[Converge] Activation Function - Exploding and Vanishing Gradients
Ref: https://www.zhihu.com/question/66027838
感觉非常值得一读!
如何选择合适的激活函数?
-
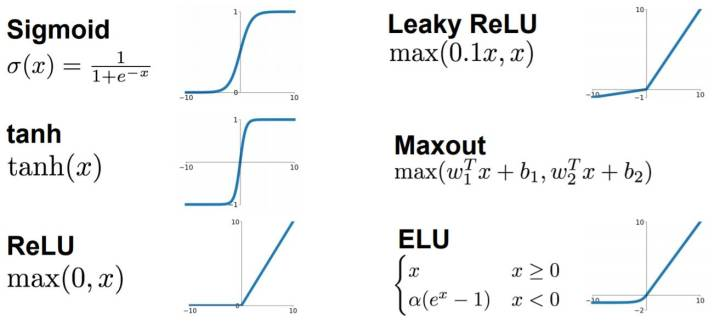
选手对比
Ref:26种神经网络激活函数可视化
- Use ReLU. Be careful with your learning rates
- Try out Leaky ReLU / Maxout / ELU
- Try out tanh but don’t expect much
- Don’t use sigmoid
这个问题目前没有确定的方法,凭一些经验吧。
1)深度学习往往需要大量时间来处理大量数据,模型的收敛速度是尤为重要的。所以,总体上来讲,训练深度学习网络尽量使用zero-centered数据 (可以经过数据预处理实现) 和zero-centered输出。所以要尽量选择输出具有zero-centered特点的激活函数以加快模型的收敛速度。
2)如果使用 ReLU,那么一定要小心设置 learning rate,而且要注意不要让网络出现很多 “dead” 神经元,如果这个问题不好解决,那么可以试试 Leaky ReLU、PReLU 或者 Maxout.
3)最好不要用 sigmoid,你可以试试 tanh,不过可以预期它的效果会比不上 ReLU 和 Maxout.
-
大一统:Maxout
maxout 是通过分段线性函数来拟合所有可能的凸函数来作为激活函数的,但是由于线性函数是可学习,所以实际上是可以学出来的激活函数。具体操作是对所有线性取最大,也就是把若干直线的交点作为分段的界,然后每一段取最大。
maxout 可以看成是relu家族的一个推广。
缺点在于增加了参数量。
"非线性激活函数" 的必要性
Goto: 常见的激活函数(sigmoid、tanh、relu) [可视化非常好]
如果使用线性激活函数(恒等激励函数),那么神经网络仅是将输入线性组合再输出,在这种情况下,深层(多个隐藏层)神经网络与只有一个隐藏层的神经网络没有任何区别,不如去掉多个隐藏层。
证明如下:
如上公式,两层使用线性激活函数的神经网络,可以简化成单层的神经网络,对于多个隐藏层的神经网络同样如此。因此,想要使神经网络的多个隐藏层有意义,需要使用非线性激活函数,也就是说想要神经网络学习到有意思的东西只能使用非线性激活函数。
/* conintue */

 浙公网安备 33010602011771号
浙公网安备 33010602011771号