mysql面试题
并发控制
cas
CompareAndSwap的简写,比较并交换。cas操作包含3个重要信息:内存位置,预期原值和新值。如果内存位置的值和预期的原值相等,才可以把该位置的值更新为新值,否则不做任何修改。
保证线程同步的,或者说在并发时保证数据一致性的。
ReentrantLock是通过cas实现的,但是悲观锁。
缺点:
aba问题
cas容易造成aba问题,是指线程拿到了最初预期的值a,但在进行cas时,被其它线程抢占了cpu执行权,值从a变到了b,然后其它线程又抢到了cpu,把b变为了a,其实此时的a已经不是原来的a了,但最初的线程并不知道,误以为它从未被修改过,只对比了预期原值a和现在的a(a是个对象,没有重写equals(),比较的是内存地址一样,但属性已经不同了),造成aba问题。
jdk1.5提供了AtomicStampedReference类可以解决aba问题,此类维护了一个版本号“Stamp”,每次比较时不止比较当前值,还要比较版本号。
读写锁(共享、排他锁)
共享锁=读锁,写锁=排他锁。针对是否阻塞的维度,会影响系统的并发。
读锁是共享的(不发生阻塞),多个客户可在同一时刻同时读取同一个资源,互不影响。
写锁是排他的(会发生阻塞其它的写锁和读锁),
表锁、行锁
针对锁的颗粒度,锁定的数据范围,也会影响系统的并发。锁定的资源越小,只要互相不发生冲突,并发程度越高。
加锁涉及资源开销,如获得锁,检查锁是否已解除,释放锁等。如果系统涉及到大量时间管理锁,系统的性能可能会受到影响。
- 表锁
是一种开销最小的策略。会锁定整张表,一个用户对表进行写操作(增删改,修改表字段等),需要先获得写锁,会阻塞其它用户对该表的所有读写操作,没有写锁时,其它用户才能获得读锁,读锁之间相互不阻塞。alter table 命令会触发表锁,而忽略存储引擎的锁机制。
- 行锁
由存储引擎自己实现,可以最大程度支持并发(但带来了最大的锁开销),InnDB实现了行级锁。
悲、乐观锁
悲观锁
定义:主观认为对同一数据的并发操作一定会发生修改,采取加锁的方式防止数据错乱,不加锁一定会出问题。Java的Synchronized和ReentrantLock都是悲观锁思想的实现。
- java的悲观锁
java 1.6之前synchronized 是重量级锁,Locl的实现类ReentrantLock的lock()方法就是在加锁,unlock()执行解锁。处理资源前必须先加锁并拿到锁,处理完再解锁。
- mysql的悲观锁
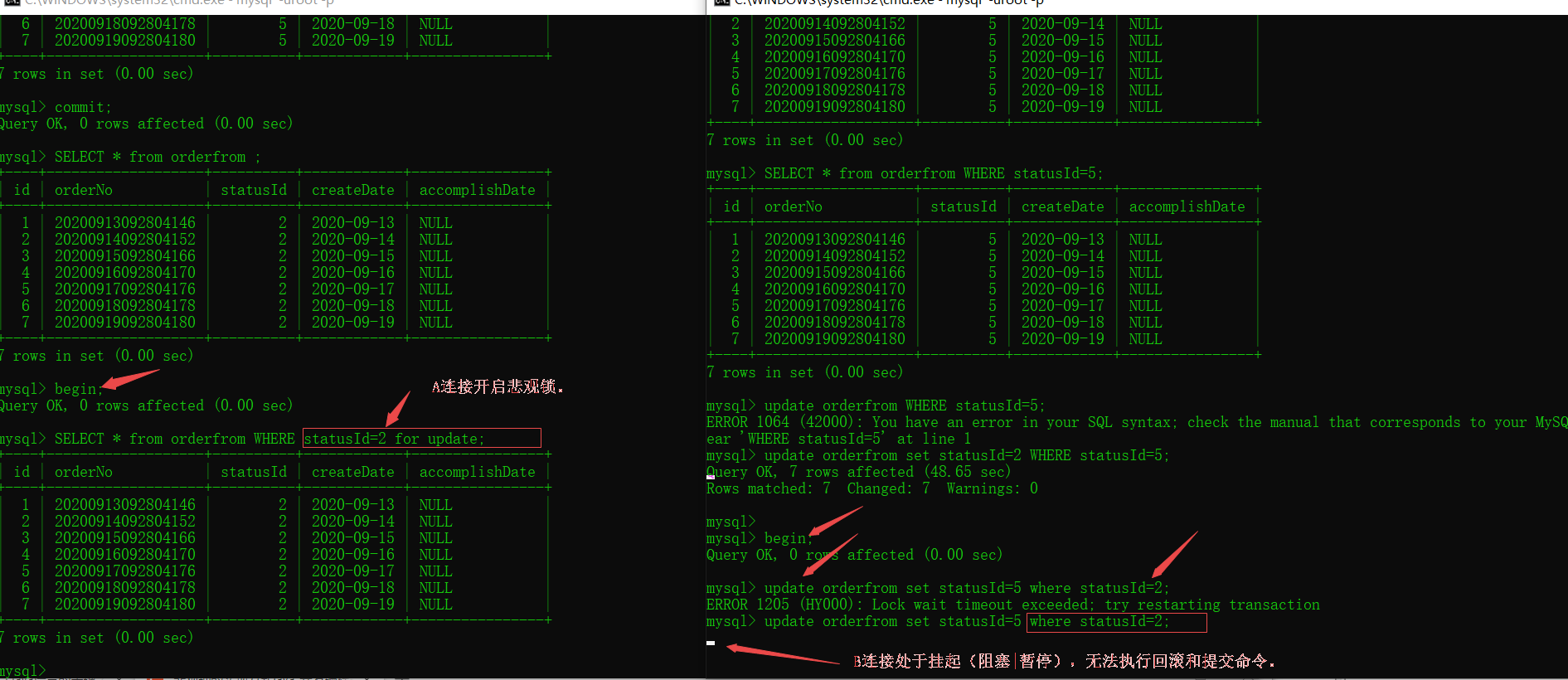
mysql可用select for update语法,即是悲观锁,在提交前不允许其它客户端连接修改数据。这样会降低并发性能。
发现的现象,连接A执行了悲观锁查询,B连接想修改A查询符合条件的行时,B无论是否手动开启事务,B都会被挂起(暂停),处于阻塞,无法回滚,会停在那里直到A释放锁后,B才能提交或回滚。
乐观锁
刚好相反,这种思想不担心并发操作时数据被修改错误,,每次获取数据也不会加锁,只在更新数据时,判断现有数据和原有数据是否一致,来判断数据是否已经被其它线程修改,如果没被其它线程修改则进行更新,如被修改则不修改,Java的Lock是乐观锁。
- java的乐观锁
Java原子类AtomicInteger 在更新数据时,使用了乐观锁思想,多线程可同时操作同一个原子变量。
- mysql的乐观锁
mysql可添加一个字段version来实现,在修改某行数据前先查出改行,修改时判断version值是否和查询出的值相同,如果一致就更新成功,不一致说明其它用户先修改了这条数据,可以选择重新获取数据,重新判断,然后尝试再次更新该数据。
| 优点 | 缺点 | 适用场景 | |
|---|---|---|---|
| 乐观锁 | 避免了长事务对其它并发事务的阻塞等待,提高并发量,提升性能 | 往往需要设计存储逻辑,如果一直拿不到锁,或并发量很大,竞争激烈,导致不停重试,消耗的资源可能会超过悲观锁 | 适用于读多,改少的场景,或者读多,并发不高,这些场景能最大的发挥不加锁的性能优势。 |
| 悲观锁 | 大多数情况依靠锁机制实现,保证最大程度的独占性,DB性能的大量开销,特别对长事务 | 一开始就加锁,增加了开销,高并发时大量其它线程或客户阻塞。 | 适合高并发写多,临界区代码复杂,可避免乐观锁的大量无用反复重试 |
查询sql
查询
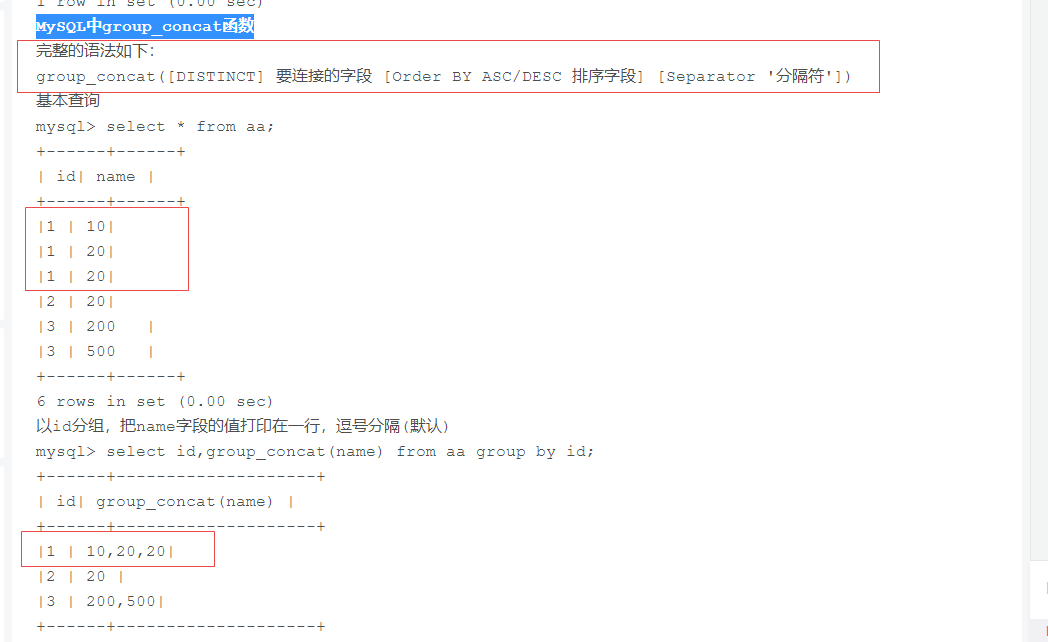
行专列
MySQL中group_concat函数
case when
1:n 查用户的多个账户里是否有某种类型
客户表
| 字段 | 注释 |
|---|---|
| cust_id | |
| name | 姓名 |
账户表
| 字段 | 注释 |
|---|---|
| id | 主键 |
| cust_id | 客户表主键 |
| product_cd | 账号类型 |
select c.cust_id,c.name,
case
when exists (select 1 from account a where a.cust_id = c.cust_id and a.product_cd='chk')
then '有'
else '无'
end '是否有支票账户',
case
when exists (select 1 from account a where a.cust_id = c.cust_id and a.product_cd='sav')
then '有'
else '无'
end '是否有储蓄账户'
from customer c;
统计各单位各部门的男女员工数,没输入员工的单位、部门也要统计,显示信息:单位名,部门名,男员工数,女员工数,并按单位和部门排序
emp
| 字段 | 注释 |
|---|---|
| id | |
| org_id | 单位id |
| dept_id | 部门id |
| sextype | 性别:1-男,2-女 |
dept
| 字段 | 注释 |
|---|---|
| id | |
| name | 部门名 |
org
| 字段 | 注释 |
|---|---|
| id | |
| name | 单位名 |
SELECT
d.name depName,
o.name orgName,
count(e2.id) total,
SUM(case when e2.sextype=1 then 1 ELSE 0 END)'男人數',
SUM(case when e2.sextype=2 then 1 ELSE 0 END)'女人數'
from
(
SELECT
e.id,
IFNULL(e.org_id,0) org_id,
IFNULL(e.dept_id,0) dept_id,
sextype
FROM
emp e
) e2
LEFT JOIN
org o ON e2.org_id = o.id
LEFT JOIN
dept d ON d.id = e2.dept_id
GROUP BY d.name,o.name

 浙公网安备 33010602011771号
浙公网安备 33010602011771号