
卷积过程中的矩阵尺寸:
(W(原尺寸)-w(卷积核尺寸)+1)/S(步长) no padding 向上取整
(W(原尺寸))/S(步长) padding
池化中的矩阵尺寸:
(W(原尺寸)-w(卷积核尺寸)+1)/S(步长) no padding
(W(原尺寸))/S(步长) padding
ReLU:
卷积核:
卷积核中的数值是深度学习自动学习的
用户时需指定卷积的尺寸和数量
对同一层图像(神经元),卷积神经网络是共享卷积核的,即共享权值
softmax 激活函数 :
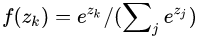
在算相同一层的神经元之间有联系![]() ,激活后输出值相加等于1。
,激活后输出值相加等于1。
损失函数:计算预测值和真实值之间的误差
一般先激活再计算损失
softmax loss 损失函数公式为:L=-log(Ot)

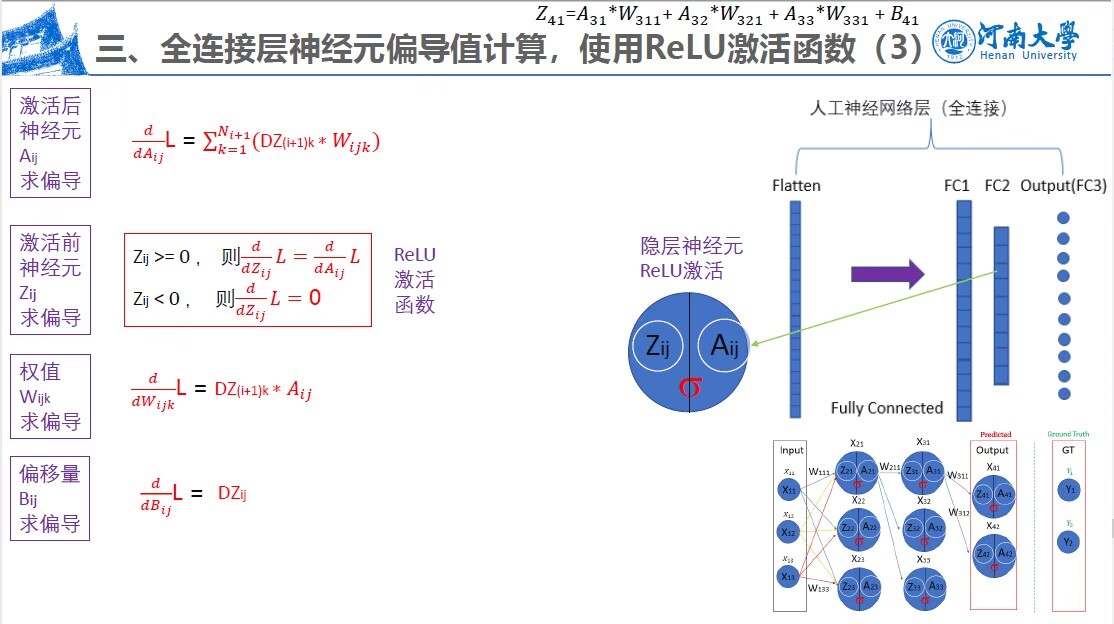


求导顺序从后往前,从输出层到人工神经网络层到卷积神经网络层
1. 定义总的损失函数公式,如Softmax Loss
2. 对于输出层,每个激活后的神经元(即预测值),求其相对于总损失的偏导值;
3. 对于输出层,每个激活前的神经元,求其相对于损失的偏导值;Softmax激活函数
4. 对于全连接层的每个神经元,分别求其激活后和激活前的偏导值,及每个连接的权值;使用ReLU激活
5. 对于池化层,对池化前的卷积层的神经元求偏导值;使用ReLU激活
6. 对于卷积层,对卷积前的矩阵中的神经元求偏导值,求卷积核中的权值的偏导值;使用ReLU激活
PS:若步骤4的全连接层,步骤5的池化层和步骤6的卷积操作有多组,则分别重复执行。
知识产权声明: 本博文中的ppt素材及相关内容和知识产权,均属于河南大学张重生老师所讲授的《深度学习》课程及张重生老师在2025年出版的著作《新一代人工智能 从深度学习到大模型》(机械工业出版社)。特此声明。
真挚地感谢张重生老师在本人于河南大学学习期间的教导。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号