突发新闻。
缓存雪崩
定义:
大量key在同一时间失效,导致大量请求压力落到db,把db压垮,导致系统瘫痪。
场景:
1:redis挂了。
2:应用刚启动,key还没预热,瞬间大量流量涌入。
解决办法:
1:把key的失效时间分散开,可用随机时间秒数。
2: 互斥锁;
3:使用快速失败的熔断策略,减少DB瞬间压力;
4:使用主从模式和集群模式尽量保证服务器的高可用
5:缓存预热(服务启动后,自动查询一次)
缓存无底洞
缓存失效
热点key倾斜
热点key重建
缓存和数据库双写不一致
电商双十一,12306抢票,成都统一晚上核酸采样,redis热点key过期时间一样,大量key同一时间失效后,同时大量用户请求涌入,进行读写操作,DB负载持续很高,DB没抗住挂了,服务没做熔断降级,多个请求占用线程,最后系统挂掉,重启,新的大量请求在redis查不到,压力又压到DB,形成恶性循环,系统又瘫痪了。
面试总结
1.集群模式下,redis的key如何寻址?分布式寻址有哪些算法?了解一致性hash算法吗?
2.使用redis有哪些好处
3.redis和memcached的对比
4.redis常见性能问题和解决方案
5.mysql有2000w数据,redis只有20w数据,如何保证redis中都是热点数据
6.哪些场景可充分利用redis特性,大大提高redis效率
7.缓存雪崩、击穿、穿透是什么,怎么解决
8.redis的数据类型有哪些?使用场景,高级用法
9.redis主从如何同步数据?集群如何保证高可用?
10.持久化机制
11.为啥redis单线程还能支持高并发
12.如何保证缓存和数据库的一致性
13.在项目中如何使用缓存,又遇到哪些问题吗?
14.哨兵模式知道吗
13:可能会遇到问题:
缓存更新
数据不一致
缓存击穿、穿透、雪崩

 浙公网安备 33010602011771号
浙公网安备 33010602011771号