Privacy-preserving logistic regression论文分析报告
小组成员:郑爽、王妮婷、王静雯
一、背景
机器学习的隐私保护研究大致分为2条主线: 以多方安全计算、同态加密为代表的加密方法和以差分隐私为代表的扰动方法。与加密方法相比,差分隐私机制更易于在实际场景中部署和应用。
二、论文简介
该论文的目标是弥合密码学和信息安全社区中的方法与数据挖掘社区中的方法之间的差距。 这是必要的,因为要在协议的隐私和尊重协议的功能的可学习性之间进行权衡。 在论文中,作者介绍了Dwork等人提出的用于在隐私模型中学习的算法。差分隐私模型通过观察从包含该值的数据库中学习到的功能来限制可以从中获得多少有关特定私有价值的信息。此设置中的初始肯定结果取决于函数的敏感度,即函数值由于一个输入的任意更改而发生改变的最大值。使用此方法需要限制要学习的函数类的敏感度,然后添加与灵敏度成正比的噪声。
该论文的贡献主要体现在以下三点。
- 作者将基于敏感度的设计隐私保护算法的方法应用于特定的机器学习算法,即逻辑回归。
- 作者提出了第二种保护隐私的逻辑回归算法。第二种算法基于求解扰动的目标函数,而不依赖于灵敏度。
- 作者证明了新方法在差分隐私模型中是私有的。最后,作者提供了实验来证明论文中的新方法的卓越学习性能。
三、方法简介
1、 敏感度
对于函数f:X → Y,xi∈X和r∈X为特征向量。当且仅当输入数据中任意一条数据改变时,其输出结果变化的最大值称为该函数的敏感度,形式化定义为:
S(f)= max |f(x1,…,xn-1,r) – f(x1,…,xn-1,r’)|
差分隐私机制是目前机器学习的隐私保护研究中最常采用的方法之一。由于模型训练过程往往需要多次访问敏感数据集,如数据预处理、计算损失函数、梯度下降求解最优参数等,故必须将整个训练过程的全局隐私损失控制在尽可能小的范围内。对于简单模型,此要求较容易实现。然而,对结构复杂、参 数量大的深度学习模型而言,将难以平衡模型可用性与隐私保护效果,这是该技术面临的最大问题与挑战。
2、差分隐私模型
与加密方法相比,差分隐私机制更易于在实际场景中部署和应用,根据数据处理与分析能力的不同,机器学习模型可分为以线性回归、逻辑回归、支持向量机等基于统计学习理论的传统机器学习方法,和以各类神经网络模型为代表的深度学习方法。
对于传统机器学习,根据经验风险最小化得到的最优模型往往与决策边界附近的某些训练样本密切相关(如SVM 中的支持向量)。若这些样本的集合被增加、删除或修改,将会导致模型完全改变,在这种情况下,训练样本的信息将很 容易被推测出来
3、一种简单的算法

算法的思想:通过对输入得出的输出结果加上一个噪声来实现隐私保护。
存在的问题:算法的性能随着λ的减小而降低,特别是当λ很小时,性能较差。问题是能否获得逻辑回归的隐私保护近似值,对于较小的λ具有更好的性能界限?为了探索这个问题,文中提出了一种不同的算法。
4、 改进后的算法

算法的思想:改进后的算法用一个正则化常量λ替代原本添加噪声的算法,由于正则化本来是用于防止模型的过拟合,在该算法中用来降低函数的敏感度达到隐私保护的作用。算法基于求解一个扰动目标函数,不依赖于敏感度。
四、实验
论文中提供了一些模拟方法来比较这两种隐私保护方法,并证明使用论文中的隐私保护方法进行逻辑回归不会像标准逻辑回归那样严重降低学习性能,但是性能下降是不可避免的。为了解决隐私问题,作者为学习的分类器或目标添加噪音。

图1给出了在17,500个点上的交叉验证中测试误差的平均值和标准偏差。
在两种模拟中,作文中的新方法都优于灵敏度方法,尽管会导致错误比标准逻辑回归要大。对于这两个问题,论文中对10,000个保留点集进行了交叉验证,从而对逻辑回归参数λ进行了调整,以最大程度地减少标准logistic回归的测试误差。由于每种隐私保护算法都是随机算法,因此通过平均200多次随机重启来评估每种隐私保护算法的性能。
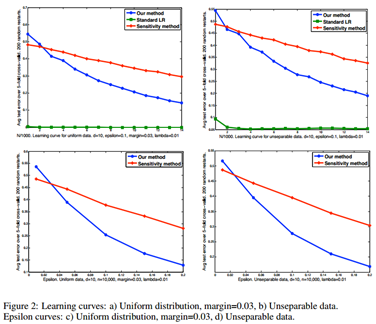
在图2的a和b中,论文提供了学习曲线。图2绘制了每增加1000点后的测试误差,这些误差是交叉验证的平均值。学习曲线表明,新方法不仅比灵敏度方法具有更低的最终误差,而且在大多数较小的训练集大小下也具有更好的性能。
为了观察隐私级别对保留隐私的学习算法的学习性能的影响,在图2的c和d中,根据关于差分隐私模型的定义,新方法在管理隐私和学习性能之间的权衡方面具有优势。
五、总结
论文中展示了通过逻辑回归构建隐私保护线性分类器的两种方法。第一个是基于以往算法的一个方法,第二个是一种新算法。使用Dwork等人的差分隐私模型定义,论文证明了新算法可以保护隐私。并且论文为这两种算法提供了学习性能保证,这在通常会应用逻辑回归的情况下对新算法更为严格。 在仿真中,论文中的新算法优于以往的方法。
论文还揭示了正则化和隐私之间的有趣关系:正则化常数越大,逻辑回归函数对任何一个单独的示例的敏感度就越低,因此为使其保持隐私而需要添加的噪声也越少。所以正规化不仅可以防止过度拟合,而且还有助于保护隐私。
参考文献
[1] 邹鸿珍. 基于差分隐私的回归分析算法研究[D]. 2016.
[2] 周大力. 基于Laplace机制的差分隐私回归分析相关优化研究[D].
[3] 葛宇航. 基于差分隐私的线性回归分析[J]. 科技经济导刊, 2019, 27(14):163-164.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号