


MySQL性能调优与架构设计——第 17 章 高可用设计之思路及方案
第 17 章 高可用设计之思路及方案
前言:
数据库系统是一个应用系统的核心部分,要想系统整体可用性得到保证,数据库系统就不能出现任何问题。对于一个企业级的系统来说,数据库系统的可用性尤为重要。数据库系统一旦出现问题无法提供服务,所有系统都可能无法继续工作,而不像软件中部分系统出现问题可能影响的仅仅只是某个功能无法继续服务。所以,一个成功的数据库架构在高可用设计方面也是需要充分考虑的。本章内容将针对如何构建一个高可用的 MySQL 数据库系统来介绍各种解决方案以及方案之间的比较。
17.1 利用 Replication 来实现高可用架构
做维护的读者朋友应该都清楚,任何设备(或服务),只要是单点,就存在着很大的安全隐患。因为一旦这台设备(或服务) crash 之后,在短时间内就很难有备用设备(或服务)来顶替其功能。所以稍微重要一些的服务器或者应用系统,都会存在至少一个备份以供出现异常的时候能够很快的顶替上来提供服务。
对于数据库来说,主备配置是非常常见的设计思路。而对于 MySQL 来说,可以说天生就具备了实现该功能的优势,因为其 Replication 功能在实际应用中被广泛的用来实现主备配置的功能。
我想,在大家所接触的 MySQL 环境中大多数都存在通过 MySQL Replication 来实现两台(或者多台)MySQL Server 之间的数据库复制功能吧。可能有些是为了增强系统扩展性,满足性能要求实现读写分离。亦或者就是用来作为主备机的设计,保证当主机 crash 之后在很短的时间内就可以将应用切换到备机上面来继续运行。
通过 MySQL Replication 来实现数据库的复制实际上在前面第13章中的内容中已经做过详细的介绍了,也介绍了多种 Replication 架构的实现原理及实现方法。在之前,主要是从扩展性方面来介绍 Replication。在这里,我将主要介绍的是从系统高可用方面如何和利用 Replication 的多种架构实现解决高可靠性的问题。
17.1.1 常规的 Master - Slave 解决基本的主备设计
在之前的章节中我提到过,普通的 Master - Slave 架构是目前很多系统中使用最为常见的一种架构方式。该架构设计不仅仅在很大程度上解决的系统的扩展性问题,带来性能的提升,同时在系统可靠性方面也提供了一定的保证。
在普通的一个 Master 后面复制一个或者多个 Slave 的架构设计中,当我们的某一台Slave 出现故障不能提供服务之后,我们还有至少一台 MySQL 服务器(Master)可以提供服务,不至于所有和数据库相关的业务都不能运行下去。如果 Slave 超过一台,那么剩下的 Slave 也仍然能够不受任何干扰的继续提供服务。
当然,这里有一点在设计的时候是需要注意的,那就是我们的 MySQL 数据库集群整体的服务能力要至少能够保证当其缺少一台 MySQL Server 之后还能够支撑系统的负载,否则一切都是空谈。不过,从系统设计角度来说,系统处理能力留有一定的剩余空间是一个比较基本的要求。所以正常来说,系统中短时间内少一台 MySQL Server 应该是仍然能够支撑正常业务的。 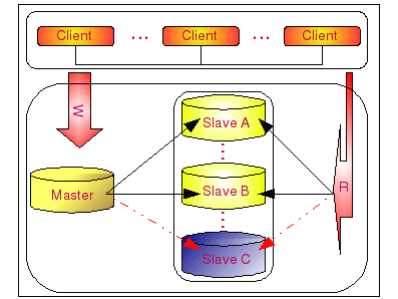
如上图所示,当我们的 Slave 集群中的一台 Slave C 出现故障 crash 之后,整个系统的变化仅仅只是从 Master 至 Slave C 的复制中断,客户端应用的 Read 请求也不能再访问 Slave C。当时其他所有的 MySQL Server 在不需要任何调整的情况下就能正常工作。客户端的请求 Read 请求全部由 Slave A 和 Slave B 来承担。
17.1.2 Master 单点问题的解决
上面的架构可以很容易的解决 Slave 出现故障的情况,而且不需要进行任何调整就能继续提供服务。但是,当我们的 Master 出现问题后呢?当我们的 Master 出现问题之后所有客户端的 Write 请求就都无法处理了。
这时候我们可以有如下两种解决方案,一个是将 Slave 中的某一台切换成 Master 对外提供服务,同时将其他所有的 Slave 都以通过 CHANGE MASTER 命令来将通过新的Master 进行复制。另一个方案就是新增一台 Master,也就是 Dual Master 的解决方案。
我们先来看看第一种解决方案,将一台 Slave 切换成 Master 来解决问题,如图: 
当 Master 出现故障 crash 之后,原客户端对 Master 的所有 Write 请求都会无法再继续进行下去了,所有原 Master 到 Slave 的复制也自然就断掉了。这时候,我们选择一台 Slave 将其切换成 Master。假设选择的是 Slave A,则我们将其他 Slave B 和 Slave C都通过 CHANGE MASTER TO 命令更换其 Master,从新的 Master 也就是原Slave A 开始继续进行复制。同时将应用端所有的写入请求转向到新的 Master。对于 Read 请求,我们可以去掉对新 Master 的 Read 请求,也可以继续保留。
这种方案最大的一个弊端就是切换步骤比较多,实现比较复杂。而且,在 Master 出现故障 crash 的那个时刻,我们的所有 Slave 的复制进度并不一定完全一致,有可能有少量的差异。这时候,选择哪一个 Slave 作为 Master也是一个比较头疼的问题。所以这个方案的可控性并不是特别的高。
我们再来看看第二种解决方案,也就是通过 Dual Master 来解决 Master 的点问,为了简单明了,这里就仅画出 Master 部分的图,如下: 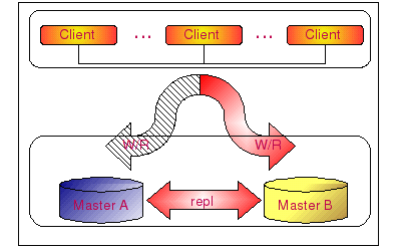
我们通过两台 MySQL Server 搭建成 Dual Master 环境,正常情况下,所有客户端的Write 请求都写往 Master A,然后通过 Replication 将 Master A 复制到 Master B。一旦 Master A 出现问题之后,所有的 Write 请求都转向 Master B。而在正常情况下,当Master B 出现问题的时候,实际上不论是数据库还是客户端的请求,都不会受到实质性的影响。
这里,可能有读者朋友会想到,当我们的 Master A 出现问题的时候,应用如何做到自动将请求转向到 Master B 呢?其实很简单,我们只需要通过相应的硬件设备如F5或者Cluster 管理软件如 Heartbeat 来设置一个 VIP,正常情况下该 VIP 指向 Master A,而一旦 Master A出现异常 crash 之后,则自动切换指向到 Master B,前端所的应用都通过这个 VIP 来访问 Master。这样,既解决了应用的 IP 切换问题,还保证了在任何时刻应用都只会见到一台 Master,避免了多点写入出现数据紊乱的可能。
这个方案最大的特点就是在 Master 出现故障之后的处理比较简单,可控性比较大。而弊端就是需要增加一台 MySQL 服务器,在成本方面投入更大。
17.1.3 Dual Master 与级联复制结合解决异常故障下的高可用
通过前面的架构分析,我们分别得到了 Slave 出现故障后的解决方案,也解决了Master 的单点问题。现在我们再通过 Dual Master 与级联复制结合的架构,来得到一个整体的解决方案,解决系统整体可靠性的问题。
这个架构方案的介绍在之前的章节中已经详细的描述过了,这里我们主要分析一下处于高可靠性方面考虑的完善和异常切换方法。 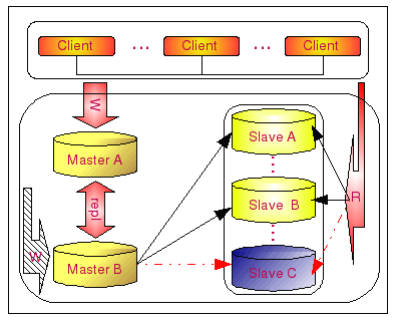
如上图所示,首先考虑 Slave 出现异常的情况。在这个架构中,Slave 出现异常后的处理情况和普通的 Master - Slave 架构的处理方式完全一样,仅仅需要在应用访问 Slave集群的访问配置中去掉一个 Slave 节点即可解决,不论是通过应用程序自己判断,还是通过硬件解决方案如 F5 都可以很容易的实现。
下面我们再看看当 Master A 出现故障 crash 之后的处理方案。如下图:
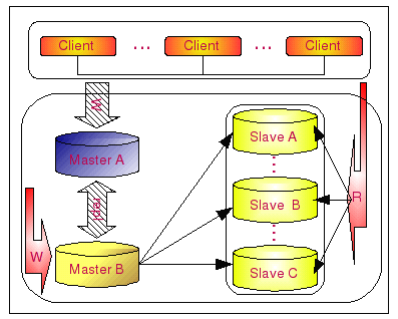
当 Master A 出现故障 crash 之后,Master A 与 Master B 之间的复制将中断,所有客户端向 Master A 的 Write 请求都必须转向 Master B。这个转向动作的实现,可以通过上一节中所介绍的第二中方案中所介绍的通过 VIP 的方式实现。由于之前所有的 Slave 就都是从 Master B 来实现复制,所以 Slave 集群不会受到任何的影响,客户端的所有 Read 请求也就不会受到任何的影响,整个过程可以完全自动进行,不需要任何的人为干预。不过
这里有一个隐患就是当 Master A crash 的时候如果 Master B 作为 Slave 的 IO 线程如果还没有读取完 Master A 的二进制日志的话,就会出现数据丢失的问题。要完全解决这个问题,我们只能通过第三方 patch(google 开发)来镜像 MySQL 的二进制日志到 Master B上面,才能完全避免不丢失任何数据。
那么当 Master B 出现故障crash 之后的情况又如何呢?如下图所示: 
如果出现故障的不是 Master B 而是 Master A 又会怎样呢?首先可以确定的是我们的所有 Write 请求都不会受到任何影响,而且所有的 Read 请求也都还是能够正常访问。
但所有 Slave 的复制都会中断,Slave 上面的数据会开始出现滞后的现象。这时候我们需要做的就是将所有的 Slave 进行 CHANGE MASTER TO 操作,改为从 Master A 进行复制。
由于所有 Slave 的复制都不可能超前最初的数据源,所以可以根据 Slave 上面的 Relay Log 中的时间戳信息与 Master A 中的时间戳信息进行对照来找到准确的复制起始点,不会造成任何的数据丢失。
17.1.4 Dual Master 与级联复制结合解决在线 DDL 变更问题
当我们使用 Dual Master 加级联复制的组合架构的时候,对于 MySQL 的一个致命伤也就是在线 DDL 变更来说,也可以得到一定的解决。如当我们需要给某个表 tab 增加一个字段,可以通过如下在上述架构中来实现:
1、在 Slave 集群中抽出一台暂时停止提供服务,然后对其进行变更,完成后再放回集群继续提供服务;
2、重复第一步的操作完成所有 Slave 的变更;
3、暂停 Master B 的复制,同时关闭当前 session 记录二进制日志的功能,对其进行变更,完成后再启动复制;
4、通过 VIP 切换,将应用所有对 Master A 的请求切换至 Master B;
5、关闭 Master A 当前 session 记录二进制日志的功能,然后进行变更;
6、最后再将 VIP 从 Master B 切换回 Master A,至此,所有变更完成。
变更过程中有几点需要注意的:
1、整个 Slave 集群需要能够承受在少一台 MySQL 的时候仍然能够支撑所有业务;
2、Slave 集群中增加或者减少一台 MySQL 的操作简单,可通过在线调整应用配置来实现;
3、Dual Master 之间的 VIP 切换简单,且切换时间较短,因为这个切换过程会造成短时间段内应用无法访问 Master 数据库。
4、在变更 Master B 的时候,会出现短时间段内 Slave 集群数据的延时,所以如果单台主机的变更时间较长的话,需要在业务量较低的凌晨进行变更。如果有必要,甚至可能需要变更 Master B 之前将所有 Slave 切换为以 Master B 作为Master。
当然,即使是这样,由于存在 Master A 与 Master B 之间的 VIP 切换,我们仍然会出现短时间段内应用无法进行写入操作的情况。所以说,这种方案也仅仅能够在一定程度上面解决 MySQL 在线 DDL 的问题。而且当集群数量较多,而且每个集群的节点也较多的情况下,整个操作过程将会非常的复杂也很漫长。对于 MySQL 在线 DDL 的问题,目前也确实还没有一个非常完美的解决方案,只能期待 MySQL 能够在后续版本中尽快解决这个问题了。
17.2 利用 MySQL Cluster 实现整体高可用
在上一章中已经详细介绍过 MySQL Cluster 的相关特性,以及安装配置维护方面的内容。这里,主要是介绍一下如何利用 MySQL Cluster 的特性来提高我们系统的整体可用性。由于 MySQL Cluster 本身就是一个完整的分布式架构的系统,而且支持数据的多点冗余存放,数据实时同步等特性。所以可以说他天生就已经具备了实现高可靠性的条件了,是否能够在实际应用中满足要求,主要就是在系统搭建配置方面的合理设置了。
由于 MySQL Cluster 的架构主要由两个层次两组集群来组成,包括 SQL 节点(mysqld)和NDB 节点(数据节点),所有两个层次都需要能够保证高可靠性才能保证整体的可靠性。
下面我们从两个方面分别来介绍 MySQL Cluster 的高可靠性。
17.2.1 SQL 节点的高可靠性保证
MySQL Cluster 中的 SQL 节点实际上就是一个多节点的 mysqld 服务,并不包含任何数据。所以,SQL 节点集群就像其他任何普通的应用服务器一样,可替代性很高,只要安装了支持 MySQL Cluster 的 MySQL Server 端即可。
当该集群中的一个 SQL 节点 crash 掉之后,由于只是单纯的应用服务,所以并不会造成任何的数据丢失。只需要前端的应用数据源配置兼容了集群中某台主机 crash 之后自动将该主机从集群中去除就可以了。实际上,这一点对于应用服务器来说是非常容易做到的,无论是通过自行开发判断功能的代理还是通过硬件级别的负载均衡设备,都可以非常容易做到。当然,前提自然也是剩下的 SQL 节点能够承担整体负载才行。 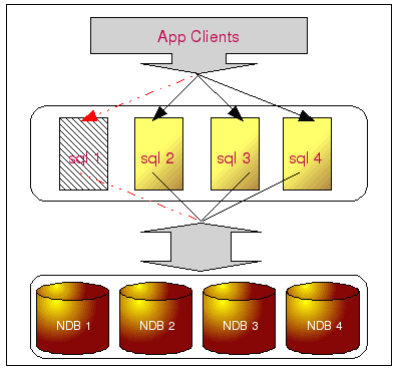
如上图,当 SQL 1 crash 之后,实际上仅仅只是访问到数据的很多条途径中的某一条中断了,实际上仍然还有很多条途径可以获取到所需要的数据。而且,由于 SQL 的可替代性很高,所以更换也非常简单,即使更换整台主机,也可以在短时间内完成。
17.2.2 NDB 节点的高可靠性保证
MySQL Cluster 的数据冗余是有一个前提条件的,首先必须要保证有足够的节点,实际上是至少需要2个节点才能保证数据有冗余,因为,MySQL Cluster 在保存冗余数据的时候,是比需要确保同一份数据的冗余存储在不同的节点之上。在保证了冗余的前提下,MySQL Cluster 才会将数据进行分区。
假设我们存在4个 NDB 节点,数据被分成4 个partition 存放,数据冗余存储,每份数据存储2份,也就是说 NDB 配置中的 NoOfReplicas 参数设置为 2,4个节点将被分成2个 NDB Group。
所有数据的分布类似于下图所示:
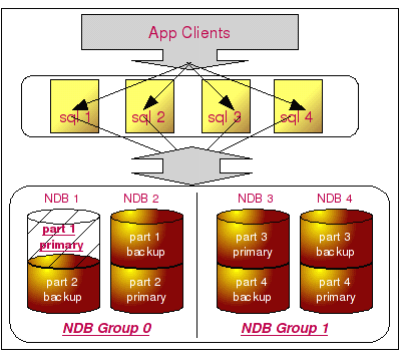
在这样的配置中,假设我们 NDB Group 0 这一组中的某一个 NDB 节点(假如是 NDB 1) 出现问题,其中的部分数据(假设是 part 1)坏了,由于每一份数据都存在一个冗余拷贝, 所以并不会对系统造成任何的影响,甚至完全不需要人为的操作,MySQL 就可以继续正常的提供服务。
假如我们两个节点上面都出现部分数据损坏的情况,结果会怎样?如下图:
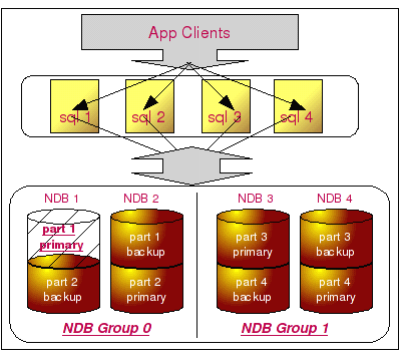
如果像上图所示,如果两个损坏部分数据的节点属于同一个 NDB Group,只要损坏部分并没有包含完全相同的数据,整个 MySQL Cluster 仍然可以正常提供服务。但是,如果损坏数据中存在相同的数据,即使只有很少的部分,都会造成 MySQL Cluster出现问题,不能完全正常的提供服务。此外,如果损坏数据的节点处于两个不同的 NDB Group,那么非常幸运,不管损坏的是哪一部分数据,都不会影响 MySQL Cluster 的正常服务。
可能有读者朋友会说,那假如我们的硬件出现故障,整个 NDB 都crash 了呢?是的,确实很可能存在这样的问题,不过我们同样不用担心,如图所示:
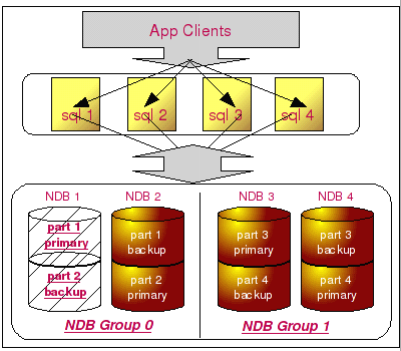
假设我们整个 NDB 节点由于硬件(或者软件)故障而 crash 之后,由于 MySQL Cluster 保证了每份数据的拷贝都不在同一台主机上,所以即使整太主机都 crash 了之后,MySQL Cluster 仍然能够正常提供服务,就像上图所示的那样,即使整个 NDB 1 节点都 crash 了,每一份数据都还可以通过 NDB 2 节点找回。
那如果是同时 crash 两个节点会是什么结果?首先可以肯定的是假如我们 crash 的两个节点处于同一个 NDB Group 中的话,那 MySQL Cluster 也没有办法了,因为两份冗余的数据都丢失了。但是只要 crash 的两个节点不在同一个 NDB Group 中,MySQL Cluster 就不会受到任何影响,还是能够继续提供正常服务。如下图所示的情况:
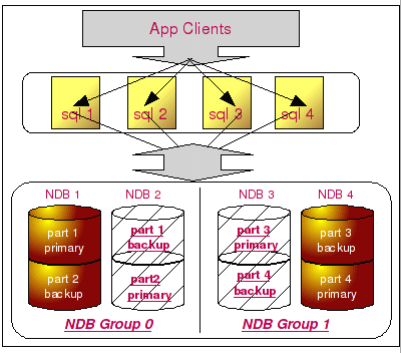
从上面所列举的情况我们可以知道,MySQL Cluster 确实可以达到非常高的可靠性,毕竟同一时刻存放相同数据的两个 NDB 节点都出现大故障的概率实在是太小了,要是这也能够被遇上,那只能自然倒霉了。
当然,由于 MySQL Cluster 之前的老版本需要将所有的数据全部 Load 到内存中才能正常运行,所有由于受到内存空间大小的限制,使用的人非常少。现在的新版本虽然已经支持仅仅只需要所有的索引数据 Load 到内存中即可,但是由于实际的成功案例还并不是很多,而且发展时间也还不是太长,所以很多用户朋友对于 MySQL Cluster 目前还是持谨慎态度,大部分还处于测试阶段。
17.3 利用 DRBD 保证数据的高安全可靠
17.3.1 DRBD 介绍
对于很多多这朋友来说,DRBD 的使用可能还不是太熟悉,但多多少少可能有一些了解。 毕竟,在 MySQL 的官方文档手册的 High Availability and Scalability 这一章中将 DRBD 作为 MySQL 实现高可用性的一个非常重要的方式来介绍的。虽然这一内容是直到去年年中的时候才开始加入到 MySQL 的文档手册中,但是 DRBD 本身在这之前很久就已经成为很多应用场合实现高可靠性的解决方案,而且在不少的 MySQL 使用群体中也早就开始使用了。
简单来说,DRBD 其实就是通过网络来实现块设备的数据镜像同步的一款开源 Cluster软件,也被俗称为网络 RAID1。官方英文介绍为:DRBD refers toblock devicesdesigned asa building block toform high availability (HA) clusters. This is done by mirroring a whole block device via an assigned network.It is shownas network raid-1- DRBD。下面是 DRBD 的一个概览图:
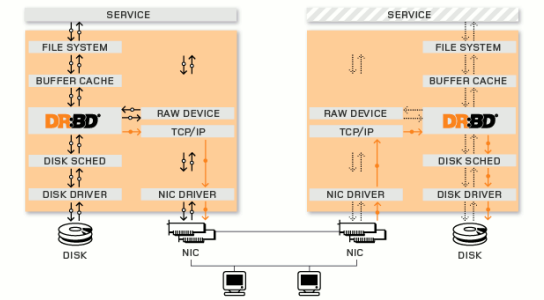
从图中我们可以看出,DRBD 介于文件系统与磁盘介质之间,通过捕获上层文件系统的所有IO操作,然后调用内核中的IO模块来读写底层的磁盘介质。当 DRBD 捕获到文件系统的写操作之后,会在进行本地的磁盘写操作的同时,以 TCP/IP 协议将,通过本地主机的网络设备(NIC)将 IO 传递至远程主机的网络设备。当远程主机的 DRBD 监听到传递过来的 IO 信息之后,会立即将该数据写入到该 DRBD 所维护的磁盘设备。至此,整个 IO 才做完成。
实际上 DRBD 在处理远程数据写入的时候有三种复制模式(或者称为级别)可以选择,不同的复制模式保证了远程数据写入的三种可靠性。三种级别的选择可以通过 DRBD 的通用配置部分的 protocal。不同的复制模式,实际上是影响了一个 IO 完成所代表的实际含义。
因为当我们使用 DRBD 的时候,一个 IO 完成的标识(DRBD 返回 IO 完成)是本地写入和远程写入这两个并发进程都返回完成标识。下面我来详细介绍一下这三种复制模式所代表的含义:
Protocol A:这种模式是可靠性最低的模式,而且是一个异步的模式。当我们使用这个模式来配置的时候,写远程数据的进程将数据通过 TCP/IP 协议发送进入本地主机的 TCP send buffer 中,即返回完成。
Protocol B:这种模式相对于 Protocol A 来说,可靠性要更高一些。因为写入远程的线程会等待网络信息传输完成,也就是数据已经被远程的 DRBD 接受到之后返回完成。
Protocol C:Protocol C 复制模式是真正完全的同步复制模式,只有当远程的 DRBD 将数据完全写入磁盘成功后,才会返回完成。
对比上面三种复制模式,C 模式可以保证不论出现任何异常,都能够保证两端数据的一1致性。而如果使用 B 模式,则可能当远程主机突然断电之后,将丢失部分还没有完全写入磁盘的信息,且本地与远程的数据出现一定的不一致情况。当我们使用 A 复制模式的话,可能存在的风险就要更大了。只要本地网络设备突然无法正常工作(包括主机断电),就会丢失将写入远程主机的数据,造成数据不一致现象。
由于不同模式所要求的远程写入进程返回完成信息的时机不一样,所以也直接决定了IO 写入的性能。通过三个模式的描述,我们可以很清楚的知道,IO 写入性能与可靠程度成反比。所以,各位读者朋友在考虑设置这个参数的时候,需要仔细评估各方面的影响,尽可能得到一个既满足实际场景的性能需求,又能满足对可靠性的要求。
DRBD 的安装部署以及相关的配置说明,在 MySQL 的官方文档手册以及我的个人网站博客(http://www.jianzhaoyang.com)中都有相关的描述,而且在 DRBD 的官方网站上面也可以找到最为全面的说明,所以这里就不再介绍了。下面我主要介绍一下 DRBD 的一些特殊的特性以及限制,以供大家参考。
17.3.2 DRBD 特性与限制
DRBD 之所以能够得到广泛的采用,甚至被 MySQL 官方写入文档手册作为官方推荐的高可用方案之一,主要是其各种高可靠特性以及稳定性的缘故。下面介绍一下 DRBD 所具备的一些比较重要的特性。
1、非常丰富的配置选项,可以适应我们的应用场景中的情况。无论是可靠性级别与性能的平衡,还是数据安全性方面,无论是本地磁盘,还是网络存储设备,无论是希望异常自动解决,还是希望手动控制等等,都可以通过简单的配置文件就可以解决。
当然,丰富的配置在带来极大的灵活性的同时,也要求使用者需要对他有足够的了解才行,否则在那么多配置参数中也很难决策该如何配置。幸好 DRBD 在默认情况下的各项参数实际上就已经满足了大多数典型需求了,并不需要我们每一项参数都设置才能运行;
2、对于节点之间出现数据不一致现象,DRBD 可以通过一定的规则,进行重新同步。而且可以通过相关参数配置让 DRBD 在固定时间点进行数据的校验比对,来确定数据是否一致,并对不一致的数据进行标记。同时还可以选择是 DRBD 自行解决不一致问题还是由我们手工决定如何同步;
3、在运行过程中如果出现异常导致一端 crash,并不会影响另一端的正常工作。出现异常之后的所有数据变更,都会被记录到相关的日志文件中。当 crash 节点正常恢复之后,可以自动同步这段时间变更过的数据。为了不影响新数据的正常同步,还可以设定恢复过程中的速度,以确保网络和其他设备不会出现性能问题;
4、多种文件系统类型的支持。DRBD 除了能够支持各种常规的文件系统之外,还可以支持 GFS,OCFS2 等分布式文件系统。而且,在使用分布式文件系统的时候,还可以实现各结带你同时提供所有 IO 操作。
5、提供对 LVM 的支持。DRBD 既可以使用由 LVM 提供的逻辑设备,也可以将自己对外提供的设备成为 LVM 的物理设备,这极大的方便的运维人员对存储设备的管理。
6、所有 IO 操作,能够绝对的保证 IO 顺序。这也是对于数据库来说非常重要的一个特性尤其是一些对数据一致性要求非常苛刻的数据库软件来说。
7、可以支持多种传输协议,从 DRBD 8.2.7 开始,DRBD 开始支持 Ipv4,IPv6以及SuperSockets来进行数据传输。
8、支持 Three-Way 复制。从 DRBD 8.3.0 开始,DRBD 可以支持三个节点之间的复制了,有点类似于级联复制的特性。
当然,DRBD 在拥有大量让人青睐的特性的同时,也存在一定的限制,下面就是 DRBD 目前存在的一些比较重要的限制:
1、对于使用常规文件系统(非分布式文件系统)的情况下,DRBD 只能支持单 Primary模式。在单 Primary 模式下,只有一个节点的数据是可以对外提供 IO 服务的。
只有当使用 GFS 或者 OCFS2 这样的分布式文件系统的时候,才能支持 Dual Primary 模式。
2、Sblit Brain 的解决。因为某些特殊的原因,造成两台主机之间的 DRBD 连接中断之后双方都以 Primary 角色来运行之后的处理还不是太稳定。虽然 DRBD 的配置文件中可以配置自动解决 Split Brain,但是从我之前的测试情况来看,并不是每次的解决都非常令人满意,在有些情况下,可能出现某个节点完全失效的可能。
3、复制节点数目的限制,即使是目前最新的 DRBD 版本来说,也最多只支持三个节点之间的复制。
以上几个限制是在目前看来可能对使用者造成较大影响的几个限制。当然,DRBD 还存在很多其他方面的限制,大家在决定使用之前,还是需要经过足够测试了解,以确保不会造成上线后的困扰。
17.4 其他高可用设计方案
除了上面几种高可用方案之外,其实还有不少方案可以供大家选择,如RaiDB,共享存储解(SAN 或者 NAS) 等等。
对于 RaiDB,可能很多读者朋友还比较陌生,其全称为 Redundant Arrays of Inexpensive Databases。也就是通过 Raid 理念来管理数据库的数据。所以 RaiDB 也存在数据库 Sharding 的概念。和磁盘 Raid 一样,RaiDB 也存在多种 Raid,如 RaiDB-0,RaiDB-1,RaiDB-2,RaiDB-0-1 和 RaiDB-1-0 等。商业 MySQL 数据库解决方案提供商 Continuent 的数据库解决方案中,就利用了 RaiDB 的概念。大家可以通过一下几张图片清晰的了解RaiDB 的各种 Raid 模式。
RaiDB-0: 
RaiDB-1:
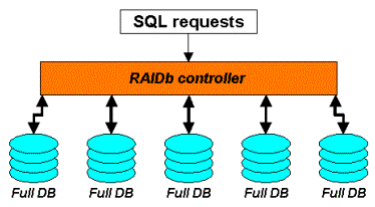
RaiDB-2:
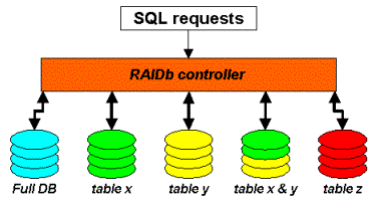
RaiDB-0-1:
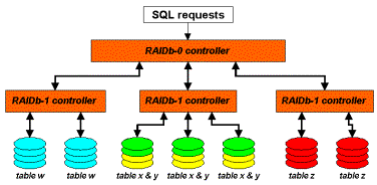
RaiDB-1-0: 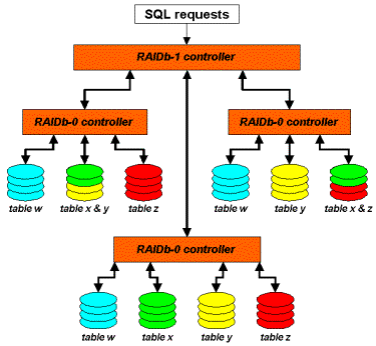
从图中的标识,大家应该就比较清楚 RaiDB 各种Raid 模式下的数据如何分布以及工作方式了吧。至于为什么这样作可以保证高可用性,就和磁盘通过 Raid 来保证数据高可靠性一样。当然,要真正理解,前提还是大家已经具备了清晰的 Raid 概念。
而对于共享存储的解决方案,则是一个相对来说比较昂贵的解决方案了。运行 MySQL Server 的主机上面并不存放数据,只不过通过共享协议(FC 或者 NFS)来将远程存储设备上面的磁盘空间 Mount 到本地,当作本地磁盘来使用。
为什么共享存储的解决方案可以满足高可靠性要求呢?首先,数据不是存在 MySQL Server 本地主机上面,所以当本地 MySQL Server 主机出现任何故障,都不会造成数据的丢失,完全可以通过其他主机来找回存储设备上面的数据。其次,无论是通过通过 SAN 还是 NAS 来作为共享存储,存储本身具备多种高可用解决方案,可以做到完全不丢失任何数据。甚至即使 MySQL Server 与共享存储之间的连接通道,也有很多成熟的高可用解决方案,来保证连接的高可用性。由于共享存储的解决方案本身违背了我个人提倡的通过 MySQL 构建廉价的企业级高性能高可靠性方案,又考虑到篇幅问题,所以这里就不详细深入介绍了。
如果读者朋友对这方面比较感兴趣,可以通过其他图书再深入了解 SAN 存储以及 NAS 存储相关的知识。
17.5 各种高可用方案的利弊比较
从前面各种高可用设计方案的介绍中读者们可能已经发现,不管是哪一种方案,都存在自己独特的优势,但也都或多或少的存在一些限制。其实这也是很正常的,毕竟任何事物都不可能是完美的,我们只能充分利用各自的优势来解决自己的问题,而不是希望依赖某种方案一劳永逸的解决所有问题。这一节将针对上面的几种主要方案做一个利弊分析,以供大家选择过程中参考。
1、MySQL Replication
优势:部署简单,实施方便,维护也不复杂,是 MySQL 天生就支持的功能。且主备机之间切换方便,可以通过第三方软件或者自行编写简单的脚本即可自动完成主备切换。
劣势:如果 Master 主机硬件故障且无法恢复,则可能造成部分未传送到 Slave 端的数据丢失;
2、MySQL Cluster
优势:可用性非常高,性能非常好。每一分数据至少在不同主机上面存在一份拷贝,且冗余数据拷贝实时同步。
劣势:维护较为复杂,产品还比较新,存在部分bug,目前还不一定适用于比较核心的线上系统。
3、DRBD 磁盘网络镜像方案
优势:软件功能强大,数据在底层快设备级别跨物理主机镜像,且可根据性能和可靠性要求配置不同级别的同步。IO 操作保持顺序,可满足数据库对数据一致性的苛刻要求。
劣势:非分布式文件系统环境无法支持镜像数据同时可见,性能和可靠性两者相互矛盾,无法适用于性能和可靠性要求都比较苛刻的环境。维护成本高于 MySQL Replication。
17.6 小结
本章重点针对 MySQL 自身具备的两种高可用解决方案以及 MySQL 官方推荐的 DRBD 解决方案做了较为详细的介绍,同时包括了各解决方案的利弊对比。希望这些信息能够给各位读者带来一些帮助。不过,MySQL 的高可用解决方案远远不只上面介绍过的集中方案,还存在着大量的其他方案可供各位读者朋友进行研究探索。开源的力量是巨大的,开源贡献者的力量更是无穷的。
摘自:《MySQL性能调优与架构设计》简朝阳
转载请注明出处:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号