mysql
远程连接
格式:mysql -h主机地址 -u用户名 -p密码
mysql -h10.137.21.2 -uroot -p
注释语法
- 1: --后面带空格
- 2:/**/
- 3: #
查询的顺序问题
- 书写顺序
select distinct from join on where group by having order by limit - 执行顺序
from on join where group by having select distinct order by limit - where 条件不能跟聚合函数。
数据类型
json
版本要求:5.7以上
代码自动映射
借助MP,
-
保存,对象存到表
- 添加属性:@TableField(typeHandler = JacksonTypeHandler.class)
-
查,字段转属性
1:需要在xml,自定义语句,
2:用resultMap接,再加这个<result property="json" column="params" typeHandler="com.baomidou.mybatisplus.extension.handlers.JacksonTypeHandler"/>
bit
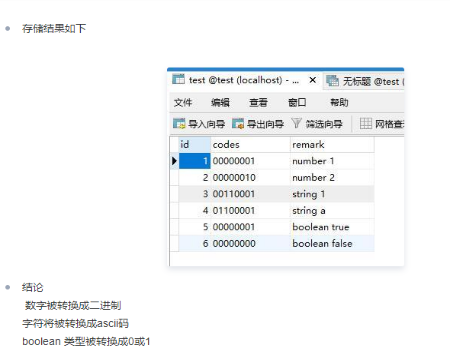
整型
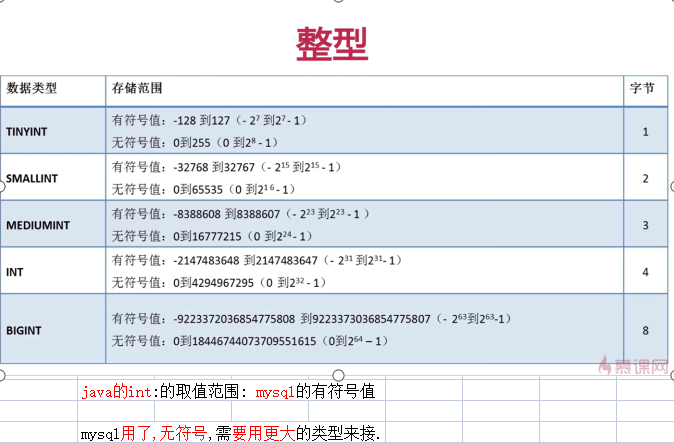
浮点型
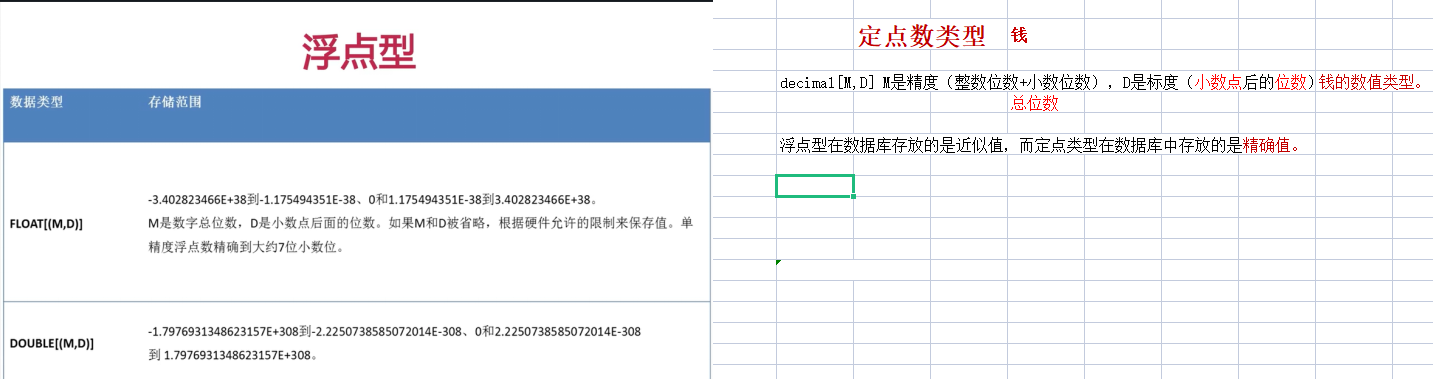
时间型
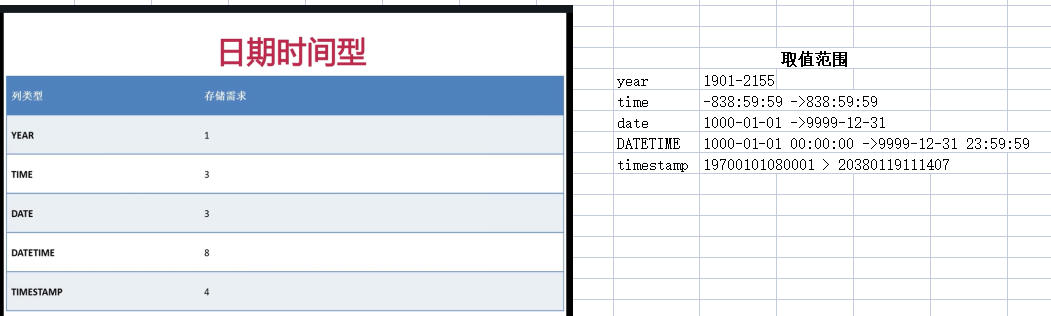

字符型

约束
- 非空约束 not null
- 主键约束 primary key
一张表只能有一个
主键要保证唯一性
主键自动为 not null - 唯一约束 unique key
一张表有n个
可以为null
相同的字段不可重复 - 默认约束 default
根据数据类型,设置默认值。 - 外键约束
子表外键值可以为null,孤儿数据。
被引用字段(父表)必须具有unique约束
先建父表插入数据,再插入子表数据;
子表可以为null,但不能出现父表没有的值;
mysql没有语法,直接修改外键约束,必须删除后,重新建外键约束;
创建命令:alter table 子表 add foreign key (字段) references 主表2(列名);
主表字段必须为唯一约束,字段必须加()括号
父表和子表必须使用InnoDB,而且禁止使用临时表;
引擎
| MyISAM | InnoDB | Memory | Archive | |
|---|---|---|---|---|
| 存储容量 | 256TB | 64TB | 内存大小 | 无 |
| 事务安全 | - | 支持 | ||
| 支持索引 | 支持 | 支持 | - | |
| 锁颗粒 | 表锁 | 行锁 | 表锁 | 行锁 |
| 数据压缩 | 支持 | - | - | 支持 |
| 支持外键 | - | 支持 | - | - |
InnoDB
支持事务,行级锁和外键约束。5.5以后版本的默认存储引擎。
MyISAM
不支持事务,有表锁,无行级锁和外键。
锁
锁的类型
- 共享锁(读锁):同一时间段内,多个用户可读取同一资源,读取过程中数据不发生变化。
- 排他锁(写锁):任何时候只能有一个用户写入资源,执行写锁时会阻塞其它的读锁或写锁操作。
锁的颗粒度
- 表锁,开销最小的所策略。
- 行锁,开销最大的所策略。Mysql的InnoDB死锁检测默认50s;
事务
-
定义
一条或一组SQL,保持数据一致性,要么同时执行成功,要么同时失败。一条查询也是一个事务。 -
命令
BEGIN 或 START TRANSACTION
commit或rollback
set autocommit=0或off 禁止自动提交,调用了此方法,必须要执行commit才会提交。
set autocommit=1或on 开启自动提交 -
DDL
执行DDL语句,create table语句,会自动执行commit。
执行一条DML语句,该语句失败,会为这个无效的DML语句自动执行rollback语句。 -
ACID
| 原子性 | atomicity | 一个事务的所有操作,如物质的最小单位原子一样,不可再分割 |
| ------------ | ------------ | ------------ |
| 一致性 | consistency | 数据库从一个一致性状态变成另一个一致性状态,一致性和原子性紧密相连,一个事务的所有sql必须要么全部成功,要么全部回滚。 |
| 持久性 | durability | 事务一旦提交、回滚,数据的状态就被保存到硬盘,永久保存。 |
| 隔离性 | isolation | 事务之间并发操作同一份数据,互不影响,相互独立。 | -
保存点
savepoint identifier
允许在事务中创建保存点,一个事务可以有多个。
![image]()
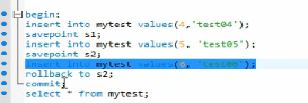
rollback to identifier
事务回滚到标记点。
隔离级别
- 查看命令
select @@tx_isolation; 8和之前的语法区别: tx换为单词全称
- 修改级别
SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;
- 有效范围
1: 全局级(global)
2:会话级(session)
| 现象 | 名称 | 级别 | 说明 |
|---|---|---|---|
| 脏读 | 读未提交:Read Uncommit | 最低 | 一个事务读到另一个事务未提交的修改后数据,别人可能会回滚或修改为其它值 |
| 不可重复读 | Oracle默认,读已提交:Read commited | 倒数第2 | 读到的数据易变,2个事务,A事务第一次读到数据是张三,B事务把张三改为了王二麻子,A事务再次读第一次那一行数据,读到的是王二麻子。 |
| 幻读 | Mysal默认,可重复读:repeatable read | 倒数第3 | 自己2次读取的数据没变,单被别人修改了都不知道, |
| 加锁 | 串行化:serializable | 最高 | 类似排队、线程加锁,sychronized,同一时间只能执行一个事务,必须等该事务commit或rollback后,其它事务才能继续执行 |
DML
insert
插入某个记录:
INSERT emp SET emp_name='hello',id=17612811194
插入所有列:
-- 指定列
insert into t_user (id,name,age) values(1,'saka',33),(2,'sb',51);
-- 所有列
insert into userInfo values(2,'a2'),(3,'a3'),(4,'a4');
--将查询结果添加到表
insert into 51book select * from test where id > 5;
delete
--删除表中所有数据
-- 数据量小
delete from 表名;
-- 数据量大用
truncate table mytest;
-- 根据条件删除
delete from mytest where id = 4;
-- 删除表中重复数据
点击查看代码
delete
from
tbl_goods AS t1
LEFT join
(select goods_id,goods_name FROM tbl_goods GROUP BY goods_name t2.goods_id HAVING count (goods_name) > 1) AS t2
ON t1.goods_name = t2.goods_name
WHERE t1.goods_id > t2.goods_id
update
-- 修改全表
update 表名 set age = 20;
-- 根据条件修改
update 表名 set 列名1=表达式1,列名2 = 表达式2 where 条件表达式;
select
| 功能 | 命令 |
|---|---|
| 显示当前库的字符集编码 | show variables like 'char%';// 默认为latin1 |
| 查看指定库的字符集编码 | show create database mydb1; |
| 显示当前库下的表 | show tables [from 其它库名]; |
| 查看表的字段 | desc<表名> |
| 显示所有库 | show databases; |
| 显示表的创建语句 | show create table tab_name; |
| 查看存储引擎 | show engines; |
| 查当前连接的数据库名称 | select database(); |
| 查当前时间 | show now(); |
| 查当前版本 | show version(); |
| 查当前用户名 | show user(); |
| 去除重复列 | select distinct 列名 from 表名 |
| 模糊查找 | like '%张%',包含;like '张%',姓张;like '%飞',以飞结尾的,like '%用_',倒数第二个字为用 |
| 不等于 | <>标准语法,!= mysql的语法 |
sql查询
case when
- 第一种(代码冗余,重复,)
-- 结尾没有加别名,注意区分,冗于是为了解决,有的字段无值,不显示问题
select case when sal <=1000 then '1k一下'
when sal between 1001 and 2000 then '1-2k'
else '2k以上' end as '薪水等级',
count(sal) as '数量' from emp
group by case when sal<=1000 then '1k一下'
when sal between 1001 and 2000 then '1-2k'
else '2k以上' end;
- 第二种 推荐
select temp.comm_level,count(*) 数量 from (select case
when comm is null then '0'
when comm between 1 and 100 then 'a'
when comm between 101 and 200 then 'b'
else 'b+' end comm_level from emp ) temp group by temp.comm_level
查询优化
- 查询慢的原因,1:数据量大。2:返回前端的数据多
- 建表时根据业务选择最合适的类型
- 给where 和order by判断的字段添加索引
- 联合索引遵循最佳左前缀,先用等于,再用范围
- where 后尽量不要用<>,or可以放在最后
- =号左边不要进行函数运算
- 避免隐士转化,如:' 3'=3
- like '%abc%'索引会失效,'abc%'开始会走
- 数字比字符查询效率高
- 从业务上优化,每页最大条数从2000降到500
- 覆盖索引
- in 适合括号里数据少的,exists适合括号里数据多的
explain
| 关键字 | 说明 |
|---|---|
| type | 效率: 最好-->最差 const, eq_reg,ref,rang,index, ALL |
| Extra | 对SQL的解析分析 |
| table | 数据是那张表的 |
| possible_keys | 显示可能应用在这张表的索引, 为空,没有索引 |
| key | 实际使用的索引,为null,则没有使用索引,哪种情况强制使用索引:SELECT语句中使用USE INDEX(indexname) |
| key_len | 使用索引的长度,不缺失精确性时,越短越好; |
| ref | 索引的那一列被使用了,可能的话,是个常数 |
| rows | MYSQL认为必须检查的,用来返回请求数据的行数 |
type
1:stem:只有一条数据,const的特殊情况
2:const:满足条件的数据只有一条
3: eq_ref: 连接中查询另一张表的主键或唯一键
4: ref:查询条件不是主键或唯一约束,严重依赖索引匹配记录数(越少越好)
5: rang:连接类型使用了索引,返回一个范围
6:index:连接类型对前面的表进行了全表扫描,比all好一点,索引一般小于全表行数
7: all:连接对前面的表进行了全表扫描
Extra
1:Distinct: 一旦引擎找到匹配的行,就不再搜索
2: not exists:引擎优化了left join,一旦它找到了匹配left join标准的行,就不再搜索了。
3:rang checked for each record (index map:#):没找到理想的索引,对前面表中的每一行组合,mysql检查使用哪个索引,并用它来从表中返回行,这是使用索引最慢的连接之一。
4:Using filesort:需要优化,mysql需要进行额外的步奏来发现如何返回的行排序,它根据连接类型以及存储排序键值和匹配条件的全部行的行指针来排序全部行。
5:using Index:覆盖索引,而没有读取实际的行动的表返回的,这发生在对表的全部请求列都是同一个索引的字段时。
6: using temporary:需要优化,mysql需要建临时表来存储结果,通常发生在对不同的列集进行order by,而不是group by。
7:where used:使用了where从句来限制哪些行将 与下一张表匹配或者返回给用户,如果不想返回表中的全部行,并且连接类型all或index,
函数运算
字符函数
| 函数 | 描述 | 实例 |
|---|---|---|
| CONCAT() | 字符连接 | select concat(first_name,last_name) AS fullname from test; |
| CONCAT_ws() | 用指定的分隔符进行字符连接 | select concat_ws(不一定大写)('|','a','b','o',少需要3个参数,有些符号是不行的 |
| format() | 数字格式化 | select format(123456789.33,0); |
| lower() | 全部转化小写 | select lower('MYSQL');输出为mysql |
| upper() | 全部转化大 | select upper('cba,nba'); |
| left() | 获取左侧字符 | select left('myqsl',3);获取左侧3个字母myq |
| right() | 获取右侧字符 | select right('oracal',3);获取右侧3个字母cal |
| LENGTH() | 获取字符串长度 | select length('fen g;;'); |
| TRIM() | 删除前导和后续空格 | select length(trim(' mysql ')); |
select lower(left('SOCCOR',3)); 输出soc
数字运算符
| 函数 | 描述 | 例子 |
|---|---|---|
| CEIL() | 进一取整 | select ceil(3.32);返回 4 |
| floor() | 舍一取整 | select floor(3.44);返回 3 |
| DIV | 整数除法 | select 3 DIV 4;返回0 |
| MOD(%) | 取余数() | select 5 mod 3;返回取模2 |
| POWER() | 幂运算 | select power(4,2); 返回16 |
| ROUND() | 四舍五入 | select round(3.77,1); 返回3.8 |
| TRUNCATE() | 数字截取 | select truncate(125.399,2); 返回125.39 |
日期函数
| 名称 | 描述 | 例子 |
|---|---|---|
| NOW() | 获取当前时间和日期 | SELECT NOW();格式2017/10/1 16:15:00 |
| CURDATE() | 当前日期 | SELECT CURDATE();返回2017/10/1 |
| CURTIME() | 当前时间 | SELECT CURTIME(); 返回16:17:33 |
| DATE_ADD() | 日期变化 | SELECT DATE_ADD('2000-1-21',+-365,DAY); 返回2001-1-22或1999-1-20 |
| DATEDIFF() | 日期差值 | SELECT DATEDIFF('1989-6-6','2000-1-1'); 返回-3861 |
| DATE_FORMAT() | 日期格式化 | SELECT DATE_FORMAT(2014-3-2','%m/%d/%y'); 返回03/02/2014 |
加密函数
| 名称 | 描述 | 例子 |
|---|---|---|
| MD5() | md5加密 | SELECT MD5('admin'); |
| PASSWORD() | 密码算法 | set password=password('dimitar'); |
备份mysqldump
- 压缩后备份
亲测成功,压缩比:7:1
-- p后面是密码,不能有空格
mysqldump -u root22 -proo2tRoot123++ --all-databases | gzip > /tmp/mysql/back/all_databases_backup2.sql.gz
- 备份单个库
-- p后面是密码,不能有空格
mysqldump -u root2 -p密码 库名 > /tmp/mysql/back/demo.sql
- 多个库
-- p后面是密码,不能有空格
mysqldump -u root -p123 --databases db1 db2 db3 > multiple_databases_backup.sql
- 所有库
亲测成功
-- p后面是密码,不能有空格
mysqldump -u root -p123 --all-databases > /tmp/mysql/back/all_databases_backup.sql

 浙公网安备 33010602011771号
浙公网安备 33010602011771号