

HDFS的存储原理
一、冗余数据保存的问题
因HDFS把底层架构在非常廉价的机器集群上,则有一个致命缺陷,会不断出故障。
故需要冗余存储。
一般1个数据块会默认保存3块,也可自定义(伪分布式只能是1)。
冗余存储的好处:
-
1、加快数据的传输速度
假如有3个机器要同时访问一个数据,若没有冗余存储,则需排队访问;冗余存储后,则可以分别访问不同的数据块
-
2、很容易检查错误
因冗余存储可互相参照比对
-
3、保存数据可靠性
假如有3个副本,有副本出现故障,被系统检测到后,会自动去从其他副本复制恢复
二、数据保存策略的问题
假设一个块来了以后,要备份3个副本,如何存放: 若数据来自集群内的节点,则第一份副本会放在上传文件的该节点上; 若数据来自集群外部,HDFS会随机的挑选一台磁盘不太满、cpu不太忙的节点存放第一副本;
第二副本会存放在和第一副本不同的机架上;
第三副本存放在和第一副本相同的机架不同的节点上;
后续副本随机存放
三、数据读取策略
就近原则,客户端可通过API获取所有数据存放的对应节点和客户端自己所在的机架ID,若机架ID和自己相同则从该节点获取,否则随机选择一个读取。
HDFS提供了一个API 可以确定一个数据节点所属机架ID,客户端也可调用API获取自己所属的机架ID。当客户端读取数据时,从名称节点获得数据块所有副本的存放位置列表,列表中包含副本所在的数据节点,可调用API来确定客户端和这些节点的机架ID,当发现某个副本机架ID和该客户端的机架ID相同时,优选选择该副本读取数据;如果没有,则随机选择一个副本读取数据。
四、数据的错误与恢复
HDFS可能有几千个节点,一般会有机器出现故障。可能出现的问题:
-
名称节点出错:
-
hadoop1.0中,名称节点会暂停服务一段时间,从第二名称节点恢复FsImage和Editlog数据,恢复后则重新开始服务(因第二名称节点平时会从名称节点冷备份数据)
-
hadoop2.0后,因第二名称节点从名称节点热备份数据,会立即恢复使用
-
-
数据节点出错
-
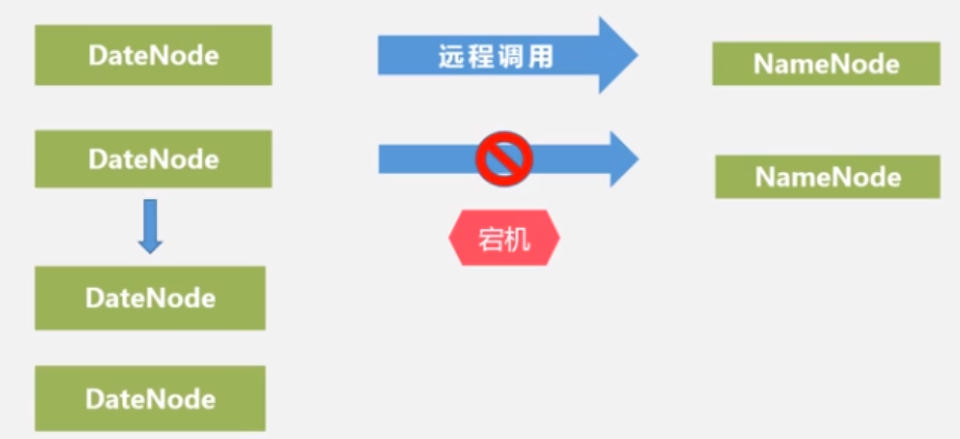
如何知道datanode出现问题:因在整个运行期间,datanode会定期远程调用向namenode发送心跳信息;一旦namenode接收不到某个datanode的信息,则表示其发生故障;namenode会在其列表里把该datanode的状态标记为宕机,并把保存在该节点上的所有数据,从其他备份节点中复制到其他正常运行的节点上
![]()
-
hdfs与其他分布式文件系统有一个最大的区别,hdfs可以调整冗余数据的位置,当一个节点出现故障或者负载不均衡时,可把该机器的数据块调整到另一机器上
-
-
数据出错
数据块存储到不同的磁盘上,会遇到磁盘损坏的情况,导致数据出错。
-
发现数据出错的机制:校验码。客户端读取后,会对数据进行校验码校验,如果发现校验码不对,则说明数据出现问题。
-
校验码是在文件创建时,客户端每写入一个文件都会为数据块生成一个校验码并把它保存在同一个文件目录下,下次读取数据时,会一起读取数据块和校验码,然后对数据块进行校验码计算,然后将该校验码和读取的校验码进行比较,若不同,说明数据出现错误,需进行数据恢复和再复制。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号