[DETR] End-to-End Object Detection with Transformers
过去的方式并非端到端,例如还需要nms对一堆boundingbox做后处理。但,detr 终于做到了端到端!
[Submitted on 26 May 2020 (v1), last revised 28 May 2020 (this version, v3)],注意,在ViT早几个月发表,说明两者没有借鉴关系。
End-to-End Object Detection with Transformers
[Submitted on 8 Oct 2020 (v1), last revised 18 Mar 2021 (this version, v4)]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
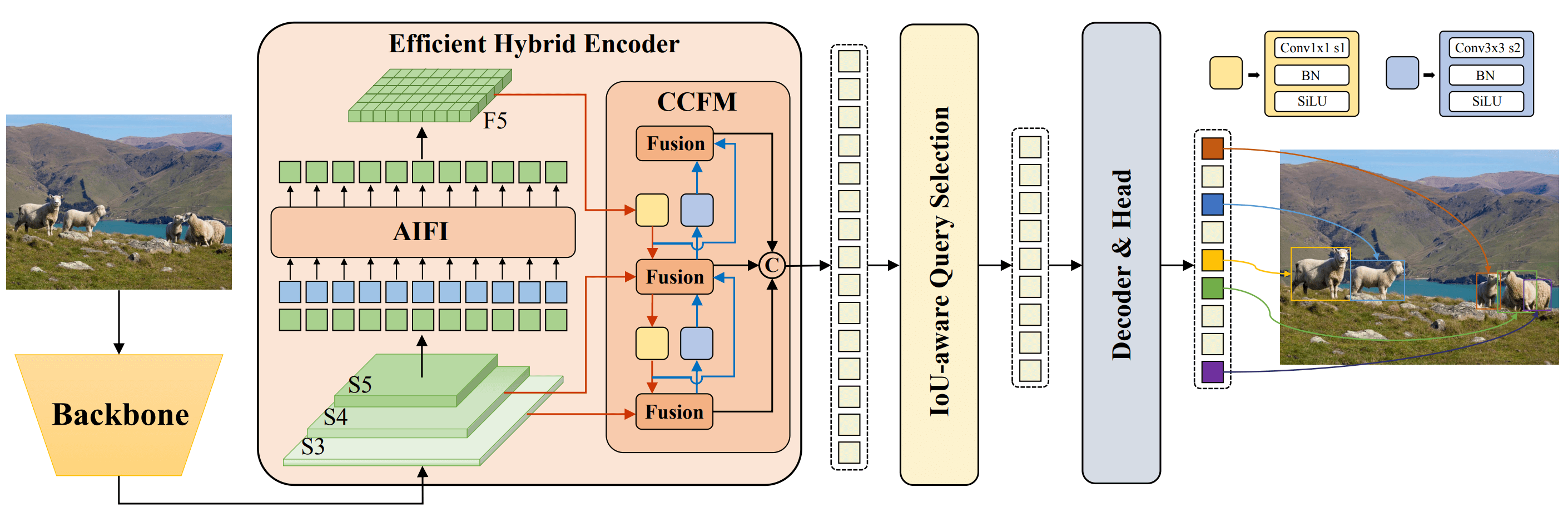
Baidu's RT-DETR: A Vision Transformer-Based Real-Time Object Detector
开始精读
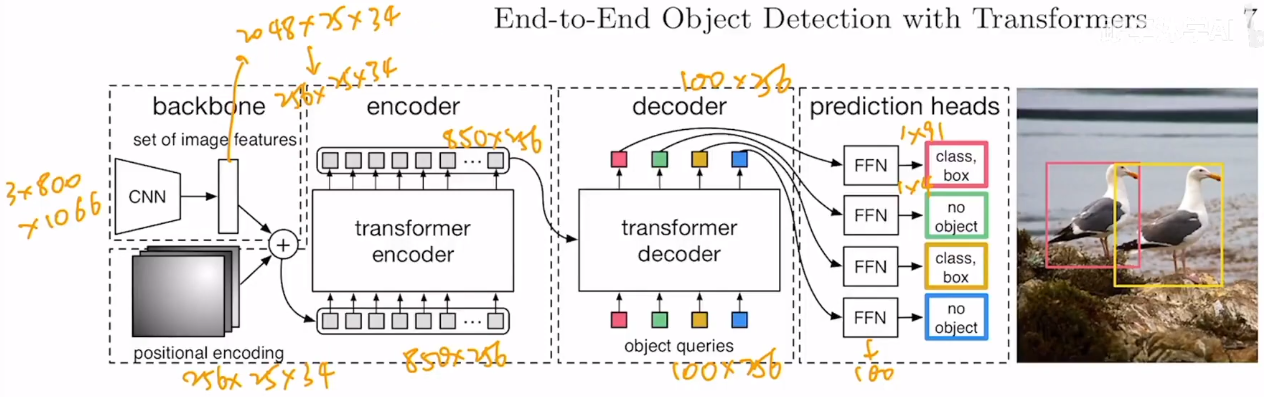
Anchor没了,成了 learned object queries。一股脑出所有最终版本的bounding boxes。
还能扩展到segmentation。
A large set of proposals, anchors, or window centers。
postprocessing。

预测框与gt框对比计算loss。如上图,只有两个框,有object就是前景物体;其他的就是“没object”,定义为背景物体。
初代detr对小目标不太友好。不到半年,Deformable DETR 解决了该问题,同时加快了训练过程。
每次有固定的N predictions。
以下是详细的推理过程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号